If you’ve ever spent a week trying to get two open-source tools to talk to each other, only to end up in a Kafka deserialization hell with events that appear in the UI but refuse to process, you might be living the exact nightmare this story is about.
A recent post from a frustrated data engineer on the r/dataengineering subreddit captures something painfully familiar: the gap between observability tooling’s marketing promises and its actual production readiness. The user needed to integrate Airflow pipelines, running PythonOperator and custom ClickHouse operators, with OpenMetadata for lineage tracking. The result? Dependency conflicts so deep they couldn’t use the backend lineage integration, and a Kafka-driven OpenLineage approach where events showed up in the UI but “OpenMetadata doesn’t actually process them correctly.”
This isn’t just one unlucky engineer’s problem. It’s a signal about where the entire open-source observability ecosystem still falls short.
The Kafka Event Mirage: When the UI Lies to You
The most insidious part of this bug is how it manifests. The events appear in the OpenMetadata UI. The pipeline emits them. Kafka transports them. The UI renders them. But the catalog never actually processes or indexes them.
One community member diagnosed the issue with surgical precision: this isn’t a Kafka config problem. It’s a schema registry mismatch or an OpenLineage event envelope deserialization issue. Specifically, the version of the openlineage-airflow package you’re running may be emitting a spec version that your version of OpenMetadata doesn’t fully understand.
The user tried OpenMetadata versions 1.12.8 and 1.13.0rc, paired with openlineage-airflow versions 2.6.0 and 2.10.1. None of these combinations worked. That’s not a fluke, that’s a sign that the spec coverage between the two projects isn’t aligned, and the edge cases around custom operators (like those custom ClickHouse operators) live in the gaps.

This diagram captures the gap between what your observability tool claims to do (spectrum from source discovery to governance) and what lineage alone delivers (just the tracking layer). The more features you want from a catalog, the more integration points you need.
Dependency Hell: The Silent Integration Killer
The user initially tried OpenMetadata’s backend lineage integration, the “official” path, and hit dependency hell. This is the other side of the open-source coin that nobody talks about in conference keynotes.
Modern data stacks are built from dozens of packages, each with their own pinned dependencies. Airflow itself is notorious for this: its provider model means you can have 98 official providers and 1,602 modules, each potentially conflicting with each other. Drop OpenMetadata’s SDK into that environment, and you’re now managing a constraints file that reads like a hostage negotiation.
This ties directly into broader metadata chaos and fragmentation challenges. The problem isn’t just that OpenMetadata has dependencies, it’s that any platform trying to unify metadata across a heterogeneous stack has to install itself into every environment it monitors. That’s a fundamental architectural tension. The catalog wants to be everywhere. The runtime wants to be stable. Those two goals fight each other at install time.
The Version Matrix Problem
Let’s be concrete about what’s happening here. The user’s situation maps to a version compatibility matrix that looks like this:
| OpenMetadata Version | openlineage-airflow Version | Airflow Version | Result |
|---|---|---|---|
| 1.12.8 / 1.13.0rc | 2.6.0 | 2.10.5+ | Events appear in UI, not processed |
| 1.12.8 / 1.13.0rc | 2.10.1 | 2.10.5+ | Events appear in UI, not processed |
| Any | Backend lineage integration | Any | Dependency hell |
Three rows, zero working configurations. The user hasn’t found a single documented combo that works for their setup. And the kicker? A devrel from Collate (OpenMetadata’s commercial entity) acknowledged the issue in the comments and directed the user to the Slack channel, meaning this isn’t a known solved problem. It’s being debugged in real-time, in public, between a user and a support channel.
Why Custom Operators Break Everything
The user isn’t running standard SQL operators. Their pipelines use custom ClickHouse operators built on BaseOperator. This matters because lineage for custom operators depends on explicit instrumentation. When you extend BaseOperator, you inherit default lineage behavior, but the quality of that lineage depends on how well the operator’s execute method reports its input and output datasets.
Most custom operators don’t do this correctly. OpenLineage’s Python SDK provides hooks, but if the operator author didn’t call them, the emitted lineage event will be partial or empty. And if that partial event hits an OpenMetadata instance that expects a specific schema shape, it silently drops it.
This isn’t a bug in OpenMetadata. It’s a gap between the standard’s intention and the messy reality of production pipelines. The Airflow ecosystem complexity and discoverability problem means most teams building custom operators didn’t read the OpenLineage spec cover to cover. They just needed a ClickHouse operator that works.
The Deeper Problem: OpenMetadata’s Kafka Ingestion Maturity
OpenMetadata has strong Kafka support in theory. The co-creator of OpenMetadata was a PMC member for Kafka. But the Kafka ingestion pipeline has a specific weakness: it was built for structured, well-documented connectors, not for the ragged edge of OpenLineage events from custom Airflow operators.
The ingestion path works like this:
1. OpenLineage events emitted from Airflow operators
2. Published to a Kafka topic
3. OpenMetadata’s consumer reads from the topic
4. Events are deserialized and processed into the metadata graph
The failure occurs between steps 3 and 4. The consumer reads the message. It acknowledges it. But the deserialization fails silently, no error, no dead letter queue, no visible failure. Just events that enter the system and vanish.
This is the kind of bug that erodes trust in observability tooling. You can’t fix metadata problems you can’t see. And if the observability platform itself has silent failure modes for metadata ingestion, you’re building governance on quicksand.
The OpenLineage vs. Backend Integration Choice
The user tried two integration paths and both failed. This raises a strategic question: when should you push lineage from the orchestrator, and when should the catalog pull it from the backend?
OpenLineage (push model)
Events emitted at runtime, near real-time, captures exactly what happened. But requires compatible operator instrumentation and Kafka infrastructure. Fragile to version mismatches.
Backend lineage integration (pull model)
OpenMetadata directly queries Airflow’s metadata database for DAG runs and task instances. More reliable for basic lineage, but can’t capture column-level lineage or custom operator behavior. The user reported dependency hell here.
Direct metadata ingestion (alternative)
OpenMetadata can directly ingest metadata from ClickHouse through its own connector, capturing table schemas and relationships without going through Airflow at all. But this breaks the lineage chain: you see the tables, but not the pipelines that created them.
None of these approaches work perfectly for the user’s case. The cleanest solution would be a well-instrumented ClickHouse operator that emits proper OpenLineage events, running against a version-compatible OpenMetadata instance with robust Kafka deserialization error handling. That’s a lot of precondition satisfaction for what should be a standard integration.
What Production Readiness Actually Means
OpenMetadata is a promising project. It’s not production-ready for this specific integration pattern.
That’s not a dismissal, it’s a measure of where the ecosystem stands. The broader metadata chaos and fragmentation challenges are real, and open-source catalog projects are still converging on the right abstractions. DataHub, OpenMetadata’s primary competitor, has broader connector coverage and more mature enterprise auth, but shares the same fundamental challenge: metadata ingestion from heterogeneous pipelines is hard.
The question isn’t whether OpenMetadata will get there. The question is whether your compliance deadline can wait.
The Operational Reality Behind the Dashboard
One commenter on the thread offered a pragmatic workaround: use OpenMetadata’s ingestion images on ECS Fargate, triggered by Airflow at a fixed frequency. They scrape 15,000 Redshift tables every four hours. This works because it bypasses the OpenLineage Kafka path entirely, ingestion runs as an external process, not as an Airflow integration.
This is the pattern most teams end up adopting: don’t try to push lineage from the orchestrator. Instead, have the catalog pull metadata directly from each data source on a schedule. It’s batch-oriented, not real-time, but it’s reliable.
That reliability gap is the real story here. The push-based, event-driven lineage flow that everyone’s architecture diagrams show is aspirational. In practice, most production lineage is batch-scraped from source systems.
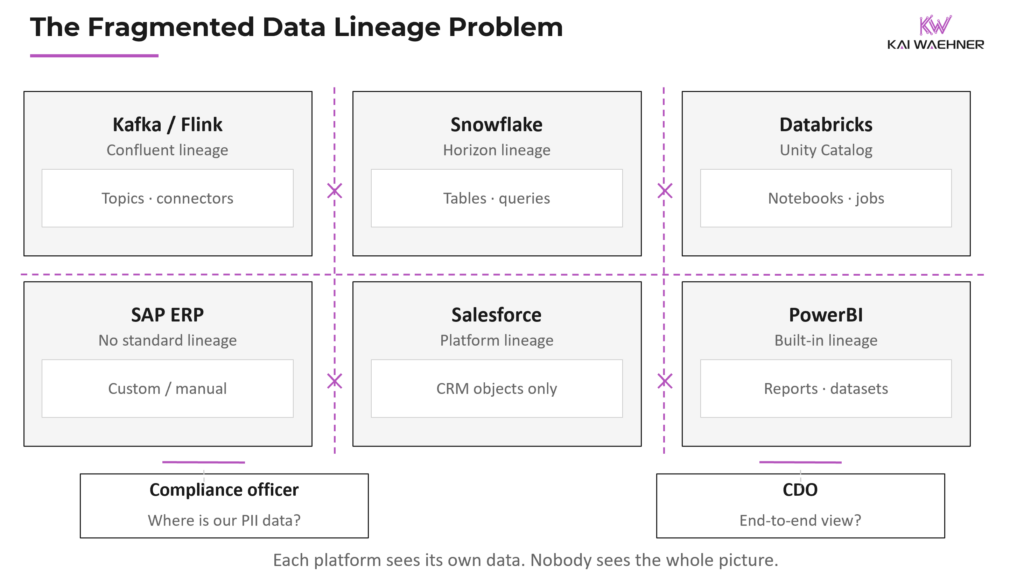
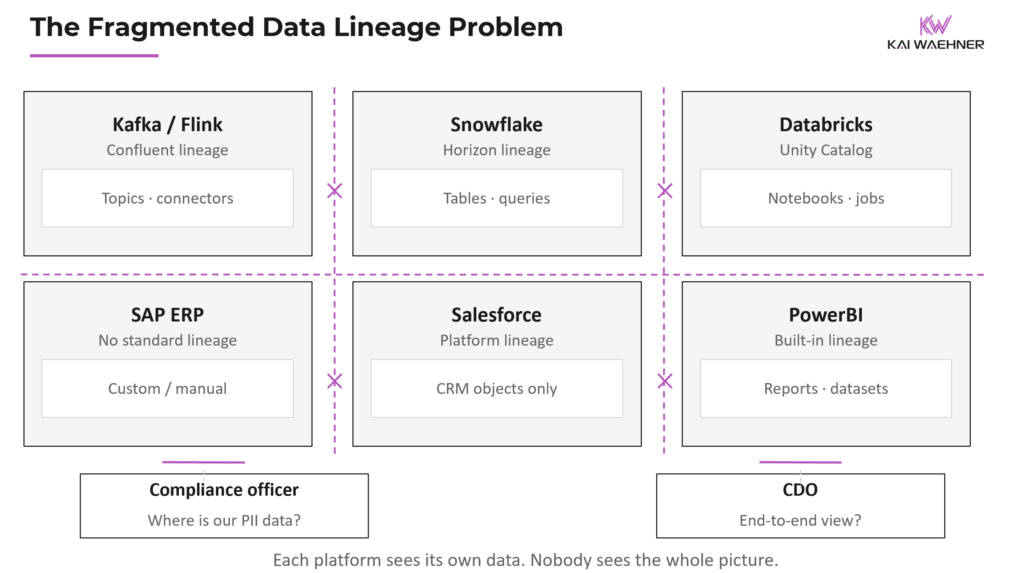
The Hidden Cost of Fragmentation
Every platform vendor offers lineage now. Confluent has lineage for Kafka topics and Flink jobs. Snowflake has Horizon. Databricks has Unity Catalog. Each works well within its boundaries. But an enterprise is never one platform. It’s Kafka plus Flink plus Snowflake plus ClickHouse plus Airflow plus custom applications.
The user’s problem is a microcosm of this fragmentation. They have ClickHouse tables that Airflow feeds. They want to see the full path: from Airflow task to ClickHouse table. That requires metadata to flow across tool boundaries. And across tool boundaries, the metadata standard is OpenLineage, but the implementations are inconsistent.
A platform-independent catalog like DataHub or OpenMetadata is the right architectural answer for large enterprises running heterogeneous stacks. But the integration costs of maintaining twelve independent connectors, each requiring its own version compatibility, authentication, and event parsing logic, makes independence expensive. For smaller organizations with a limited technology footprint, vendor-specific tools may remain the pragmatic choice, even with their blind spots.
Maturity Benchmarks the Hard Way
The user’s thread has a score of 9 with 5 comments. It’s not a viral post. But it represents a pattern I see regularly: an engineer hits a wall, asks the community, and gets “we’ll get you answered over on Slack” as the escalation path. That’s not a criticism of the devrel effort, it’s a statement about where the project’s documentation and testing coverage sits relative to real user needs.
For comparison, a production-grade integration would have:
– A compatibility matrix published for OM, openlineage-airflow, and Airflow versions
– An integration test suite that exercises custom operator lineage
– Visible error handling when OpenLineage events fail deserialization
– A dead letter queue or logging path for failed events
– Clear documentation for what versions work together
None of these exist for the Airflow-OpenMetadata Kafka path. The user is discovering the compatibility matrix by trial and error, in public, at their own velocity.
The Dependency Hell You Can’t Escape
The dependency conflation problem deserves its own autopsy. OpenMetadata’s Python SDK pulls in a wide tree of dependencies. Airflow’s provider model fights with those dependencies. Pip installs that work in isolation break in Airflow’s constrained environment.
There’s a structural solution here: containerize the ingestion. Run OpenMetadata ingestion in its own container, triggered by Airflow’s DockerOperator or KubernetesOperator. This avoids dependency conflicts entirely by keeping the ingestion environment separate from the Airflow environment. Many teams are quietly adopting this approach, but it requires additional infrastructure, a container registry, scheduling complexity, and operational overhead.
This is the exact scenario explored in [Airflow best practices vs. operational reality](/blog/airflow-best-practices-vs-reality-kubernetesoperator-pythonoperator). The recommended pattern (containerize everything) conflicts with the common practice (PythonOperator because it’s simpler). The tradeoff surfaces exactly when things break.
The Lineage Artifact Dilemma
At the core of this integration failure is a philosophical question: what is lineage for?
If lineage is a live debugging tool, showing you exactly what happened in that failed pipeline run, then push-based, real-time, event-level lineage is essential. The user needs to see that a specific PythonOperator task consumed from table A and wrote to table B at a specific timestamp.
If lineage is a governance artifact, supporting compliance audits, impact analysis, and data product definitions, then batch-scraped metadata that refreshes every few hours is sufficient. The compliance officer doesn’t need to know that a task failed at 3:42 PM. They need to know that, under normal operation, this pipeline feeds that table.
The user’s problem is that they need the live debugging use case and are running into tooling built primarily for the governance use case. OpenMetadata’s Kafka ingestion was designed to capture lineage at scale for governance. It wasn’t designed to give you per-task debugging fidelity for custom Airflow operators.
What the Community Response Reveals
The Reddit thread’s responses are illuminating. The Collate devrel immediately engaged and offered Slack support. Another commenter gave a precise technical diagnosis of the likely deserialization issue. A third shared their production workaround.
But none of them said “here’s the exact config that works.” Because nobody has found it yet. The collective wisdom of the community converges on diagnosis, not cure.
This is where open-source observability projects live today: enthusiastic community, responsive vendor support, but gaps in production hardening that force users to become integration engineers. The cost-benefit analysis of managed vs. custom orchestration becomes a real question when each integration takes days of debugging.
Recommendations for the Brave Engineer
If you’re in the same situation, here’s the practical advice the thread generates:
Option 1: Containerize ingestion. Run OpenMetadata metadata ingestion as a Docker container triggered by Airflow’s DockerOperator or use a separate scheduler (like the ECS Fargate approach). This avoids dependency hell entirely and gives you a clean environment for ingestion. It’s more infrastructure, but it’s less debugging.
Option 2: Use OpenMetadata’s native ClickHouse connector. Ingest ClickHouse metadata directly into OpenMetadata, separate from Airflow lineage. You’ll get table schemas and relationships, but not the pipeline-to-table connection. For compliance use cases, this may be sufficient. For operational debugging, it’s not.
Option 3: Wait for version convergence. The openlineage-airflow 2.6.0 and OM 1.13.0rc versions the user tried are bleeding edge. Sometimes the answer is to wait for a point release that aligns the spec implementations, then retest. Not satisfying, but pragmatic.
Option 4: Switch to DataHub. DataHub has native OpenLineage ingestion and broader connector coverage. It also has known working version combinations documented by the community. The migration cost may be worth the stability gain.
The Real Takeaway
The Airflow-OpenMetadata integration saga isn’t a story about bad software. It’s a story about the gap between architectural ideals and operational reality. Every toolchain promises seamless integration. Every integration has a version matrix, a dependency tree, and a set of edge cases that its test suite didn’t cover.
The projects will mature. The spec implementations will converge. The Kafka deserialization bugs will be fixed. But right now, if you need lineage from Airflow to ClickHouse and you’re not on a well-tested version combination, you’re a beta tester.
The question is whether your deadlines can afford to wait for the next release cycle.
This post is part of an ongoing investigation into data observability tooling maturity. If you’ve faced similar integration nightmares with Airflow, OpenMetadata, or any tool in the modern data stack, reach out or drop a comment below.