
The hype cycle for GenAI and agentic AI has peaked, but reality tells a different story. While vendors promise “revolutionary” productivity boosts, data engineering teams are discovering that most AI initiatives stumble when they hit production. The truth is emerging: the most valuable deployments aren’t the flashy chat interfaces, but the unglamorous, reliable automations that actually solve real problems.
The Production-Reality Gap
The prevailing sentiment among developers shows a stark contrast between marketing promises and actual deployments. Many practitioners report that while “everyone talks about ‘productivity boosts’ and ‘next gen workflows,’ hardly anyone shows something real.”
The much-hyped “chat with your data” use case appears particularly challenging to deliver effectively. As one engineer noted: “It’s great for high level, but the moment there is some complexity it starts to compute things you’re not looking for.” At least three approaches are emerging to mitigate hallucination risks:
- Pre-calculating data to let LLMs interpret already-computed results
- Implementing semantic layers and metadata to improve accuracy
- Using verified queries with strict metric definition constraints
What Actually Ships: Beyond the Chat Interface
The real production deployments tell a different story from the marketing materials. Data engineers are finding success with practical automations:
Release Note Agents that integrate with GitHub, Jira, and Confluence are delivering real value. These systems work “really fucking well” according to developers who’ve deployed them, automating previously manual documentation processes.
Data Catalog Search and internal documentation summarization provide immediate productivity gains without the hallucination risks of more complex interactions. Data engineers are building tools that access catalog APIs directly, bypassing the need for LLM-powered semantic understanding.
Syntax Acceleration rather than replacement shows where LLMs provide maximum value. As one practitioner admitted: “My Python-Fu is not strong and instead of looking up the syntax for filtering a data frame for the 100th time, I tell the LLM to do it.” This approach acknowledges that AI augments rather than replaces existing skills.
Microsoft’s Agentic Breakthrough: Fara-7B
Microsoft Research’s recent Fara-7B demonstrates what production-ready agentic AI looks like. Unlike theoretical models, Fara-7B achieves state-of-the-art performance while being small enough to run on-device, addressing both privacy and latency concerns.
The model’s performance across established benchmarks reveals its production viability:
| Benchmark | Fara-7B | OpenAI computer-use-preview | UI-TARS-1.5-7B |
|---|---|---|---|
| WebVoyager | 73.5% | 70.9% | 66.4% |
| DeepShop | 26.2% | 24.7% | 11.6% |
| WebTailBench | 38.4% | 25.7% | 19.5% |
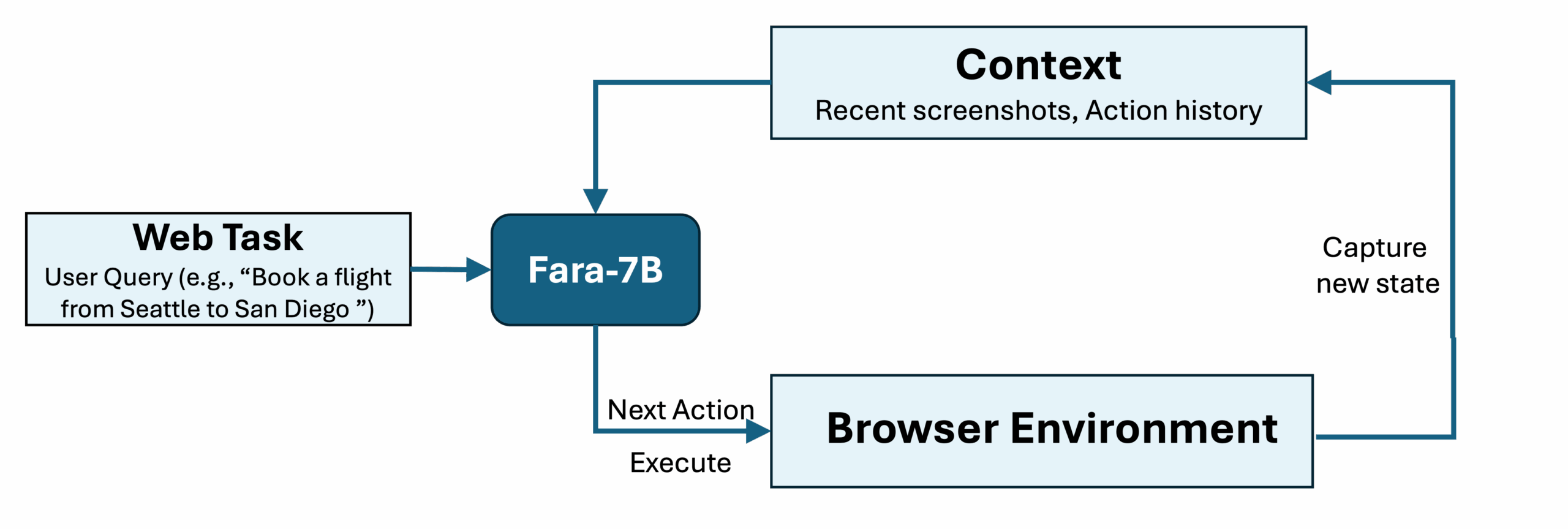
What’s more revealing is Microsoft’s approach to training data – their multi-agent synthetic data generation pipeline demonstrates the maturity required for production deployment. They generated 145,000 trajectories consisting of 1 million steps across diverse websites and task types, with three separate verifier agents evaluating task success.
Moving from Notebooks to Production Environments
The leap from experimental notebooks to production systems requires infrastructure that most teams underestimate. The Kubernetes and Terraform deployment approach demonstrates the operational maturity required:
apiVersion: apps/v1
kind: Deployment
metadata:
name: agentic-ai
spec:
replicas: 2
selector:
matchLabels:
app: agentic-ai
template:
metadata:
labels:
app: agentic-ai
spec:
containers:
- name: agentic-ai
image: agentic-ai-app:latest
ports:
- containerPort: 8080
env:
- name: OPENAI_API_KEY
valueFrom:
secretKeyRef:
name: openai-secret
key: api_key
This isn’t just about running containers – it’s about Kubernetes horizontal pod autoscaling, proper secret management, and infrastructure-as-code practices that separate viable prototypes from production systems.
The Engineering-First Enterprise Approach
Companies like Kore.ai are being recognized for their focus on “Generative AI Engineering” rather than just applications. Gartner defines this as “vendors covering full-model life cycle management, specifically adjusted to and catering to developing, refining and deploying generative models in production applications as well as overall processes orchestration.”
The key insight from successful deployments centers on two critical engineering capabilities: observability and orchestration. As Kore.ai’s Gartner recognition highlights, elements like “loss of context, factual accuracy drift, hallucination or tone alteration, reasoning and decision making are part of an automated monitoring and observability capability.”
The Unsexy Workflows That Actually Deliver
While everyone wants autonomous AI agents, the most reliable deployments focus on constrained, deterministic tasks:
Text to SQL generation works reliably when systems constrain the output space and validate against database schemas. One engineer shared: “Converting API documentation into SQL CREATE TABLE statements – the docs describe the output in JSON or XML and I get the LLM to turn it into SQL for me.”
Regular expression generation from sample data demonstrates surprising accuracy, with developers noting “It’s surprisingly good at this” for pattern matching tasks where the input-output relationship is clearly defined.
Advanced find-and-replace operations that would be tedious manually become trivial with AI assistance: “In the attached CSV, find all instances of x that are postfixed with ‘:2’ and replace that with :3 if the date in the valid_to column is over two months from today.”
Agentic Infrastructure: The Real Bottleneck
The MMC research team notes that the biggest challenge isn’t building the agents themselves, but “accepting and realizing that processes need to change.” Successful deployments require embedding agents “within the context the user needs and also show up in other UIs” rather than as standalone tools.
This reflects a broader industry realization: AI success depends more on process integration than model capabilities. As one startup founder observed, “First it’s about accepting and realizing that processes need to change, second it’s about figuring out how they need to change.”
The Privacy-Scalability Tradeoff
Microsoft’s Fara-7B highlights an important architectural decision: on-device versus cloud-hosted agents. Because “Fara-7B is small, and none of its context needs to leave your personal device, it paves the way for personal and private agentic computing.” This addresses one of the biggest barriers to enterprise adoption – data privacy concerns.

However, this comes with tradeoffs. The efficiency gains – “completing tasks with only ~16 steps on average compared to ~41 for UI-TARS-1.5-7B” – must be balanced against the reduced capability compared to larger cloud-based models.
Measuring What Matters: Beyond Accuracy Scores
The real production metrics that matter rarely make it into research papers:
- Steps to completion: Fara-7B’s ~16 steps versus ~41 for comparable models represents significant latency reduction
- Cost per inference: At $0.2 per 1M tokens, efficiency becomes a primary consideration at scale
- Integration complexity: How many external dependencies does the agent require?
- Failure recovery: What happens when the agent gets stuck or produces incorrect outputs?
As one data engineer bluntly put it about their successful deployments: “In all cases I check the output because I know they’re just advanced statistical models.” This healthy skepticism separates successful deployments from failed experiments.
The Path Forward: Constrained Automation Over General Intelligence
The most successful GenAI deployments in data engineering share common characteristics:
- Clear boundaries: They operate within well-defined problem spaces
- Human oversight: They require validation rather than blind trust
- Infrastructure integration: They work within existing Kubernetes, monitoring, and deployment pipelines
- Measurable ROI: They automate specific, repetitive tasks rather than attempting general reasoning
The future isn’t about replacing data engineers with AI – it’s about augmenting them with reliable tools that handle the tedious parts of their workflow. As one practitioner noted: “There’s no way my manager for instance would be able to use the same LLM to do my job without me.”
The most promising path forward combines the efficiency of models like Fara-7B with the operational maturity of Kubernetes deployments and the pragmatic focus on solving actual engineering problems rather than chasing artificial intelligence benchmarks. The real revolution in GenAI for data engineering won’t be measured in model accuracy scores, but in production deployments that actually work when nobody’s watching.



