The bottleneck keeps moving lower in the stack. First it was compute. Then memory bandwidth. Now, with Prefill-Decode (PD) disaggregated inference becoming the standard way to serve LLMs, the network topology running under your GPU cluster is silently bleeding performance and burning cash.
Zai just proved it. They swapped the network architecture on a thousand-GPU cluster running GLM-5.1 coding inference from the standard ROFT (Rail-Optimized Fat Tree) setup to something they built called ZCube, developed with Tsinghua University and HarnetsAI. Same GPUs. Same model. Same software stack. The only variable was how the switches connected.
The numbers from production are worth staring at:
| Metric | Improvement |
|---|---|
| Switch and optical module costs | ↓ 33% |
| GPU inference throughput | ↑ 15% |
| P99 first-token latency | ↓ 40.6% |
This isn’t a simulation. It’s a production cluster serving real traffic. And the results suggest most of us have been paying for network hardware that’s actively making inference worse.
The Problem ROFT Can’t Solve
ROFT topology was designed for training workloads, where traffic patterns are predictable and symmetric. Data moves in neat, uniform chunks between GPUs during all-reduce cycles. Rail optimization maps specific traffic to dedicated paths, and it works beautifully.
PD disaggregation destroys that symmetry.
When you separate prefill nodes from decode nodes, the KV Cache transfers between them create highly asymmetric traffic patterns. A prefill node generating context sends large KV Cache blocks to multiple decode nodes. The decode nodes request different chunks at different times. The traffic is bursty, directional, and nothing like the balanced all-reduce patterns ROFT was built for.
The result is ugly: hotspots form on specific Leaf switches. Priority Flow Control (PFC) backpressure builds up. Tail latency spikes as packets get stuck behind congestion they can’t route around. Your GPUs sit idle waiting for data that’s stuck in a traffic jam three switches away.
The failure of traditional cloud architectures under AI inference loads is becoming painfully clear as these workload patterns diverge further from what network designers assumed.
ZCube’s Radical Simplification
ZCube solves this by doing something almost stupidly simple: it removes the Spine layer entirely.
The architecture uses a fully flattened, complete bipartite interconnect between two switch groups. Every switch in Group A connects to every switch in Group B. No Spine, no multiple hops, no complex routing decisions.
This eliminates an entire category of congestion that ROFT can’t avoid by design. In ROFT, traffic from one Leaf to another must go up to the Spine and back down, competing for bandwidth on intermediate links. The static rail mapping means you can’t dynamically route around hotspots. When a KV Cache transfer flood hits, there’s no escape valve.
ZCube’s flattened design gives every node direct connectivity to every other node through a single switch hop. The complete bipartite graph means congestion on one switch pair doesn’t affect the others. Traffic naturally spreads across all available paths.
Where the 15% Throughput Gain Actually Comes From
The throughput improvement isn’t from faster switches or better optics. It’s from eliminating time the GPUs spend waiting.
The 40.6% reduction in P99 first-token latency is the key metric. In PD disaggregated inference, the first token can’t be generated until the KV Cache transfer completes. When PFC backpressure and switch congestion add 40% more latency to that transfer, every decode node in the cluster stalls waiting for data.
Fifteen percent more throughput from the same GPUs means those GPUs are starving less often. The compute capacity was always there, the network just couldn’t feed it fast enough.
The Economics Are the Real Story
The most provocative part of this result is that better performance came with 33% lower hardware costs. This inverts the usual tradeoff where you pay more for better networking.
ZCube achieves this by using fewer switches and simpler optics. The flattened topology doesn’t need the expensive high-radix Spine switches that dominate ROFT capex. The optical modules connecting Leaf switches in a bipartite graph use shorter, cheaper links than the long-haul Spine connections.
A rough breakdown shows where the savings come from:
- Elimination of Spine switches: In a 1000-GPU cluster, this removes 40-60 high-end switches depending on the exact topology
- Shorter optical runs: Bipartite connections between adjacent switch groups use lower-cost optics
- Simpler cabling: Less structured cabling reduces deployment complexity and troubleshooting time
The total savings across a production cluster run for two to three years could fund an entire engineering team.
Why This Matters Beyond Zai
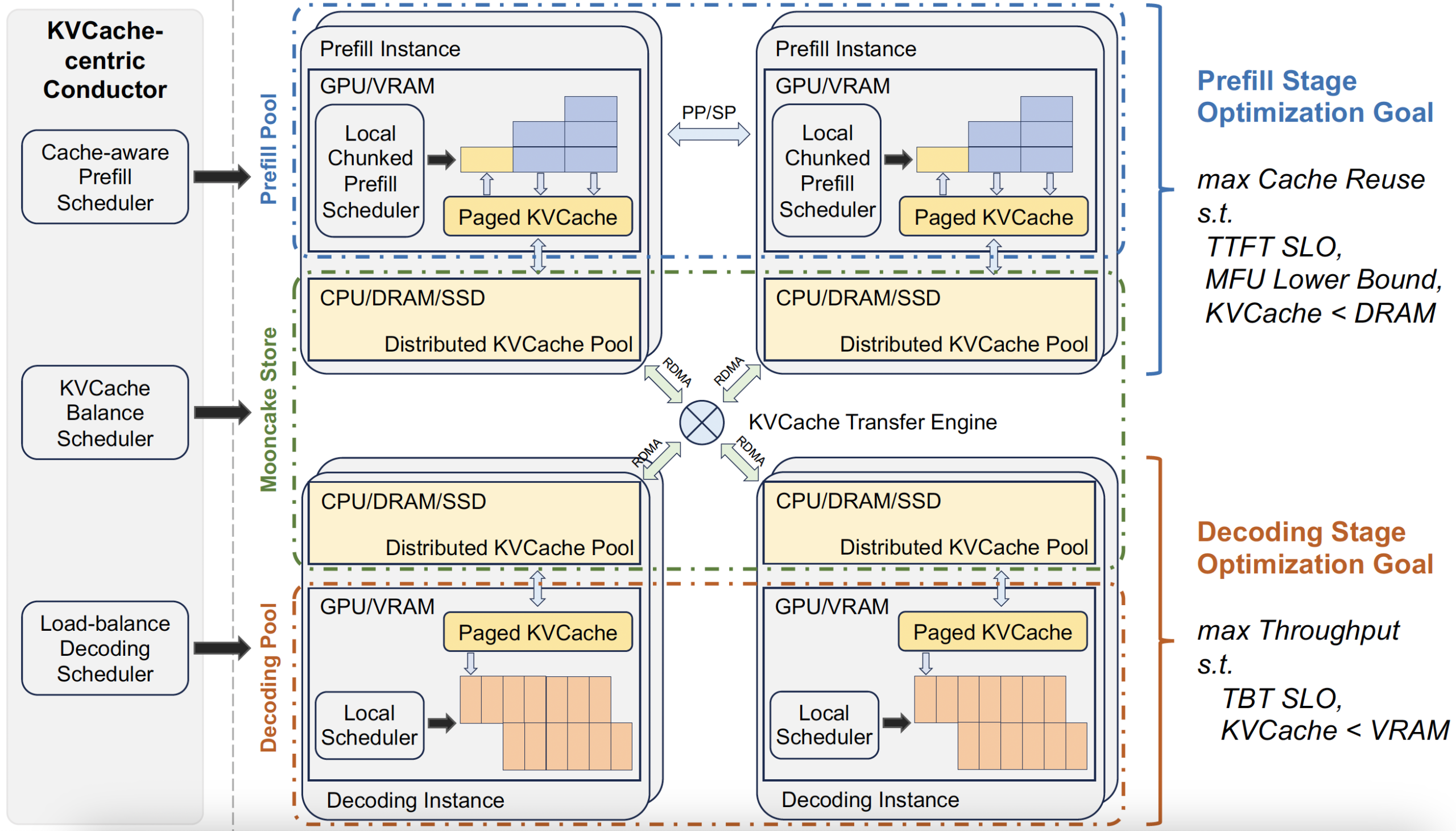
ZCube is purpose-built for PD disaggregated inference, and that workload is becoming universal. Every major inference framework, vLLM, SGLang, TensorRT-LLM, has been adding PD disaggregation support. The Mooncake platform, which powers Kimi’s serving infrastructure, has been adopted across the ecosystem, with integrations into vLLM, SGLang, LMDeploy, and LMCache.
The community’s own data confirms the gap between theoretical network architecture and real-world performance. vLLM’s Transfer Engine integration, using topology-aware path selection and multi-card bandwidth aggregation, achieved 25% lower Mean TTFT compared to TCP-based transports. The network isn’t getting faster, the architecture just needs to match the workload.
The scale is accelerating too. While Delos recently demonstrated 1000+ GPU scale-up in a single domain, ZCube is already running that scale in production. The trend is clear: inference clusters will grow denser, and the network demands of PD disaggregation will become more acute.
The Takeaway for Infrastructure Teams
If you’re deploying PD-disaggregated inference at scale and using a standard ROFT topology, you’re probably leaving at least 10-15% throughput on the floor while paying for more network hardware than you need.
The metrics Zai published aren’t marginal gains from hardware upgrades. They represent a fundamental architectural mismatch between training-oriented networks and inference workloads. The network topology that was optimal six months ago may be actively harming performance today.
A few practical steps to evaluate your own setup:
- Measure P99 KV Cache transfer latency between prefill and decode nodes. If it’s variable or bursty, your topology is the likely culprit.
- Check for PFC pause frames on Leaf switches handling PD traffic. Persistent backpressure confirms the topology mismatch.
- Run an A/B test with a flattened topology on a subset of your cluster. The ZCube paper provides enough detail to prototype the approach.
The bottleneck keeps moving lower in the stack. Right now, it’s the network. And the solution isn’t faster switches, it’s a topology that matches how inference actually works.



