The AI inference world has a new speed demon, and it didn’t come from a startup with a wafer-scale chip or a billion-dollar custom ASIC. Xiaomi, yes, the company famous for smartphones and affordable robot vacuums, just dropped a nuclear warhead on the LLM speed benchmark.
Their new MiMo V2.5, a model with 1.02 trillion parameters, is reportedly delivering 1,000 to 3,000 tokens per second in production. That’s not a typo. For context, that’s an order of magnitude faster than most frontier models running on top-tier hardware.
The tech cocktail responsible? MXFP4 quantization for the model’s massive MoE experts and a novel block-diffusion speculative decoding engine called DFlash. And to top it off, the model is already available on Hugging Face with a promise of open-source release.
Naturally, the community is equal parts hyped and skeptical. Let’s dig into the actual engineering that makes these numbers possible, the clever hacks behind the speed, and why you shouldn’t throw away your B200 just yet.
The Problem: Trillion-Parameter Models Are Bandwidth-Bound
Before we gawk at the 3,000 tps number, we have to understand the core bottleneck. A 1-trillion-parameter model sitting in FP16 requires roughly 2 TB of memory. Even on a cluster of 8x H100s (80 GB each), you’re looking at massive memory pressure.
The real killer isn’t compute, it’s memory bandwidth. Every forward pass requires shuffling those trillion parameters from HBM to the compute units. At 3 TB/s of aggregate bandwidth on a multi-node setup, you’re still looking at a theoretical maximum of only about 1.5 token fetches per second per node. That’s the hard physical ceiling.
Xiaomi’s approach attacks this from two angles: shrink the data per parameter, and shrink the number of forward passes.
FP4 Quantization: Cutting the Bit Width in Half
Standard quantization (FP8 or INT8) halves memory usage compared to FP16. Xiaomi took it a step further.
“MiMo-V2.5-Pro-FP4-DFlash is the underlying model that powers MiMo-V2.5-Pro-UltraSpeed: An FP4-quantized backbone that applies MXFP4 quantization to the MoE experts while keeping the rest of the model at higher precision, shrinking model size and memory-bandwidth pressure with near-lossless quality.”
The key insight here is precision graduation. Instead of blindly casting the entire model to FP4 (which historically destroys accuracy on complex reasoning), they only quantized the MoE experts, the massive feed-forward blocks that account for the overwhelming majority of the parameters. The attention projections and other critical modules remain at higher precision.
This is not a new idea, Google’s MXFP4 spec and DeepSpeed’s Mixture of Quantization have similar concepts, but Xiaomi’s implementation with QAT (Quantization-Aware Training) keeps the quality surprisingly close to the FP8 baseline.
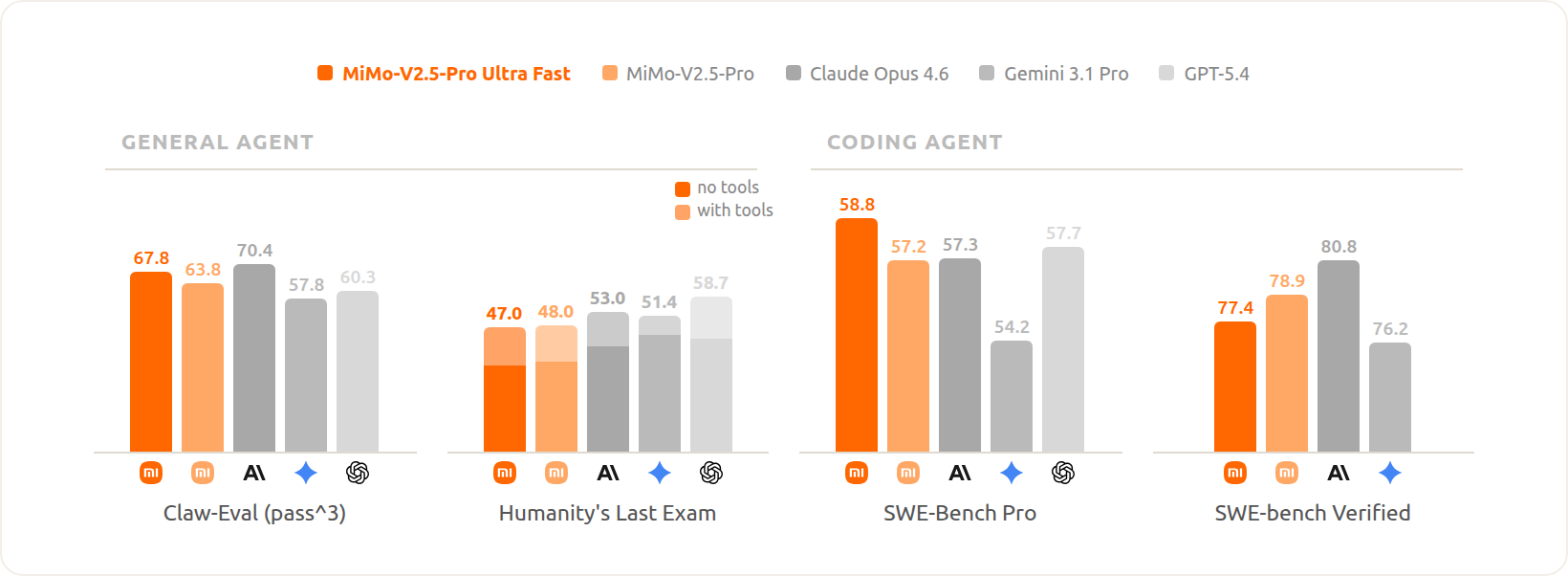
Looking at the benchmarks, the MXFP4 model actually improves on the FP8 baseline in several tasks:
| Benchmark | MiMo-V2.5-Pro-FP8 | MiMo-V2.5-Pro-MXFP4 | Δ |
|---|---|---|---|
| Claw-Eval (pass^3) | 63.8 | 67.8 | +6.27% |
| Humanity’s Last Exam | 48.0 | 47.0 | -2.08% |
| SWE-Bench Pro | 57.2 | 58.8 | +2.80% |
| SWE-bench Verified | 78.9 | 77.4 | -1.90% |
The improvements on agentic benchmarks like Claw-Eval and SWE-Bench Pro are suspicious but not unprecedented, lower precision can sometimes act as a form of regularization. The “near-lossless” claim mostly holds up, with degradation on hard QA tasks being within the margin of noise.
DFlash: The Real Secret Sauce
Halving the memory footprint is great, but it buys you a 2x speedup at best. To get to 1,000-3,000 tps, you need to reduce the number of backbone forward passes. That’s where DFlash comes in.
Standard speculative decoding (like DeepMind’s or OpenAI’s earlier work) uses a small “draft” model to predict the next 3-5 tokens, which the large model then verifies in a single pass. The bottleneck is that the draft model is autoregressive, it must produce tokens one at a time.
DFlash replaces that with a block-diffusion approach. Instead of generating tokens sequentially, the drafter fills an entire block of masked positions in a single forward pass. Think of it like a masked language model that predicts a whole sentence segment at once, but optimized for latency.
The architecture details are revealing:
– The drafter uses Sliding Window Attention (SWA) throughout, making its compute constant relative to context length.
– The backbone model verifies these blocks in a single pass.
– In practice, they cap the block size at 8 tokens to balance verification overhead and concurrency.
The acceptance lengths across different scenarios are impressive:
| Scenario | Acceptance Length |
|---|---|
| WebDev | 6.30 |
| Math500 | 5.56 |
| HumanEval | 4.54 |
| MT-Bench | 3.18 |
| SWE-Bench | 4.29 |
What this means: For boilerplate code generation (WebDev, HumanEval), the drafter is nearly perfect, it nails 6+ tokens in a single block. For creative tasks (MT-Bench), it drops to ~3 tokens, still respectable.
The implication is that the apparent speed is workload-dependent. A blog post about your weekend probably won’t see 3,000 tps. A code completion for a CRUD API just might.
The Catch: Marketing vs. Reality
Let’s address the elephant in the room. The 1,000-3,000 tps numbers come with significant asterisks.
“1000tps is with DFlash when creating boilerplate code, which is best case scenario. It’s probably also where the concurrency is really low… Their OpenRouter API (Xiaomi provider) is about 35 t/s, and they promise about 10x better perf, so 350 t/s output for regular users, probably also for coding specifically.”
Translation: The demo speeds are low-concurrency, best-case scenarios with high-acceptance-rate drafter outputs. Real-world batch inference or chat traffic will see significantly lower numbers.
That said, even 350 tokens per second on a 1T model is a massive achievement. Cerebras has shown similar speeds with their wafer-scale chips and draft models, reaching 16,000 t/s on smaller 32B models. But hitting that scale on a trillion-parameter model is genuinely new.
The Open Source Promise: A Gift to the Community
Perhaps the most exciting part is that the model weights are already on Hugging Face under an MIT license. The DFlash model (the FP4 quantized backbone + BF16 drafter) is available for download and deployment.
While the ultra-speed tier on the Xiaomi API platform is the primary commercial offering, the open-source release lets the community experiment, fine-tune, and potentially replicate the results, or at least understand the architecture.
This continues Xiaomi’s trend of open-sourcing their MiMo models, following the MiMo-V2-Flash (309B parameter model) and the full MiMo V2.5 Pro reasoning model. For a hardware company, this is a smart play: build the brand as an AI leader while letting the community validate your claims.
How to Run It Yourself (If You Have the Hardware)
The deployment configuration is a doozy. The SGLang server command reveals the hardware requirements:
python3 -m sglang.launch_server \
--model MiMo-V2.5-Pro-FP4-DFlash \
--speculative-algorithm DFLASH \
--speculative-draft-model-path MiMo-V2.5-Pro-FP4-DFlash/dflash \
--speculative-num-draft-tokens 8 \
--ep-size 16 \
--tensor-parallel-size 16 \
--data-parallel-size 2 \
--context-length 65536That’s 16-way tensor parallelism and 16 expert parallelism. You need a cluster of high-end GPUs (likely H100s or B200s) with interconnects to make this work. The model is 554B parameters in mixed precision (FP4 + BF16), but the compute graph still requires massive VRAM.
For mere mortals with 2x RTX 6000 Pro cards, the community is asking for the non-pro version to run locally. Xiaomi has confirmed they’re working on it.
The Verdict: A Genuine Engineering Leap
Xiaomi’s MiMo V2.5 is not just vaporware marketing. The combination of expert-only FP4 quantization and block-diffusion speculative decoding is a clever, principled attack on the two fundamental bottlenecks of large-scale ML inference: memory bandwidth and autoregressive generation overhead.
The 1,000-3,000 tps number is real, for the right workload and hardware. For general-purpose chat or complex reasoning, you’ll likely see speeds closer to the 350 t/s that the API provider suggests. That’s still an order of magnitude faster than most.
The open-source release means this isn’t just a paper or a press release. You can download the weights, verify the claims, and, if you have the budget, deploy it yourself.
Xiaomi has officially entered the arena where the battle is no longer just about model quality, but about how fast you can serve it. And right now, they’re lapping the competition.