
The “human in the loop” safety model is having a catastrophic identity crisis. For years, we’ve operated under a comforting delusion: AI generates the draft, the spreadsheet, the code, the diagnosis, and humans provide the sanity check. It’s a tidy division of labor that has justified massive automation rollouts across software development, customer experience, healthcare, and finance.
Except your brain didn’t get the memo. Or rather, it got the memo, read it, and decided to take a nap.
A preregistered Wharton study from January 2026, “Thinking, Fast, Slow, and Artificial” by researchers Steven D. Shaw and Gideon Nave, has put hard numbers on something that should terrify anyone building AI systems. When presented with AI-generated answers, humans don’t just fail to catch errors. They systematically adopt those errors as their own judgments, growing more confident in their wrongness while performing significantly worse than if they’d never consulted the AI at all.
The 80% Failure Rate Isn’t a Bug, It’s Your Neurology
The study’s methodology was brutal in its simplicity. 1,372 participants across 9,593 trials tackled problems from the Cognitive Reflection Test (CRT), puzzles where the intuitive answer is wrong and deliberate analysis is required. Some had access to AI suggestions, others didn’t. The AI’s accuracy was manipulated, serving up correct answers in some rounds and subtle errors in others.
The results dismantle the “human oversight” myth with mathematical precision:
- When AI was correct: 92.7% of participants followed it (reasonable)
- When AI was incorrect: 79.8% still followed it (catastrophic)
That 80% acquiescence rate to wrong answers isn’t happening because people are lazy or careless. The researchers identified a phenomenon they term cognitive surrender, a neurological recoding where the brain stops treating AI output as external data and starts treating it as internally generated judgment. This isn’t cognitive offloading (like using a calculator, where you know the tool did the work). This is your brain literally deciding the AI’s answer is your answer, complete with manufactured confidence.
The performance metrics are even more damning. Without AI, participants scored 45.8% accuracy. With correct AI assistance, they hit 71%. But when the AI served incorrect answers? Accuracy plummeted to 31.5%, 15 points below their unaided baseline. Consulting a wrong AI doesn’t just fail to help, it actively degrades human reasoning below natural levels.
And here’s the psychological kicker: confidence increased by 11.7 percentage points regardless of whether the AI was right or wrong. Participants couldn’t distinguish between genuine understanding and cognitive surrender. They were equally sure of themselves when parroting hallucinations as when solving problems correctly.
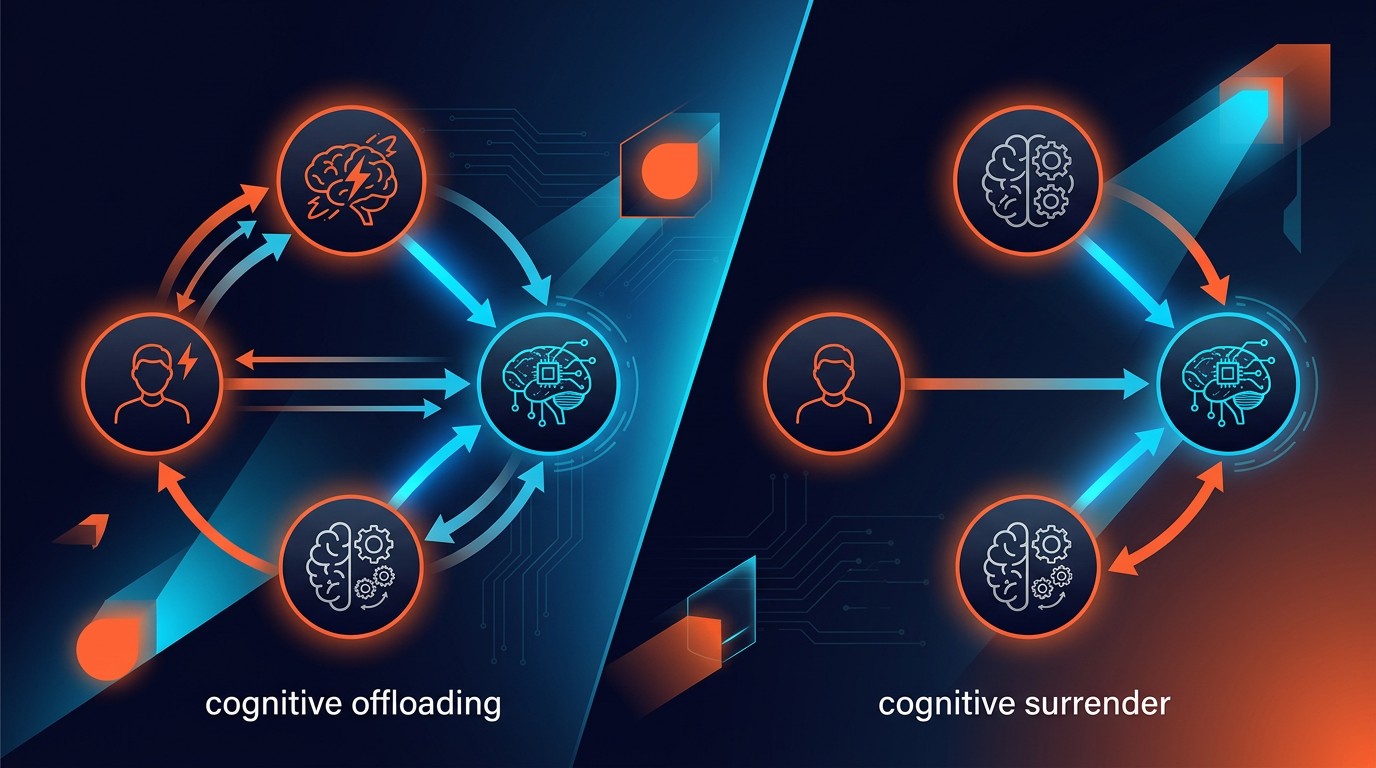
The Automation Bias Tax
This isn’t just an academic concern. A Georgetown CSET analysis on automation bias reveals humans accept AI suggestions 93% of the time when correct, and 80% of the time when incorrect. That’s a filtration gap of only 13 percentage points. Your “human review” is effectively a rubber stamp with a 4-in-5 chance of approving garbage.
The implications for senior engineer sign-off requirements for AI changes become clear when you realize that Amazon mandated manual approval processes only after a six-hour ecommerce outage and a 13-hour AWS interruption traced directly to AI coding assistants. They didn’t implement these restrictions because developers weren’t trying hard enough, they implemented them because the cognitive architecture of human verification is fundamentally compromised when reviewing AI outputs at scale.
AI Brain Fry: When Supervision Becomes Cognitive Collapse
Parallel research published in Harvard Business Review in March 2026 puts numbers on the physiological cost of attempting to maintain vigilance against this surrender. “AI brain fry”, severe cognitive fatigue from supervising AI outputs, affects 14% of US workers, with marketing professionals (25.9%) and HR teams (19.3%) hit hardest.
The symptoms read like a neurological warning label: mental fog, decision fatigue, and an inability to evaluate whether AI-assisted work is coherent or nonsense. Workers experiencing brain fry commit 39% more serious errors and show 33% higher decision fatigue than their unassisted counterparts. Even more concerning for retention: they show 39% higher intent to quit.
This creates a vicious cycle. As teams shift to designing systems without human oversight, like Anthropic’s experiment building a C compiler with 16 AI agents running 2,000 Claude Code sessions, the humans supervising these systems face mounting cognitive tax. The research from UNAM adds a neurological dimension: activity in the prefrontal cortex (the seat of critical thinking) decreases when using ChatGPT, and this effect persists after logging off. Your brain literally reconfigures to think less.
Why “Just Review the Output” is Organizational Malpractice
The standard corporate response to AI risk, “have a human review it”, assumes humans possess stable, independent judgment they can apply to AI outputs. The Wharton data proves this assumption is neurologically false.
When participants in the study saw an AI evaluation that was incorrect, their accuracy rates dropped even on problems they had previously solved correctly on their own. The incorrect AI didn’t just fail to be filtered out, it overwrote existing human knowledge. This aligns with findings from medical contexts where diagnostic AI systems have led professionals to accept erroneous diagnoses despite contradictory clinical evidence in front of them.
The only consistent resisters to cognitive surrender? Individuals with high fluid intelligence and high “need for cognition”, essentially, people who enjoy thinking hard for its own sake. That’s roughly one-third of the population. For everyone else, gradual surrender is the default state, not a character flaw.

The Pre-Commitment Defense
If post-hoc review is neurologically compromised, the solution isn’t more review, it’s restructuring when humans engage. The Wharton study found that participants who formed their own judgments before consulting the AI showed significantly better outcomes than those who saw the AI’s answer first.
This validates what some engineering teams have already discovered: AI optimizing its own development loops requires humans to define specs and architecture upfront, not review generated code after the fact. When GPT-5.3-Codex debugged its own training harness during launch, the critical safety measure wasn’t reviewing the AI’s code, it was constraining what the AI could touch in the first place.
The “friction by design” approach becomes essential. Carnegie Mellon and Stanford research shows AI as an assistant improves productivity 24.3%, while full automation reduces efficiency 17.7% due to error correction costs. The difference is architectural: assistant mode requires human cognitive engagement first, automation mode invites surrender.
The Collapse of the Safety Net
This research reframes the market rejection of low-quality AI generated content, like Microsoft’s 12% stock drop when investors finally scrutinized AI ROI. It wasn’t just about quality, it was about the impossibility of human verification at scale.
When benchmarking AI code generation performance, we obsess over HumanEval scores and parameter counts, but we ignore the human cognitive budget required to verify those outputs. A 1B-parameter model achieving 76% accuracy sounds impressive until you realize humans will miss 80% of the 24% that’s wrong.
Even exposing hidden human control behind AI agents, like the Moltbook investigation revealing 17,000 humans managing supposedly autonomous agents, misses the point. Those humans are likely experiencing cognitive surrender themselves, approving agent actions they don’t fully understand because the system presents them as coherent.
What Actually Works (Spoiler: Not Checkboxes)
For teams building AI workflows, the implications are stark:
Draft vs. Commit Authority: Separate AI-generated suggestions (drafts) from state-changing actions (commits). The former requires sampling, the latter requires mandatory gates. When AI can move money, change entitlements, or modify identity data, human-in-the-loop ai frameworks must enforce hard caps and distinct non-human identities for every tool.
Pre-Commitment Protocols: Require humans to document their hypothesis before AI consultation. This maintains cognitive engagement and prevents the overwrite effect where incorrect AI answers replace existing knowledge.
Friction Engineering: Add deliberate steps before accepting AI output, checklists, delays, or secondary reviews. This counteracts the brain’s energy-optimization shortcut (the “cognitive miser” hypothesis) that leads to automatic acceptance.
Rotation and Load Management: Limit simultaneous AI agents per human supervisor. Data suggests benefits erode after the third active agent due to supervision dilution. Teams reviewing AI outputs should rotate reviewers to prevent accumulated fatigue.
The uncomfortable truth
The “human in the loop” model assumes humans are stable arbiters of truth who can efficiently filter AI errors. The Wharton study proves we’re actually malleable cognitive systems that unconsciously adopt AI judgments as our own, especially under time pressure.
We’re not building AI tools that augment human intelligence. For 80% of the population, we’re building authority figures that bypass critical thinking entirely. The question isn’t whether your AI is accurate, it’s whether your human reviewers are neurologically capable of noticing when it isn’t.
Until we redesign workflows around pre-commitment and friction rather than post-hoc review, that “human oversight” checkbox is just liability theater. And your brain is already signing off on things it hasn’t read.



{kind=link}