Multi-agent systems look elegant in diagrams. A neat sequence of boxes with arrows showing perfect handoffs between specialized agents. The reality, as anyone who has actually run one in production knows, is a different picture entirely. Retries, auth checks, serialization, state sync, latency between services, it all adds up surprisingly fast once workflows get bigger.
The phrase that kept coming back during a recent deep dive into production multi-agent workflows: “Every handoff between agents is a billing event in disguise.” It’s not hyperbolic. It’s accounting.
The Handoff Tax: What You’re Actually Paying For
The most deceptive aspect of multi-agent architecture is that the costs don’t show up in obvious places. You budget for LLM tokens. You budget for compute. You don’t budget for the five-second context-switching penalty every time Agent A hands off to Agent B across a system boundary.
Microsoft’s Copilot Studio documentation is refreshingly direct about this: “Separate agents introduce overhead to the system. There is a slightly longer execution time due to context switching, and complexity in maintaining multiple agents.” Notice the careful language. “Slightly longer” in a demo environment becomes “thirty to fifty percent of wall-clock latency” in production, as Anton Zagrebelny documented in his analysis of enterprise agent workflows.
The penalty breaks down into five distinct cost centers:
- Context serialization. When Agent A finishes its work, the entire conversational state, tool outputs, intermediate reasoning, user intent vectors, must be compressed, serialized, and transmitted to Agent B. This isn’t free. It burns tokens and wall-clock time proportional to the complexity of the state being passed.
- Network round-trips. Every handoff crosses at least one network boundary. In cloud deployments, that means crossing availability zones, regions, or the dreaded “my team deployed in us-east-1, your team deployed in eu-west-2” conversation that nobody wants to have at 2 AM.
- Auth handshakes. Each agent-to-agent handoff re-validates credentials. OAuth flows. Token refreshes. Permission checks. A workflow touching an ERP, a CRM, and a billing system authenticates three times before doing any actual work.
- Tool-call retries. Agents make mistakes. They call the wrong tool, pass malformed parameters, or hit rate limits. Each retry is a billing event that previously nobody authorized.
- State drift. The hidden killer. When workflows become asynchronous across services, the state that Agent A committed is not necessarily the state that Agent B sees. Coordination overhead becomes its own architecture problem.
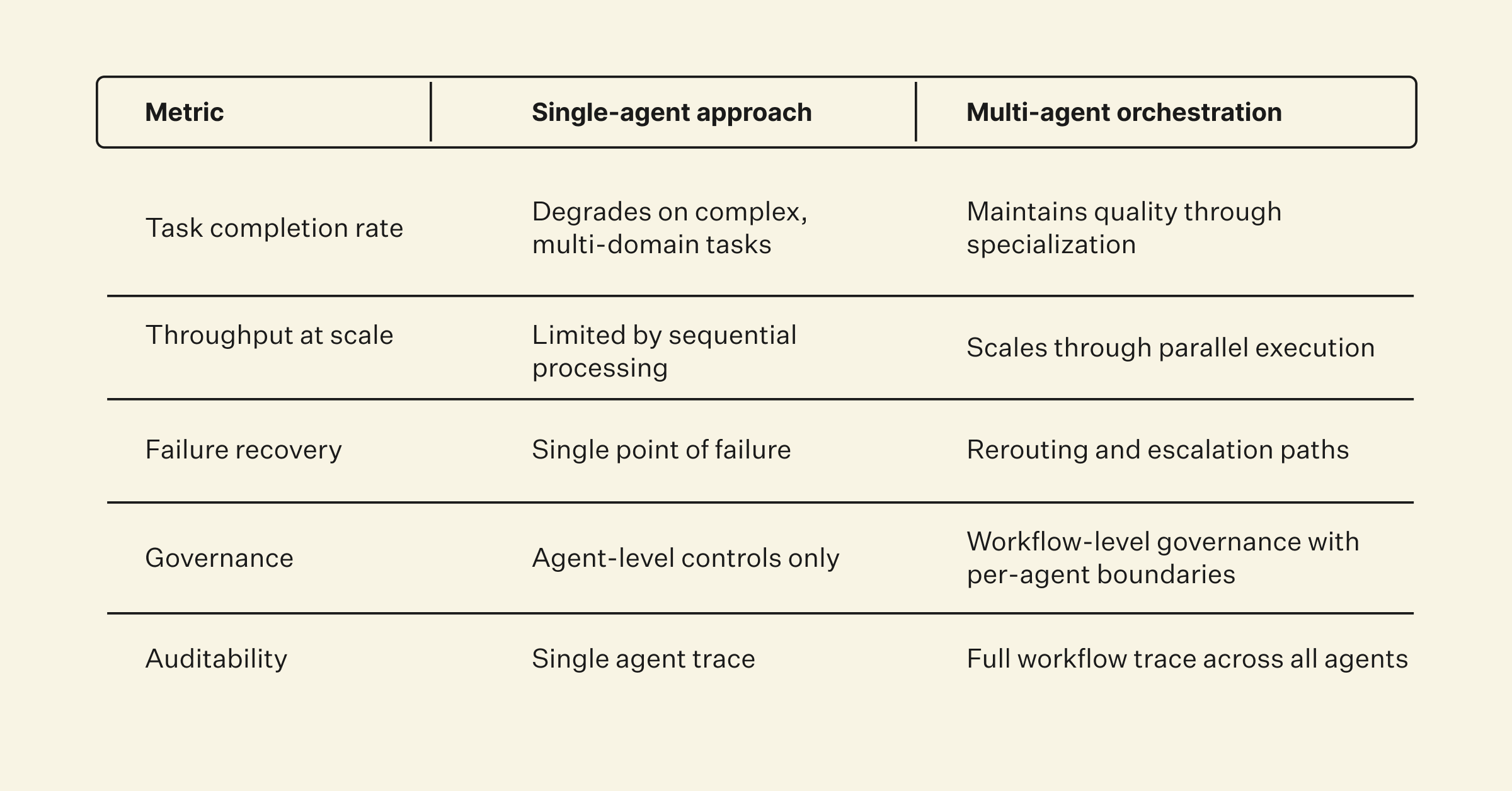
The 90% Gain Nobody Talks About
Anthropic published one of the most-shared engineering reads of 2025: “How we built our multi-agent research system.” The headline number was impressive, a multi-agent setup outperformed single-agent by 90.2% on internal research evals. What got quoted in every summary but absorbed by almost nobody was the asterisk: multi-agent uses about 15× more tokens than chat.
The lesson everyone took: multi-agent works. The lesson underneath: the gains are real only when somebody has done the engineering work to make the substrate underneath the agents not collapse.
That’s the same pattern playing out across the industry. McKinsey’s data shows that while 79% of organizations are experimenting with gen AI, fewer than 10% have scaled AI agents. The gap between “works in the lab” and “works at scale” is almost entirely an infrastructure gap. The agents themselves are fine. The boundaries between them are the actual product, and most teams shipped those boundaries as whatever the orchestration library defaulted to.
This is exactly the same dynamic that plays out in the hidden costs of event-driven architectures, the promise of “loose coupling” often defers complexity rather than eliminating it, and the bill arrives when you least expect it.
Why Your Metering Pipeline Is the Canary in the Coal Mine
Here’s where the billing analogy becomes concrete rather than metaphorical. The team at one of the largest AI providers in the world shared their architecture during an afternoon at Stripe Sessions. What they built wasn’t an AI decision. It was the same architecture that billing teams converged on between 2015 and 2020: in-region distributed caches with cross-region replication, globally distributed NoSQL document stores doing atomic credit-balance updates, and a homegrown metering pipeline they’d pulled back in-house after a vendor’s event-to-usage latency reached 15 to 30 minutes.
That latency window wasn’t just a UX problem. It opened a credit-fraud surface that became the forcing function for the rip-out.
The general principle: metering sits on the hot path at scale. The latency budget on the access decision is too tight for a vendor round-trip. Most companies that ship at frontier scale eventually own the metering layer. The right call today is to plan for owning it eventually, even if you’re vendoring now.
This is precisely the kind of accumulated middleware complexity as a parallel to agent handoff overhead that starts as a “simple” API bridge and slowly strangles your architecture over time.
The Five Decisions That Determine Whether This Scales
Strip away the model layer and the framework layer, and what’s left is a small set of architectural choices that determine whether any multi-agent system scales. Each one has a wrong answer that costs you a quarter to undo.
Where rate-limit state lives and how consistent it stays across regions. Cross-region writes carry a round-trip cost. The consistency model determines whether the same customer can over-spend in two regions before the first write propagates. Pick wrong and you either rate-limit too aggressively (paying customers feel friction) or undercount (revenue loss plus fraud surface).
Whether credit consumption is atomic with the access decision or settled async. Most teams that scale eventually land on a hybrid: the access decision is atomic against a soft balance in a fast store, while the durable ledger settles async. The migration from pure-atomic to hybrid is a quarter of work no matter how strong the team is.
Whether your meter hard-blocks or tolerates a small overdraft. Blocking a paying customer mid-prompt for pennies is worse for the relationship than absorbing the overdraft. That’s a real revenue-exposure decision made on purpose. If your meter hard-blocks today, that’s a choice too, but probably not one anyone on your team has made deliberately.
How entitlements are organized. Almost every team refactors entitlements from per-SKU checks into per-feature-by-plan, and frequently into per-customer overlays for enterprise carve-outs. The cost of the wrong shape is paid every time finance changes pricing.
Whether the metering pipeline is in-house or vendored. Metering sits on the hot path. The latency budget is too tight for a vendor round-trip. The data shape evolves too fast to fit any vendor’s schema for long. Most companies that ship at frontier scale eventually own this layer.
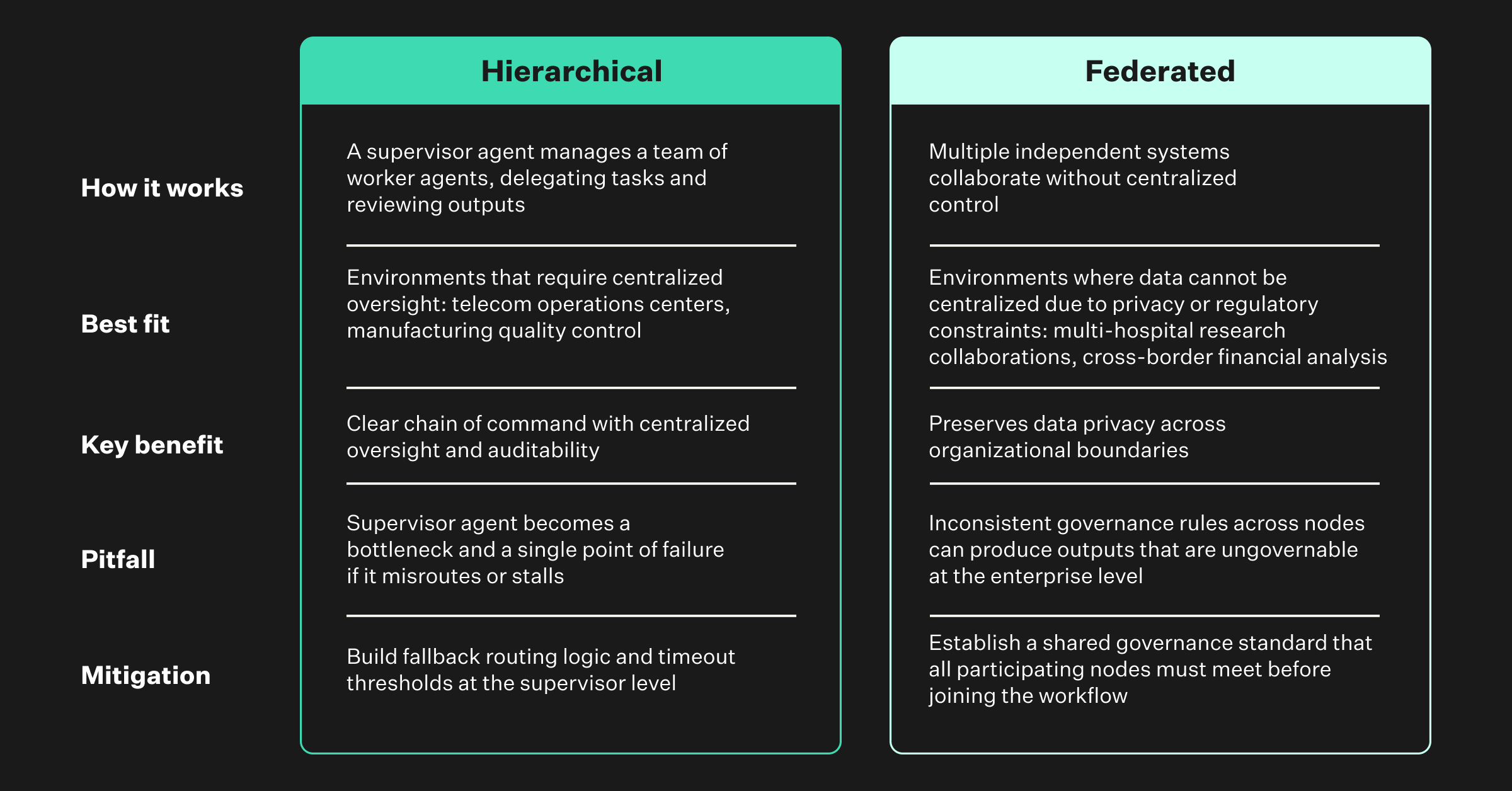
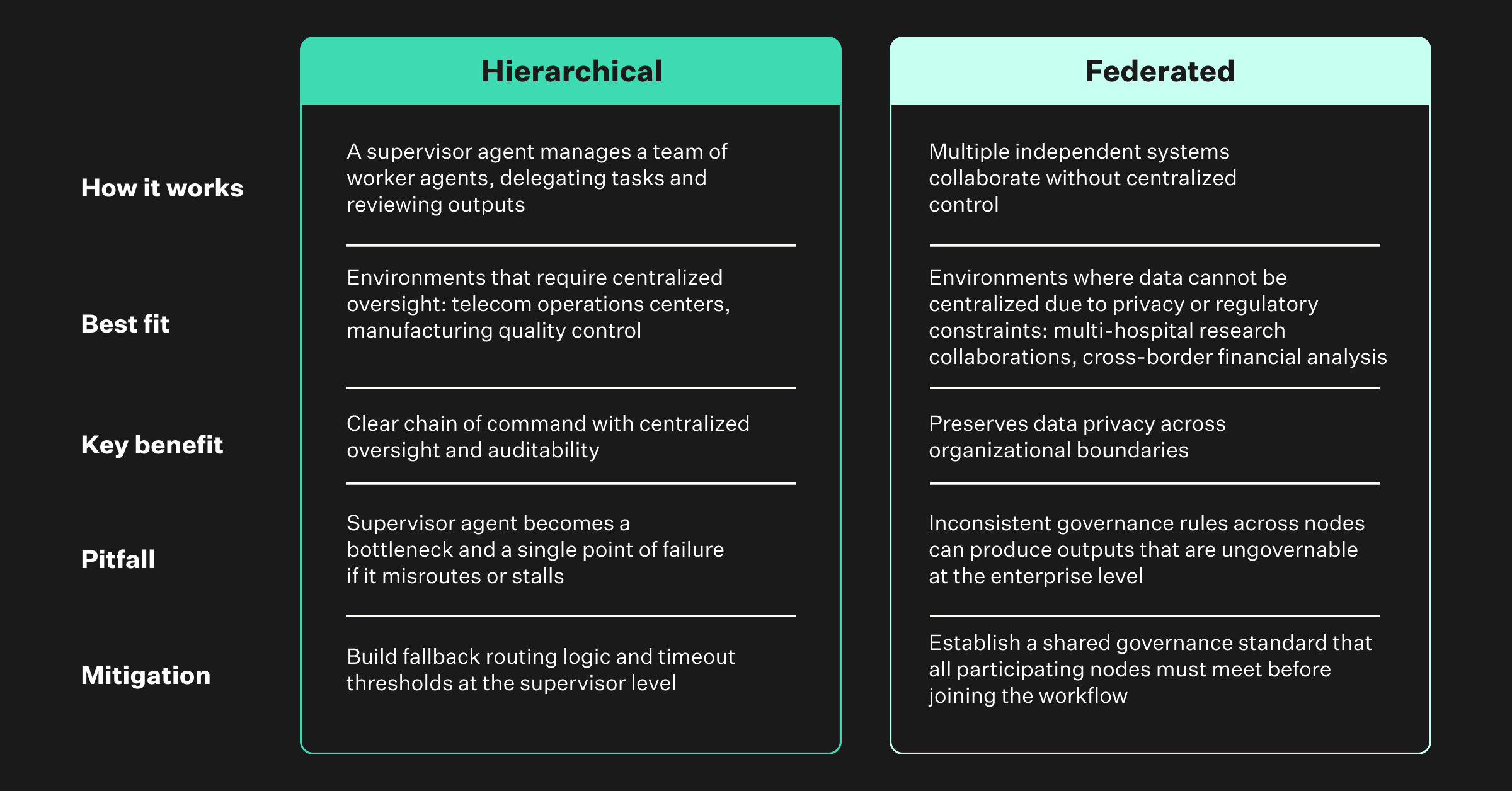
The Inline vs. Connected Tradeoff
The question of when to split agents mirrors a classic software architecture debate: when do you spin up a separate service versus keep logic inline? The answer from production deployments is refreshingly practical.
Use separate agents only when the subtask is complex enough to warrant its own tools or knowledge, requires different governance rules or access controls, or can be reused across multiple parent agents. If none of those conditions apply, an inline agent handles the job while being simpler. Separate agents introduce overhead. There is longer execution time due to context switching, and complexity in maintaining multiple agents.
Start with one agent. Split only when you clearly see a need for modularity or a boundary a single agent shouldn’t cross. This is the same principle that drives gut-feeling architectural decisions and their hidden costs in distributed systems, most teams over-split early and pay the complexity tax for months.
What to Do This Quarter
If you run an enterprise AI program, audit your highest-volume workflow against three questions:
First, is the metering of agent token spend separated from the execution path? If not, you can’t price the workflow, you can’t charge customers differentially, and you can’t tell finance which agents are actually returning ROI.
Second, is there a single place where you can flip an entitlement and instantly change what an agent is allowed to do? If not, you are one rogue agent away from a critical incident. Recent enterprise surveys found that 35% of executives admit they could not immediately pull the plug on a rogue AI agent. Read that twice.
Third, if you replaced your orchestration framework tomorrow, would your metering and entitlements logic survive? If not, you’re betting your billable workflow on a depreciating asset.
If the answers come back no, no, and no, what you’re actually running is a pilot at production volume on infrastructure that needs to be rebuilt. The work that closes the gap to scale is not in the model layer or the framework layer. It’s in the substrate underneath.
The shape of that substrate is already known. The four hardest problems billing teams solved between 2015 and 2020 map directly onto the four hardest problems enterprise AI programs face today. Finance wants to change pricing without engineering involvement. Sales closes non-standard contracts requiring concurrent models. Customers hit limits and need one-time overrides. The system needs to detect overruns in real time, not at end-of-month reconciliation.
Same problems. Same architecture. Different unit of measurement.
The teams who already learned this from the billing wave are the ones building the durable agent stacks today. Everyone else is about to discover the same lessons the hard way. The questions above will tell you which group you’re in.
And if you’re staring at a dashboard right now wondering why your agent costs are exploding and your team is doing incident review after incident review, start with the handoffs. Trace the workflow not through the logic but through the boundaries. Every one of those boundaries is a billing event you didn’t know you authorized. The agents are not the problem. The space between them is.
