Jan-v2-VL executes 49 consecutive steps without failure on long-horizon agent benchmarks, a nearly 10x improvement over Qwen3-VL-8B-Thinking’s 5-step limit. Built on a reasoning foundation rather than instruct tuning, this 8B-parameter vision-language model maintains baseline performance across text and vision tasks while dramatically extending execution horizons. The release includes three variants, low, med, and high, with the high variant achieving these results through architectural choices that prioritize sustained coherence over single-turn responsiveness. This breakthrough challenges conventional agent development wisdom and suggests reasoning models are fundamentally better suited for multi-step automation.
The Long-Horizon Execution Problem Nobody’s Solving
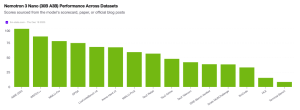
Most vision-language models tap out after 1-2 steps on extended benchmarks. Qwen3-VL-8B-Thinking pushes that to 5 steps. Jan-v2-VL-high? It runs 49 steps without failure. That’s not incremental progress, it’s a fundamental shift in what’s possible for small-scale agents.

The gap is stark: while similar-scale VLMs stall between 1-2 steps, Jan-v2-VL completes nearly 50 consecutive actions. For developers building browser automation, data entry pipelines, or any multi-step workflow, this difference separates prototypes from production-ready systems.
Why 49 Steps Changes Everything
The numbers come from the Long-Horizon Execution benchmark, specifically a test called “The Illusion of Diminishing Returns” that isolates execution capability by providing plans and knowledge upfront. This isn’t about better planning algorithms, it’s about not falling apart during sustained operation.
The benchmark reveals an uncomfortable truth: most instruct-tuned models degrade quickly because they’re optimized for single-turn correctness, not sustained coherence. Jan-v2-VL’s 49-step performance exposes this architectural blind spot. When a model needs to click, extract, transform, and validate across dozens of sequential operations, the ability to maintain internal state becomes more critical than raw accuracy on isolated tasks.
The Counterintuitive Architecture Choice
Here’s where it gets controversial: Jan-v2-VL builds on Qwen3-VL-8B-Thinking, not the instruct variant. The team discovered that reasoning models sustain much longer execution chains because they maintain internal state better. When success depends on carrying context across dozens of steps, thinking models hold up while instruct models collapse.
This runs contrary to conventional agent development wisdom, which favors instruct models for their directness and speed. The Jan team’s finding suggests we’ve been optimizing for the wrong metric, response quality at the expense of execution durability. The prevailing sentiment on developer forums reflects this surprise: many assumed instruct tuning was the path to better agents, not a limitation.
Three Variants, One Clear Winner
The release includes three distinct versions available on Hugging Face:
– Jan-v2-VL-low: Efficiency-optimized for resource-constrained deployments
– Jan-v2-VL-med: Balanced performance across latency and capability
– Jan-v2-VL-high: Maximum reasoning depth and execution length
Only the high variant hits that 49-step mark, indicating the tradeoff is real, you need the full reasoning depth to achieve long-horizon reliability. The low and med variants cater to different operational constraints but don’t deliver the same breakthrough performance.
Technical Specifications That Matter
The model’s architecture choices reveal deliberate design decisions. It’s a dense 8B parameter model, not a Mixture-of-Experts (MoE) like many recent releases. This matters because MoE gates complicate both supervised fine-tuning (SFT) and reinforcement learning (RL), making further customization painful. For enterprise and STEM applications that need iterative refinement, dense models in the 7-9B range remain the sweet spot.
Recommended generation parameters show a preference for exploration:
– temperature: 1.0
– top_p: 0.95
– top_k: 20
– repetition_penalty: 1.0
– presence_penalty: 1.5
The high temperature and presence penalty suggest the model benefits from creative generation during extended runs, preventing repetitive loops that kill long-horizon tasks.
Real-World Deployment Paths
You can run Jan-v2-VL through multiple channels:
– Direct download from Jan’s Model Hub with Tools and Vision enabled
– BrowserUse MCP integration for browser automation (the primary use case)
– vLLM or llama.cpp for custom deployments
The team is also developing a browser extension to streamline model-driven automation, indicating they intend this for production agent workloads, not just research demos. The Jan app itself provides a local ChatGPT alternative that runs these models with full privacy control.
What This Means for the Ecosystem
The developer community’s reaction has been immediate. The benchmark results drew attention for demonstrating that small, dense vision agents can compete with larger models on sustained tasks, critical for enterprise deployments where batch processing and predictable performance matter more than raw scale.
The finding that instruct models degrade while thinking models persist raises uncomfortable questions for teams heavily invested in instruct-tuning pipelines. It suggests the RLHF rush may have created models that are brittle under extended use, optimized for demos rather than durable automation.
The Tradeoff Everyone’s Ignoring
Jan-v2-VL isn’t magic. The high variant’s 49-step capability comes at the cost of speed, thinking models generate more tokens per step. For quick, single-turn tasks, an instruct model might still be preferable. The key is matching model architecture to task structure: thinking models for sustained execution, instruct models for rapid response.
This nuance is already sparking debate about whether the industry has reached an inflection point where reasoning models should become the default for agentic workloads, relegating instruct models to chat-only use cases.
Jan-v2-VL’s 10x improvement isn’t just a better model, it’s a proof point that reopens fundamental architecture questions. For developers building agents that need to run for dozens of steps without human intervention, the message is clear: start with reasoning models, not instruct models, and question any benchmark that doesn’t test sustained execution.
The era of judging models on single-turn performance is ending. Long-horizon reliability is the new battleground, and Jan-v2-VL just showed that smaller, denser models can win it.