Here’s the uncomfortable truth that the ModelRift OpenSCAD LLM Benchmark just confirmed: Google’s Antigravity 2.0, powered by Gemini 3.5 Flash High, generated a parametric CAD model of the Pantheon that included a coffered ceiling, the signature interior detail that every other autonomous LLM missed entirely. Not just a dome with an oculus. It built the 5 rings of 28 coffers that define the actual architectural experience of standing inside that 1,900-year-old building.
That’s not text-to-image generation. That’s spatial reasoning executed through code.
And it’s forcing a fundamental rethinking of what we mean by “software architecture” when the software in question is geometry.
Why Building a Roman Temple Matters More Than You Think
This was not a basic OpenSCAD syntax test. As the ModelRift team explained, “All of the current coding LLMs can produce a simple ‘cube with a hole’ model in OpenSCAD perfectly well.” The Pantheon was chosen precisely because it sits in an instructive middle ground, radial symmetry meets Boolean operations meets architectural judgment.

The benchmark pitted six tools against each other: Cursor 3.5, Codex 5.5 High, Claude Code with Opus and Sonnet, Google Antigravity 2.0, and ModelRift’s human-in-the-loop workflow. The prompt was minimal: two reference images and an instruction to build an OpenSCAD model.
What happened next exposes the fault lines in how AI-generated code should be architected.
The Antigravity 2.0 Win: Research, Not Just Generation
Antigravity’s victory wasn’t just about better code generation. It was about architectural research.
While other agents eyeballed the reference images and approximated dimensions, Antigravity searched for real Pantheon parameters. Its implementation plan explicitly called out: “Implement a detailed, visually stunning, and dimensionally accurate 3D model of the Pantheon in Rome using OpenSCAD.”
This is the critical distinction. Most LLM code generation operates on pattern matching, what does a dome look like in training data? Antigravity operated on knowledge retrieval, what are the actual dimensions of this specific dome?
The result speaks for itself: the only autonomous model to include the coffered ceiling.
But here’s where this gets architecturally interesting. The quality score was 4.5/5. The speed score was 1/5. It took roughly 12 minutes to complete.
Speed did not predict quality. This is a pattern we’re seeing across architectural entropy accelerated by AI-generated code, the fastest runs produce the weakest outputs, and the strongest architectural reasoning requires time to plan, research, and iterate.
The Text-First Advantage: Why OpenSCAD Is the Right Target
The benchmark surfaces a deeper architectural truth about how LLMs should generate physical systems. OpenSCAD works as a target language because the model is “plain text code with a compact vocabulary. An agent can describe a building as nested transformations, Boolean operations, cylinders, extrusions, loops, and named modules.”
This is much closer to how language models already reason about structure than asking them to drive a 3D application through UI actions.
Think about what this means for software architecture. The most successful LLM-generated CAD workflow is one that maps human spatial reasoning to code, not to GUI operations. The geometry itself is the artifact. The code is the design history.
This directly parallels the ongoing crisis in software development. As I’ve written about the loss of architectural memory with AI-generated code, the most dangerous aspect of AI coding tools isn’t that they generate bad code, it’s that they generate code without the design intent encoded alongside it. OpenSCAD forces the design intent into the code. That’s why it works.
The Preview vs. Export Trap: A Lesson in Architectural Verification
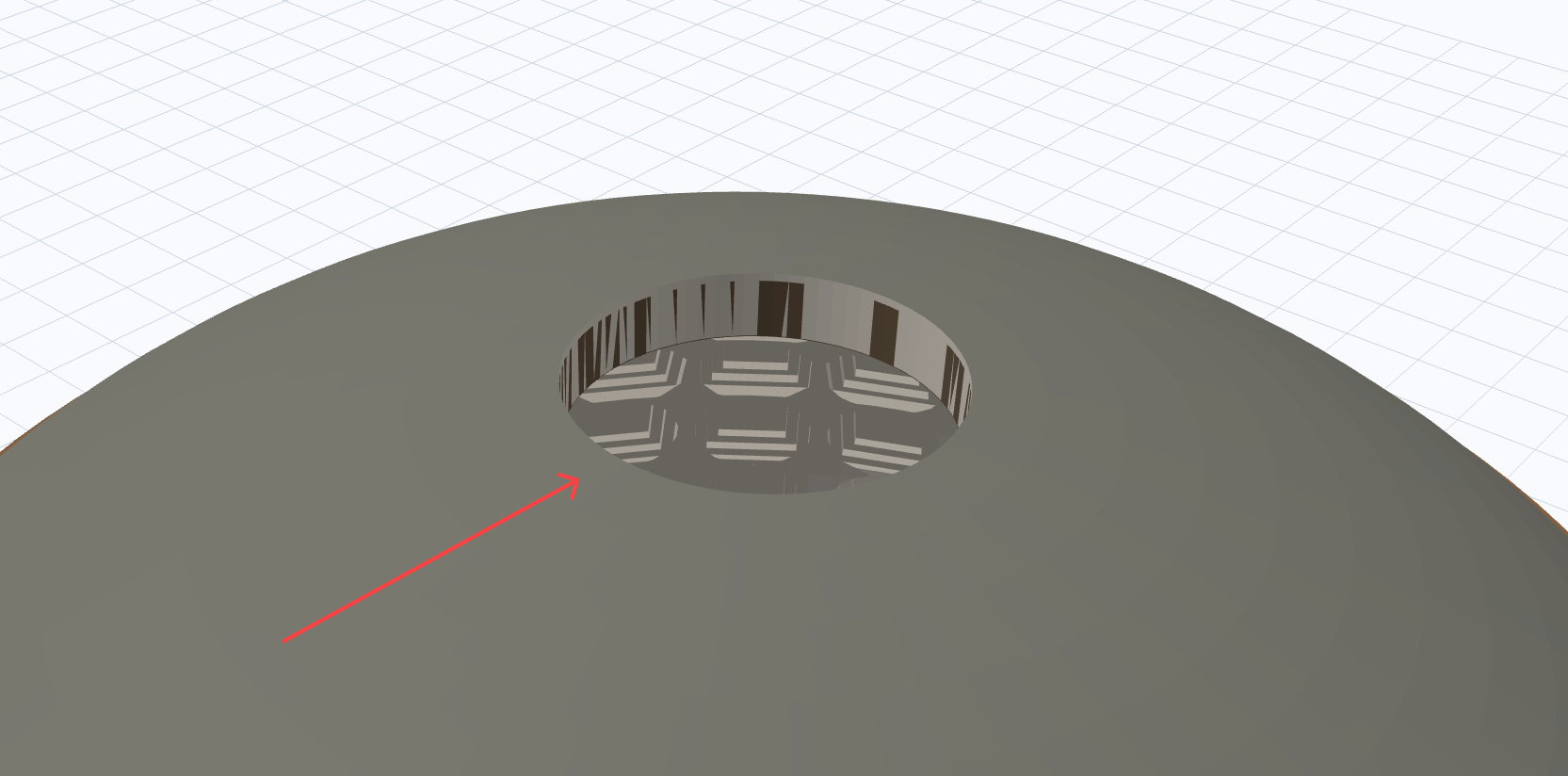
Codex 5.5 High produced the densest model. It included the rotunda, dome ribs, oculus, layered masonry bands, a front portico, columns, and even text on the entablature: M AGRIPPA L F COS TERTIVM FECIT.
But the failure mode was instructive. The render previews looked better than the final exported STL. During iteration, previews showed a coherent model. The exported mesh had geometry problems around the portico roof.
Preview correctness is not final mesh correctness.
This maps directly onto the architectural fragility of AI systems including Antigravity. The Codex preview looked right because the rendering pipeline handled certain edge cases gracefully. The STL export didn’t. The LLM had no mechanism to predict this divergence, because its “understanding” of the geometry existed only in token space, not in a robust simulation of the export pipeline.
For anyone building systems where LLM-generated code controls physical outputs, 3D prints, CNC routes, construction drawings, this is the existential risk. Your preview looks great. Your final output is garbage. And you won’t know until it’s too late.
The Human-in-the-Loop Reality Check
ModelRift’s annotation workflow, using Gemini Flash 3.0 with human visual feedback, scored 3.8/5 quality, above most autonomous runs but below Antigravity. The process took about 10 minutes.
The key insight? “Instead of writing a long spatial correction, the feedback could point at the missing or weak features on the render.”
For spatial geometry, the human-in-the-loop step matters even with tier-1 models. A model can get the broad massing right and still misplace columns or get dome proportions wrong. Pointing at the problem on the render is faster and more precise than describing it in text.
This is the architectural model for AI-assisted CAD generation that actually works: generate, inspect, annotate, regenerate. Not generate and accept. Not generate and hand-edit. Iterative annotation on the visual artifact.
What the Benchmark Data Actually Shows
| Tool and Model | Time | Quality | Key Insight |
|---|---|---|---|
| Cursor 3.5 / Composer 2.5 | 5/5 fastest | 1.4/5 | Speed without quality is noise |
| Codex 5.5 High | 4/5 | 3.0/5 | Preview vs. export mismatch |
| Claude Code / Sonnet 4.6 | 1/5 slowest | 3.4/5 | Slow but coherent |
| Antigravity 2.0 / Flash 3.5 High | 1/5 | 4.5/5 | Researched dimensions, coffered ceiling |
| ModelRift / Flash 3.0 | 1/5 | 3.8/5 | Human annotation feedback loop |
The scores tell a straightforward story: there is no free lunch. Speed trades off against quality. Autonomy trades off against precision. The best results come from systems that plan first, iterate visibly, and allow human steering.
The Architectural Implications: Code as Geometry, Geometry as Code
This benchmark isn’t really about CAD. It’s about what happens when LLMs generate artifacts that must conform to physical reality.
The architectural implications of AI at scale are becoming clear. When AI generates code, the code itself is a design document. When AI generates CAD, the OpenSCAD script is both the design and the executable. The boundary between design intent and implementation disappears.
For software architects, this means rethinking how we evaluate AI-generated code. We’ve been asking: “Does it compile?” “Does it pass tests?” “Is it performant?”
The Pantheon benchmark asks a harder set of questions: “Does the preview match the export?” “Are the dimensions real or approximated?” “Did the agent research the domain or just pattern-match the shapes?”
Those questions apply equally to software systems. An LLM that generates a microservice architecture from a prompt is doing the same thing as Antigravity generating the Pantheon. It’s building from patterns, not from researched requirements. The architectural difference between “looks right” and “is right” is the same in both domains.
The Road Ahead: Parametric Architecture Is Parametric Code
Antigravity’s most impressive feature wasn’t the coffered ceiling. It was the include of a show_cutaway toggle in the OpenSCAD code.
show_cutaway = false, // Toggle to view the interior niches, coffers, and sphere
That’s not just a 3D model. That’s an interactive architectural tool. The LLM built not just geometry, but an interface to explore that geometry. The same code that generates the Pantheon also includes the ability to inspect its interior structure.
This is the direction that AI-generated CAD, and AI-generated code in general, should be heading. Not static outputs. Parametric, inspectable, modifiable artifacts that encode design decisions alongside their geometry.
The AI-coded monoliths and architectural bankruptcy we’re seeing in software is the same failure mode that would produce a static STL when you need a parametric OpenSCAD file. The artifact doesn’t encode intent. It encodes output.
What This Means for Your Architecture
Three takeaways that apply whether you’re generating CAD models or software systems:
-
Research beats pattern matching. Antigravity won because it searched for real Pantheon dimensions. Your AI coding assistant is doing the same thing when it generates API endpoints from your prompt: either researching your actual stack or pattern-matching from training data. You want the former.
-
Preview is not production. Codex’s strong previews hid a broken export. In software terms, your LLM-generated code might pass unit tests and fail in production because the test environment doesn’t simulate the actual runtime conditions. Build verification loops that test the exported artifact, not just the intermediate representation.
-
Iteration loops need visual feedback. The ModelRift annotation workflow outperformed purely text-based iteration because spatial problems are better identified spatially. For software, this means pairing AI code generation with running systems that show the actual behavior, not just the diff.
The Antigravity 2.0 Pantheon benchmark isn’t a curiosity for CAD enthusiasts. It’s a proof point for how AI-generated code architecture will evolve. The models that succeed won’t just generate faster. They’ll generate artifacts that encode design intent, support exploration, and survive the gap between preview and production.
That’s the architecture we should be building toward. Not faster code. Smarter artifacts.