
DeepSeek just dropped another bomb on the AI inference world. DSpark, their new speculative decoding framework, claims to make per-user generation on DeepSeek-V4 60, 85% faster than their already-impressive Multi-Token Prediction (MTP) baseline. The numbers are eye-popping, the code is open-source, and the community is already running it on everything from dual DGX Spark clusters to local laptops. But is this a genuine breakthrough or just another incremental optimization dressed up in press-release language?
Let’s dig into the architecture, the real-world numbers, and what this means for anyone serving LLMs in production.
The Inference Bottleneck That Won’t Die
If you’ve ever watched a GPU utilization graph during LLM inference, you know the dirty secret: your expensive hardware is mostly bored. The fundamental problem is that autoregressive decoding generates one token at a time, and each token requires a full forward pass through the model. For a six-token response, that’s six sequential passes, with the GPU spending most of its time reloading weights from memory rather than doing useful computation.
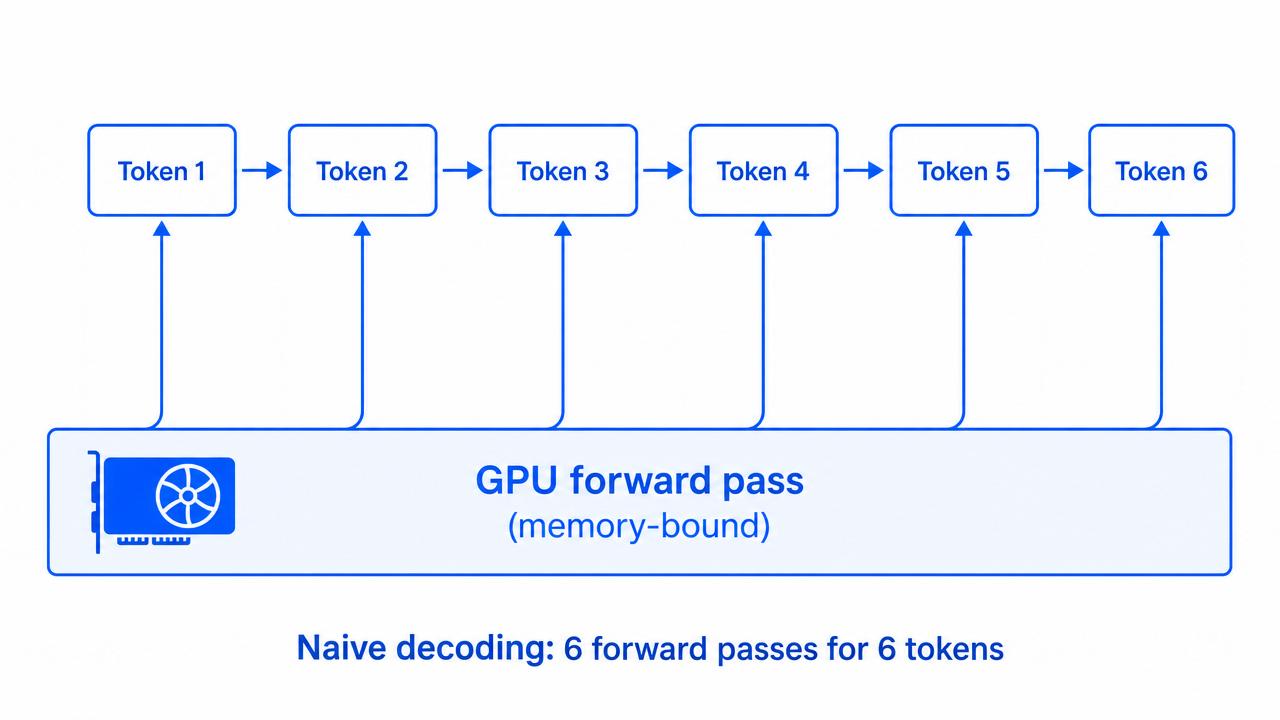
This memory-bound bottleneck is the single biggest reason LLM inference feels slow and costs too much. Every serious inference optimization technique is really trying to get more useful work done per memory load.
Speculative Decoding: The Old Trick That Keeps Getting Better
Speculative decoding attacks this problem by pairing two models: a small, fast draft model that guesses several upcoming tokens cheaply, and the large target model that verifies all those guesses in a single forward pass. The key property is that the output remains byte-for-byte identical to what the target model would have produced alone, it’s a pure latency win with zero quality trade-off.
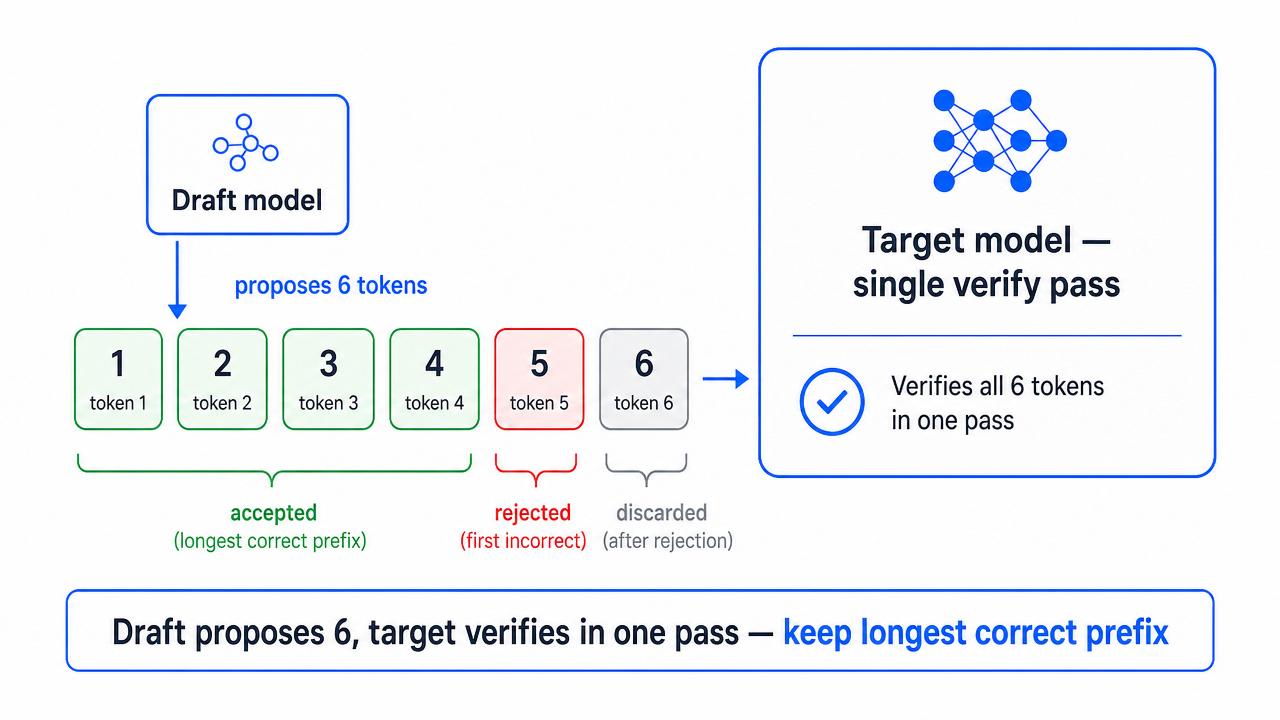
The governing equation is simple: Time per token = (draft time + verify time) ÷ tokens accepted per round. This exposes three independent levers: a faster drafter, a better drafter (so more guesses get accepted), and a smarter verifier. Different methods pull different levers, and that’s where the trade-offs live.
The Two Camps of Speculative Decoding, and Their Built-In Flaws
Before DSpark, draft models fell into two camps, each with a fundamental weakness.
Autoregressive drafters (like Eagle3) generate each guess conditioned on the previous one. This makes them accurate, but slow. They tend to produce very small blocks, limiting the speedup per round.
Parallel drafters (like DFlash) produce the entire block in one shot. That’s fast and allows much larger blocks, but each guessed token ignores its neighbors. The result is what the DSpark paper calls suffix decay: the acceptance rate slides down sharply toward the end of each block. On Qwen-3, a parallel drafter’s acceptance rate drops off a cliff as the block gets longer.
DSpark’s First Innovation: The Semi-Autoregressive Draft Head
DSpark keeps a parallel draft backbone, so it stays fast and emits every position at once, like DFlash, but bolts on one lightweight serial head whose only job is to let each token glance at the one before it. That’s just enough autoregressivity to kill suffix decay without giving up the parallel speedup.
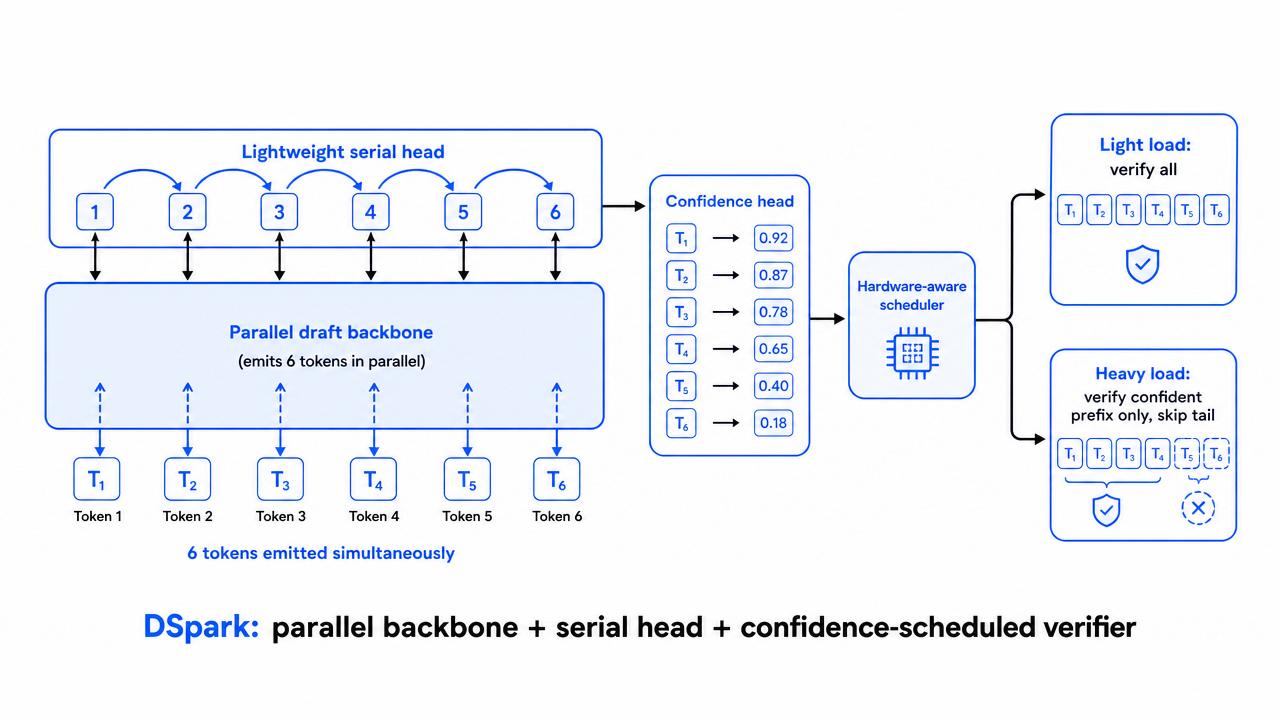
The default sequential head is a Markov head that only looks at the immediately preceding token. A low-rank factorization (rank 256) keeps it cheap, even with large vocabularies. Once position one samples “of”, the head boosts “course” and suppresses “problem”. The measured effect on Qwen-3: DSpark accepts roughly 30% longer blocks than Eagle3 and 16, 18% more than DFlash.
The Confidence-Scheduled Verifier: Where the Real Magic Happens
The second contribution targets a problem that only shows up under real serving load. Normally the target verifies every token in a proposed block, including tail tokens that are probably going to be rejected anyway. Under heavy traffic, that’s GPU time stolen from other users.
DSpark adds a confidence head that scores each proposed token, predicting which ones will survive verification. A hardware-aware scheduler then watches how loaded the server is. Under light load it verifies the full block, under heavy load it verifies only the confident prefix and skips the doomed tail. This is what turns speculative decoding from a single-request trick into a fleet-level serving optimization.
The raw neural confidence is usually overconfident, so the team applies Sequential Temperature Scaling, a post-hoc calibration step that cuts expected calibration error from 3, 8% down to about 1%.
The Production Numbers That Matter
DeepSeek’s headline figures come from its own V4 Flash and V4 Pro serving stacks. At the same total throughput, each user receives their tokens 57% to 85% faster, with no extra hardware.
| Model | Per-user generation speedup (vs MTP-1) |
|---|---|
| DeepSeek-V4-Flash | 60, 85% faster |
| DeepSeek-V4-Pro | 57, 78% faster |
These are per-user speedups at matched throughput, meaning each individual request finishes faster, not just that the server handles more total load. That’s the number that shows up as lower latency for your end users.
The wider “50 to 400%” range you’ll sometimes see refers to corner cases on the serving frontier. The 57, 85% figures are the typical, conservative outcome from DeepSeek’s own production measurements.
Real-World Validation: Running DSpark on Hardware
The community hasn’t waited around for benchmarks. Within days of the release, developers were running DSpark on everything from dual DGX Spark clusters to local laptops. One developer reported running DeepSeek V4 Flash-DSpark on 2 DGX Spark units, achieving 55.17 tok/s decode speed with 40.4% MTP acceptance for reasoning code generation with thinking turned off.

The real-world numbers tell a nuanced story. With thinking enabled, the same setup delivered 41.90 tok/s. The difference reveals a critical insight: DSpark’s draft mechanism struggles with reasoning traces where “what comes next shifts every step.” For structured text like code, drafts are easier to hit, and even with a static draft of 5 tokens, a large acceptance can be obtained.
| Prompt Type | Thinking ON | Thinking OFF | Speed-up |
|---|---|---|---|
| Medium (200 chars) | 35.44 tok/s | 35.00 tok/s | 0.99x |
| Long (500 chars) | 37.81 tok/s | 39.05 tok/s | 1.03x |
| Reasoning Code (BFS) | 41.90 tok/s | 55.17 tok/s | 1.32x |
The data reveals a critical insight: DSpark’s draft mechanism struggles with reasoning traces where “what comes next shifts every step.” For structured text like code, drafts are easier to hit, and even with a static draft of 5 tokens, a large acceptance can be obtained. The per-token acceptance jumps from 24.2% with thinking enabled to 40.4% with thinking disabled, a 67% improvement in accepted tokens per draft.
The Reality Check: What DSpark Is and Isn’t
Let’s be clear about what DSpark is not. It’s not a new model. It’s not a fundamental breakthrough in the same way speculative decoding itself was when it first arrived. As one developer on the forums put it, DSpark is “revised speculative decoding that builds on the same principles as EAGLE-3, MTP, DFlash, etc.”
The core innovations are real but incremental: a parallel drafter with a tiny sequential head to patch weak later-token behavior, and a confidence-based scheduler to avoid wasting verification capacity. It works early in the context window of these larger models, but the acceptance rate drops as the context grows longer.
That said, a 60-85% speedup on an already-efficient model is nothing to sneeze at. And the fact that it’s already merged into vLLM and being actively ported to llama.cpp means this isn’t just a research paper, it’s production-ready infrastructure.
The Open-Source Ecosystem: Already Here
The community adoption has been remarkably fast. DSpark was merged into vLLM within two days of the paper’s release. A PR for llama.cpp is already in progress. The DeepSpec training codebase is MIT-licensed, meaning anyone can train and evaluate draft models for their own systems.
For developers, DeepSpec gives a concrete implementation path:
# Install dependencies
python -m pip install -r requirements.txt
# Train a DSpark draft against a Qwen3-4B target
bash scripts/train/train.sh
# Evaluate the trained draft across 9 benchmark datasets
bash scripts/eval/eval.sh
The default configs assume one node with 8 GPUs. The target cache can be large, near 38 TB for the Qwen3-4B setting, so plan your storage accordingly.
The Bottom Line: What This Means for Builders
DSpark is a clean example of where the frontier of useful AI work has moved in 2026: not “can the model do it”, but “how cheaply and quickly can you serve it.” A 60, 85% per-user speedup on an already-cheap model, with the training toolkit open-sourced, is the kind of unglamorous infrastructure result that changes more products than most benchmark records.
The honest caveat: if you only consume a hosted API and never touch the serving layer, your benefit is indirect, you get faster, cheaper responses when your provider adopts speculative decoding, which for DeepSeek-V4 it now has. The builders who gain the most directly are the ones self-hosting open models, for whom DeepSpec turns “we should do speculative decoding someday” into a weekend project.
This release sits alongside a broader wave of efficiency innovations from DeepSeek. Their V4 architecture already demonstrated that open-weight models could compete with closed-source giants, and the V4 Pro’s cost efficiency showed that serving costs could be slashed without sacrificing quality. DSpark is the next logical step in this trajectory.
DSpark is not a revolution. It’s an evolution, but it’s an evolution that delivers real, measurable improvements to the thing that matters most in production: latency and cost per token. The fact that it’s already merged into vLLM, with a llama.cpp PR in progress, means this isn’t just a research curiosity. It’s production-ready infrastructure that’s already making models faster.
The deeper implication is that the frontier of useful AI work has shifted. The question is no longer “can the model do it”, but “how cheaply and quickly can you serve it.” A 60, 85% per-user speedup on an already-cheap model, with the training toolkit open-sourced, is the kind of unglamorous infrastructure result that changes more products than most benchmark records.
If you serve open models, read the DeepSpec repo. If you don’t, expect the responses you’re already paying for to keep getting faster and cheaper. The era of treating inference efficiency as an afterthought is over, and DSpark is one more nail in that coffin.



