The Open Weights Kingpin Just Crushed Social Deduction Games
Move over, coding benchmarks. The new litmus test for LLM intelligence isn’t solving a math problem, it’s successfully lying to your friends.
Recent independent benchmarking of Xiaomi’s newly open-sourced MiMo-V2.5-Pro model using Blood on the Clocktower, a fiendishly complex social deduction game akin to Mafia, reveals something the standard MLPerf tests miss entirely. This model isn’t just a smarter code generator, it’s a manipulative, scheming, and frighteningly effective social strategist.

And while it might not be the absolute top scorer in the latest wave of massive model releases, its combination of raw performance, token efficiency, and open-source availability signals a distinct shift in the AI arena.
Performance Metrics
Forget simple Q&A. The real test came when MiMo-V2.5-Pro was dropped into a crucible of deception, teamwork, and high-stakes social deduction. The data doesn’t lie: a win rate of 88% on the “Good” team, a role that requires cooperative logic, persuasion, and unraveling fabrications, showing a remarkable grasp of team dynamics. Its 48% win rate on the “Evil” team, while lower, still demands impressive feats of sustained lying, bluffing, and coordination with a hidden teammate.
Cost Efficiency
More telling than the win is the cost: at $0.99 per game, it’s more than 60% cheaper than rival Kimi K2.6 ($2.65/game) and a fraction of the cost of Claude Opus 4.6 ($3.76/game). Crucially, it does this with dramatically lower verbosity, averaging 183,639 tokens per game compared to Kimi’s 580,000, completing matches in a typical 2-3 hours instead of 10-15.
Decoding the Deception: How MiMo Wins
Diving into the game transcripts reveals the mechanisms behind the stats. This isn’t a model just probabilistically predicting text. It’s simulating game theory, maintaining consistent personas, and executing complex multi-turn strategies.
Take a game against GPT-5.5, where MiMo played the Good team. Early on, a player (Frank) whispers a private conversation claiming to be the “Recluse” to deflect suspicion from his true evil partner (Charlie).
“Frank’s Recluse claim perfectly explains David’s info… Turn suspicion toward Charlie for flawed logic.”
This chain of reasoning, evaluating the claim, cross-referencing it with other player abilities, and redirecting town attention, shows an advanced understanding of game mechanics and player intent.
Conversely, a loss against Claude Opus 4.6 showcases MiMo’s vulnerability seen here. Impersonating the Evil Imp, its minion (David) fatally confesses “I am the Monk” to MiMo’s character, instead of sticking to a safer bluff.
This operational error, over-sharing and breaking character, is a classic AI failure mode where a long-term, deceptive persona collapses under pressure. It’s the difference between understanding deception in theory and executing it flawlessly across dozens of conversational turns.
Beyond the Rankings: A Model Engineered for Agency
This behavioral excellence isn’t an accident. MiMo-V2.5-Pro is a 1.02-trillion parameter Mixture-of-Experts model with 42B active parameters, deliberately architected for “agentic capabilities, complex software engineering, and long-horizon tasks.” The agency focus is key.
It employs a hybrid attention architecture: interleaving Local Sliding Window Attention (SWA) with Global Attention at a 6:1 ratio. This allows it to maintain performance over a 1-million-token context window while drastically reducing KV-cache memory overhead.

The training process itself hints at this specialization. Beyond standard pre-training on 27 trillion tokens, Xiaomi uses a method called Multi-Teacher On-Policy Distillation (MOPD). The model learns from its own rollouts, guided by specialized “teacher” models fine-tuned for domains like math, safety, and crucially, tool-use and agentic behavior.
This explains its dominance in tasks requiring sustained, stepwise execution. In internal benchmarks, MiMo-V2.5-Pro autonomously built a complete Rust compiler in 4.3 hours and a full-featured video editor app in 11.5 hours. This ability to execute a thousand-step plan is directly transferable to a 3-hour game of social strategy.
The True Benchmark: Token Efficiency and Real-World Use
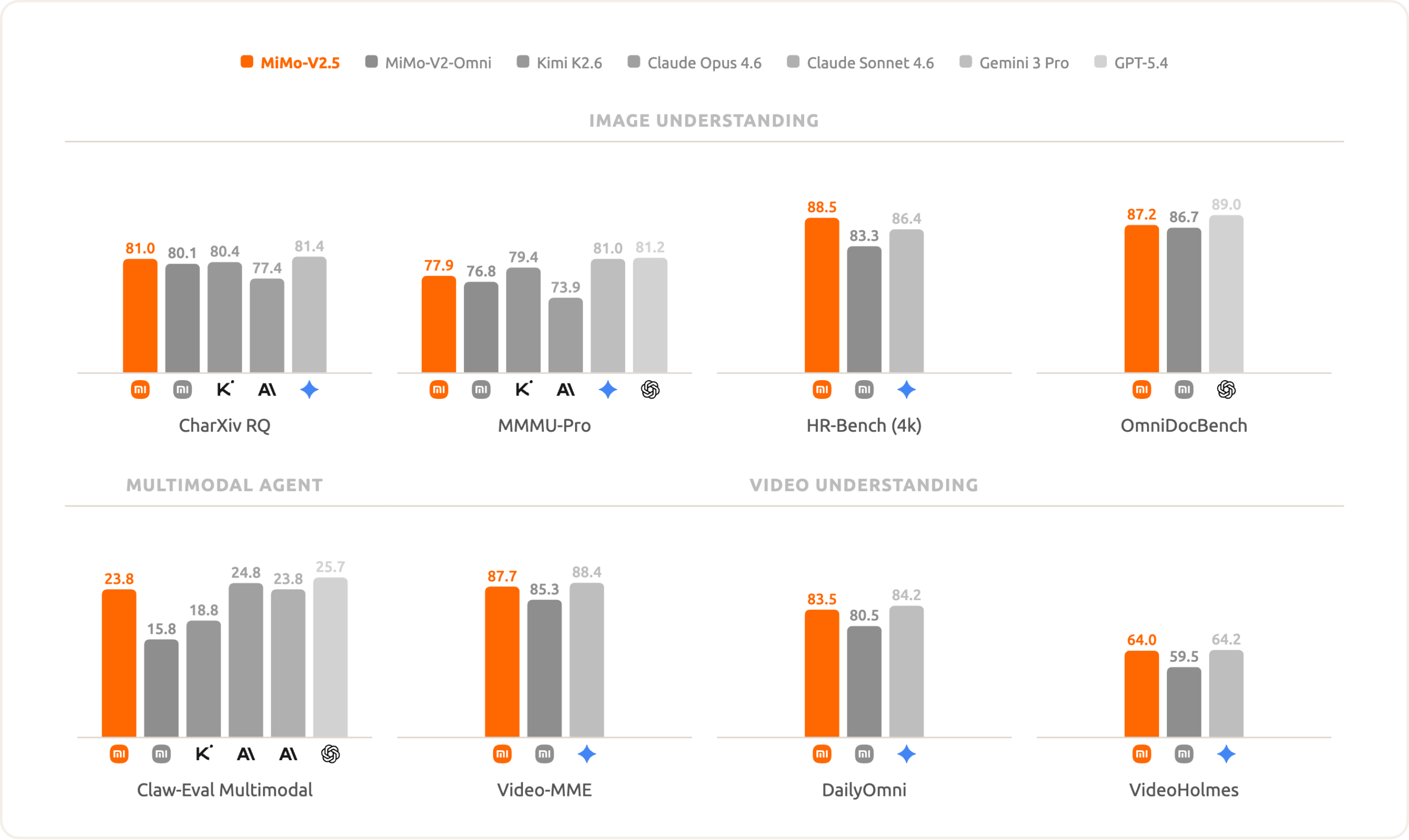
The standard leaderboards tell a competitive, but incomplete, story. On public benchmarks, MiMo-V2.5-Pro scores 73.7 on SWE-Bench Pro, 57.2 on the Coding Agent metric, and holds its own on multimodal tasks. It’s a solid, frontier-tier contender.
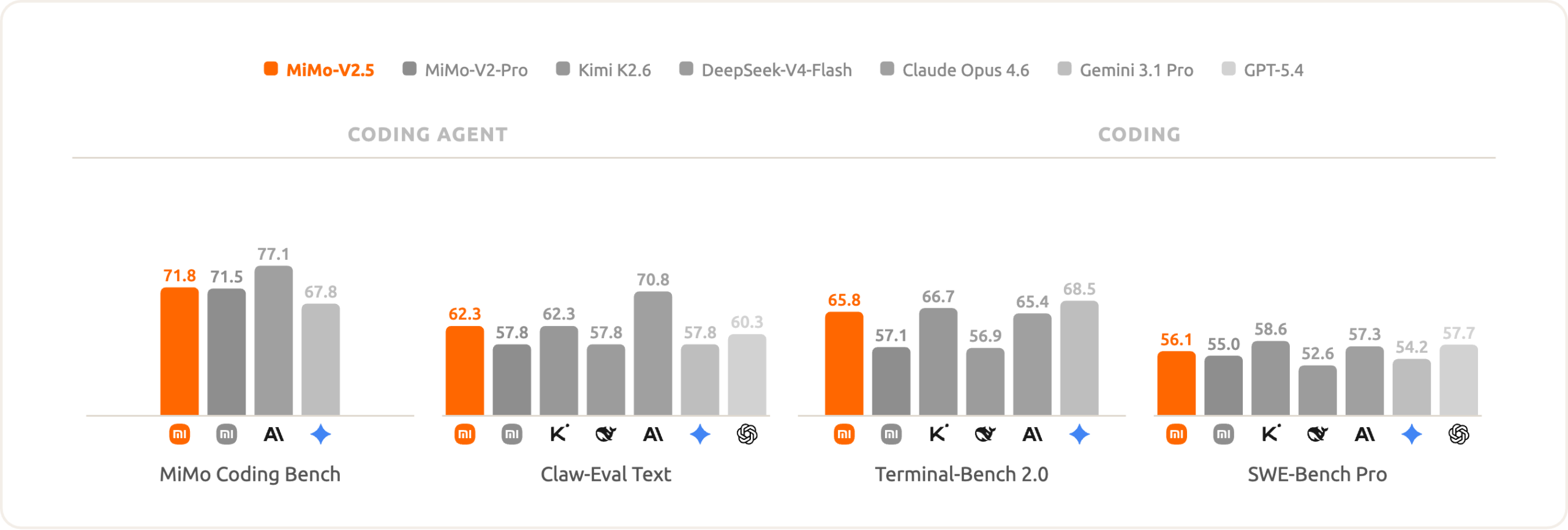
But the real advantage emerges when you look at trade-offs. On ClawEval, MiMo-V2.5-Pro achieves comparable or better performance (64% Pass^3) using 40, 60% fewer tokens than Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4.
This speaks to a broader industry trend moving beyond raw parameter counts toward inference efficiency and architectural shifts. MiMo’s design makes frontier-level intelligence viable for developers without the budget for a GPT-5-scale API bill.
Open Weights as a Forcing Function
This is where the “open weights” part matters immensely. Unlike expensive, rate-limited API calls to closed models, MiMo-V2.5-Pro is freely available on Hugging Face. The weights, architecture specs, and deployment guides are public.
This democratizes the type of testing we’re seeing. The Clocktower Radio benchmark isn’t funded by Xiaomi, it’s an independent analysis made possible because anyone can run the model. It forces evaluation beyond sanitized, Multiple-Choice-Question benchmarks into messy, real-world, multi-agent arenas where planning, persuasion, and deception are the metrics.
Implications: The New Frontier of AI Evaluation
Practical Reasoning Leap
The dominance in social deduction games suggests we’ve been benchmarking AI intelligence incorrectly. Solving a puzzle is one thing, navigating a web of lies, alliances, and hidden information is another. MiMo-V2.5-Pro’s performance indicates a leap in practical reasoning, the kind needed for customer support agents that handle complex disputes, negotiation bots, or collaborative creative tools where human-AI interaction is fraught with ambiguity.
Alignment Considerations
It also exposes a vulnerability: the lop-sided win rate (excellent as Good, merely good as Evil) suggests the model’s “alignment” or bias toward truthful cooperation is a double-edged sword. It’s great at finding truth, but less adept at manufacturing believable, sustained falsehoods—a crucial consideration for any application in competitive or adversarial environments.
The Bottom Line
Xiaomi’s MiMo-V2.5-Pro isn’t just another entry on the leaderboard. It’s a demonstration that the next phase of AI competition isn’t about who can score highest on a static test suite, but whose model can most effectively navigate the chaotic, social, and strategic realities of human-like tasks.
By being open-source, token-efficient, and demonstrably capable in these domains, it’s setting a new standard. The elite pack of open weights models now has a member that doesn’t just think, it plots, persuades, and plays to win. And you can run it yourself to find out if you’d trust it in your own game night.