Every event-driven system built on at-least-once delivery shares a dirty secret: duplicates aren’t the exception, they’re the contract. You can build the most elegant stream processing pipeline in the world, but the moment a worker crashes mid-processing, a network packet vanishes, or a consumer group rebalances, that same event will arrive again. And again.
The question isn’t if you’ll see duplicates. It’s whether your system will survive them.
A developer recently laid out their architecture on Reddit: a push notification platform using Redis Streams and Python, consuming domain events like UserRegistered, PortfolioCreated, and GoalCompleted. They’d already implemented an idempotency key approach, generate a key per event, store processing state in Redis, reject duplicates, and shunt persistently failing events to a DLQ. Solid foundation. But the comments revealed just how many ways this can go sideways.
Let’s dig into what actually works when you’re processing millions of events and can’t afford to process any of them twice.
The Four Horsemen of Duplicate Events
Before you can defend against duplicates, you need to understand where they come from. In practice, there are four scenarios that will reliably produce them:
| Scenario | How It Happens | Frequency |
|---|---|---|
| Worker crash after processing, before ACK | Event is processed, state is saved, but the acknowledgment never reaches the broker | High |
| Network failure during processing | A timeout causes the sender to retry while the handler is still working | Very High |
| Consumer rebalancing | Partitions are reassigned, and in-flight messages get reprocessed by new consumers | Medium |
| Retry queue redelivery | A previous failure lands the event in a retry queue that re-delivers it hours later | Medium |
The developer’s original post nails the core tension: “At-least-once delivery guarantees reliability, but it also guarantees duplicates.” This isn’t a bug in your message broker. It’s a feature, and one you need to design for explicitly.
The Idempotency Key: Your First Line of Defense
The most common pattern is straightforward: generate a unique identifier per event, and before processing, check whether that identifier has been seen before. If it has, skip the event. If it hasn’t, claim it and process.
The challenge is making that check-and-claim atomic. A naive implementation, check first, then insert, inevitably races.
# DON'T DO THIS: check-then-act is a race condition
existing = await redis.get(f"processed:{event.id}")
if existing:
return # duplicate, skip
# Two concurrent workers can BOTH reach this line
await process_event(event)
await redis.set(f"processed:{event.id}", "1")
The developer on Reddit described the same problem: “I implement idempotency at the application level” because their message broker (Redis Streams) doesn’t provide end-to-end exactly-once processing. The solution is to make the claim atomic.
With Redis: SET key value NX EX ttl
import aioredis
redis = await aioredis.from_url("redis://localhost")
async def handle_event(event):
# Atomic claim: SET if Not eXists, with TTL
claimed = await redis.set(f"idempotency:{event.id}", "processing",
nx=True, ex=604800) # 7 days TTL
if not claimed:
# Already seen or in progress
return
try:
await process_event(event)
await redis.set(f"idempotency:{event.id}", "done", keepttl=True)
except Exception:
await redis.delete(f"idempotency:{event.id}")
raise
With PostgreSQL: INSERT ... ON CONFLICT DO NOTHING
CREATE TABLE idempotency_keys (
event_id TEXT PRIMARY KEY,
status TEXT NOT NULL DEFAULT 'processing',
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
-- In your application code:
INSERT INTO idempotency_keys (event_id, status)
VALUES ($1, 'processing')
ON CONFLICT (event_id) DO NOTHING
RETURNING event_id;
-- If rowCount === 0, it's a duplicate
The key insight, as one commenter on the Reddit thread pointed out: “You handle it just like you would handle it with REST API. I don’t see any difference.” They’re right. The atomicity requirement is identical.
The Storage Trade-Off: Redis vs. PostgreSQL
Both approaches work. Both have trade-offs that matter at scale.
| Concern | Redis | PostgreSQL |
|---|---|---|
| Durability | Volatile, evictions and failovers lose state | Durable, survives restarts |
| TTL Management | Built-in with EX/PX | Must be pruned manually |
| Atomicity with side effects | Impossible, separate operations | Can be in same transaction |
| Performance | Sub-millisecond | ~millisecond with proper indexing |
| Operational complexity | Another data store to manage | Reuse existing database |
The developer using Redis Streams made a deliberate choice. They needed “at least once delivery, consumer groups, message replay, low operational cost, pending messages recovery.” Redis met those requirements. But as another commenter pushed back: “How about high availability?”
This is the rub. Redis’s durability story for idempotency keys is weak. If your Redis cluster loses a node and fails over, you might lose dedup state. The duplicate you thought you’d blocked shows up again. For notification platforms, that’s annoying but survivable. For payment systems, that’s a double charge.
The strongest approach combines both: Redis for the hot path (low-latency dedup for the common case) and PostgreSQL as the source of truth. As Google Cloud’s idempotency guide notes, “Memorystore (Redis) is perfect for short-term caching of keys… while Cloud Spanner provides the ‘five nines’ of availability and strong consistency needed for high-stakes financial transactions.”
The Crash-After-Claim Problem
Both patterns share a subtle but devastating failure mode: you claim the key, then your process dies before finishing the work. The retry arrives, sees the key as claimed, and skips the event. The event is now lost forever.
The robust fix is to store a status alongside the key:
async def handle_event_with_status(event):
claimed = await redis.set(f"idempotency:{event.id}", "processing",
nx=True, ex=604800)
if not claimed:
# Check the status of the existing claim
status = await redis.get(f"idempotency:{event.id}")
if status == "done":
return # Already processed
elif status == "processing":
# Check if the claim has timed out
# Re-claim if the original worker likely crashed
# This requires a more sophisticated mechanism
# like a lease with heartbeat
pass
return
# ... process the event
With PostgreSQL, you can sidestep the problem entirely by putting the claim and the side effects in the same transaction. If the processing fails, the transaction rolls back, and the claim disappears too. This is the strongest guarantee available, but it limits you to single-database transactions.
Beyond the Door Check: Making Side Effects Idempotent
The developer on Reddit concluded with a crucial insight: “The worker can help reduce duplicate processing, but the strongest guarantee comes from making the domain operation itself idempotent.”
This is the difference between convenience and correctness. A dedup check at the door handles 99% of duplicates cheaply. But idempotent side effects catch whatever slips through, an expired TTL, a lost Redis key, a replay from six months later.
UPSERTS instead of INSERT:
-- Instead of:
INSERT INTO notifications (user_id, message, event_id)
VALUES ($1, $2, $3);
-- Use:
INSERT INTO notifications (user_id, message, event_id)
VALUES ($1, $2, $3)
ON CONFLICT (event_id) DO NOTHING;
Absolute states instead of deltas:
# DON'T: Increment, applying twice doubles the increment
user.balance += amount
# DO: Set absolute state, applying twice is harmless
user.last_transaction_amount = amount
user.transaction_status = 'completed'
Pass idempotency keys downstream: If your event handler calls an external API (say, Firebase Cloud Messaging for push notifications), forward your event ID as that API’s idempotency key. This ensures the entire chain deduplicates consistently.
Where This Gets Controversial
Here’s the take that might ruffle some feathers: idempotency at the application level is a necessary evil, but the ultimate solution is infrastructure that provides exactly-once semantics.
For years, we’ve been told that at-least-once is the pragmatic choice and exactly-once is either impossible or too expensive. But that’s changing. Google Cloud Pub/Sub now offers exactly-once delivery for Pull-based subscriptions. Kafka’s exactly-once semantics (EOS) have been production-ready for years. The message broker landscape is shifting.
The comment thread on that Reddit post captures the tension perfectly:
One commenter asked: “Are you sending events or messages?” The distinction matters because events are facts about what happened, they can’t be undone, while messages are commands that change state.
When you’re reacting to domain events like UserRegistered or GoalCompleted, processing the same event twice means double notifications, double analytics events, double everything. The event itself is immutable truth. The problem is how many times you act on it.
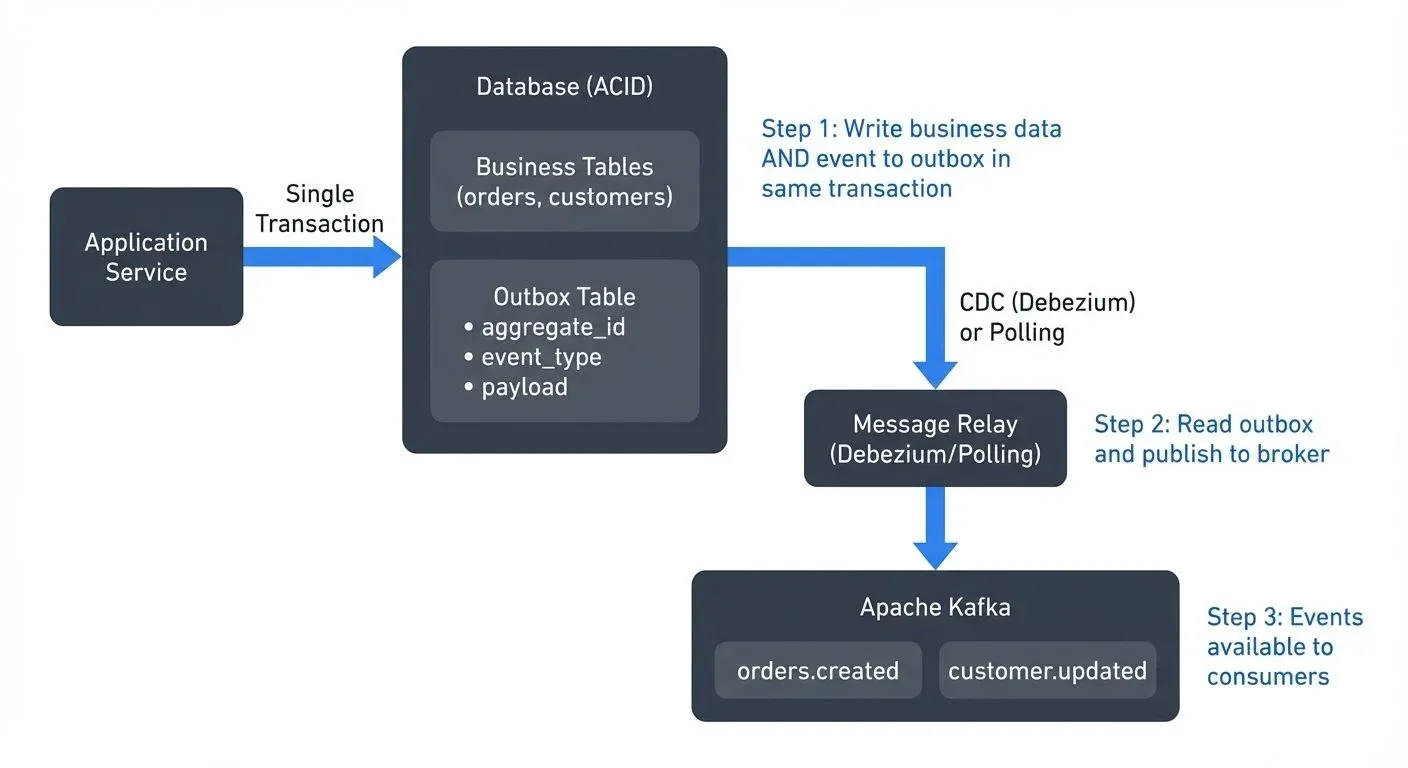
This is precisely why the outbox pattern has become so popular. By writing events to a database table in the same transaction as your business data, and then using Change Data Capture (CDC) to stream those events to a message broker, you get the atomicity of a database transaction with the scalability of a streaming platform. The outbox table becomes your dedup state, and CDC ensures exactly-once publication to the broker.
Practical Rules for Production
After building and debugging these systems, here’s what actually matters:
-
Deploy idempotency at the application level. Don’t trust your broker’s exactly-once guarantees alone. Infrastructure changes. Bugs happen. Your application should handle duplicates regardless.
-
Use the provider’s event ID as your key. Stripe’s
evt_, Shopify’sX-Shopify-Webhook-Id, and GitHub’sX-GitHub-DeliveryGUID are all stable across retries. Scope the key by source:stripe:evt_1OxYzA...rather than bare IDs. -
Set TTLs aligned with your retry window. Stripe retries for up to 3 days. Shopify for 48 hours. Set your TTL to the retry window plus a safety margin. Don’t store dedup state forever.
-
Return 200 for duplicates. Duplicates are a success from the provider’s perspective. Returning an error just schedules more retries.
-
Test it. As one guide on webhook deduplication puts it: “Capture a real event, replay it five times, and verify one set of side effects and five green responses. Then change the event ID and confirm it processes as new.”
The Hard Truth
Event-driven architectures are complex. The developer who started this thread built a solid system with Redis Streams, idempotency keys, and a DLQ. But every system has weak links. Redis’s availability. The gap between an INSERT and an ACK. The race between two workers claiming the same event.
The teams that survive production incidents aren’t the ones with perfect infrastructure. They’re the ones that assumed failure, and built idempotency into every layer.
Your worker will crash. Your network will glitch. Your consumer group will rebalance. Your events will be duplicated. The question is whether your system will handle it gracefully, or whether you’ll be explaining to your users why they received seventeen notifications for one registration.
The choice is yours. The duplicates are guaranteed.



