
The Premature Microservices Trap: Why Startups Keep Making the Same Architecture Mistakes
You’ve got four engineers, five thousand users (if you’re being generous), and somehow you’re running twelve microservices with a service mesh. Congratulations, you’ve fallen into the premature microservices trap, and you’re not alone. After 24 years of building systems across enterprises and early-stage startups, certain architectural patterns keep repeating like a bad song on repeat. The worst part? Most of these mistakes are fixable without a complete rewrite, yet teams keep making them because they confuse complexity with sophistication.
The Four-Engineer, Twelve-Service Tragedy
Let’s start with the most common pathology: premature microservices. Your team is four engineers strong, you’re managing eight services already, and you’re thinking about spinning up four more because… well, because that’s what the architecture diagrams on Medium look like.
Here’s the reality check you didn’t ask for: you don’t have a scaling problem. You have a coordination problem. A well-structured monolith would let you move three times faster right now, and deep down, you probably know it. This isn’t about technology, it’s about why startups should default to monoliths before they can articulate what problem microservices actually solve for them.
The microservices tax hits harder than most anticipate. We’re talking distributed tracing nightmares, network latency that makes you question your career choices, and deployment pipelines that require a PhD in YAML. As one veteran architect noted after being forced to build a prototype using microservices, Docker, and Kubernetes for a six-person team: “Goddamn that was miserable.” The manager eventually left for a cloud infrastructure job, presumably to inflict the same pain on others.
Data Ownership Chaos: The Distributed Monolith Hell
If premature microservices are the disease, unclear data ownership is the complication that kills you. Picture this: three different services writing to the same database table, and nobody knows which one owns the data. During incidents, this becomes a nightmare of cascading failures and finger-pointing.
The “distributed monolith”, that special hell where you have all the operational complexity of microservices with none of the isolation benefits, often stems from this exact mistake. When 20+ “microservices” all hit the same database, you haven’t built a distributed system, you’ve built a distributed liability. The source of truth becomes a matter of opinion rather than architecture, and consistency guarantees go out the window.
For teams looking to avoid this trap, understanding trade-offs in modular monolith communication provides a saner path forward. The key is enforcing data ownership at the module level before you ever consider network boundaries.
The Operational Complexity Blindspot
Architecture diagrams look awesome on whiteboards. They look significantly less awesome at 3 AM when your message queue backs up and nobody knows which service is actually responsible for clearing it. This is the operational complexity tax that nobody factors into their “Hello World” microservices tutorial.
Monitoring and debugging in a distributed system isn’t just harder, it’s exponentially harder. Logs scatter across services like digital confetti. You see authentication errors and think it’s a credential problem, but it’s actually a timeout on a downstream service three hops away. Without robust observability (which, let’s be honest, you probably don’t have time to implement properly), you’re flying blind.
The operational and cost tax of premature microservices extends beyond just infrastructure. It consumes engineering hours that should be spent on product-market fit, not Kubernetes configurations.
Over-Engineering for Hypothetical Scale
You have 5,000 users, but only 500 monthly active users. You don’t need Kubernetes. You don’t need a service mesh. You definitely don’t need event sourcing. Yet here we are, optimizing for the 1000x scale scenario when you haven’t even validated that anyone wants your product at 10x.
This is the “resume-driven development” trap, where engineers choose complex architectures not because the business needs them, but because they look good on LinkedIn. Nobody gets hired for running a simple PHP app that works without problems, so we complicate things. We build for the next 1000x instead of the next 10x, and in the process, we slow ourselves down precisely when speed matters most.
The irony? Modern relational databases like PostgreSQL or SQL Server can handle tens of thousands of requests per second on standard 24-core hardware. The vast majority of software projects will never exhaust that capacity. When performance issues do appear, they’re almost always due to poorly written queries rather than database limitations. As the old saying goes: “Postgres for everything, and if you think you need something else, you probably need Postgres.”
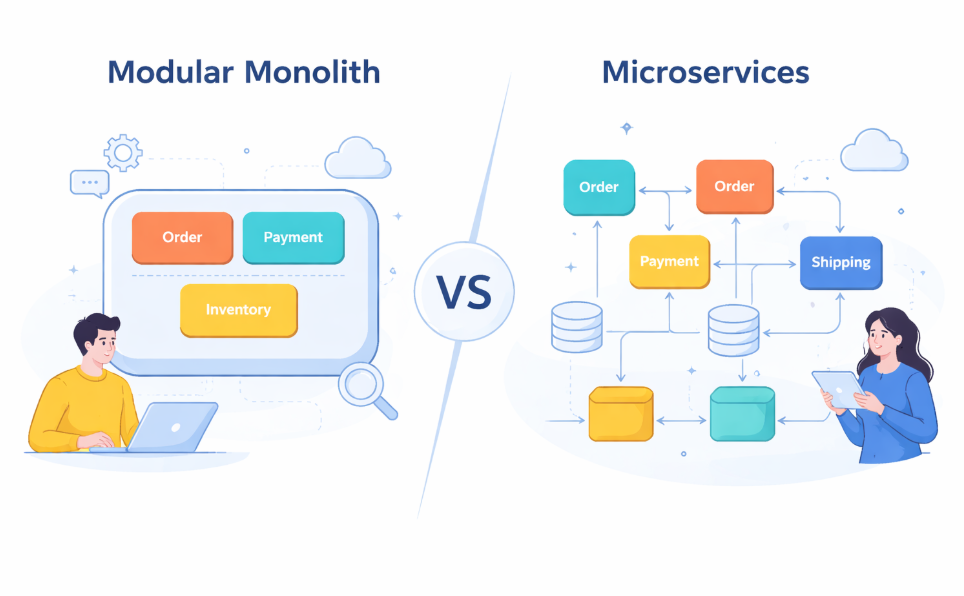
The Modular Monolith Alternative
So what’s the alternative to this distributed chaos? The modular monolith, an architecture that’s monolithic in deployment but modular in design. Think of it as why modular monoliths are eating microservices’ lunch in early-stage companies.
A proper modular monolith keeps the simplicity of a single deployable unit while enforcing clear boundaries between domains. Each module owns its business logic, controls its data, and communicates through well-defined interfaces. The difference? Network calls become method calls, and “eventual consistency” becomes “transactional consistency.”
The beauty of this approach is evolutionary. When you actually need to extract a service later, when you have real data on where your bottlenecks are, you’re extracting a well-defined unit, not untangling a ball of mud. Frameworks like Spring Modulith make this approach even more viable, enforcing architectural integrity automatically and flagging circular dependencies during builds.
When Microservices Actually Make Sense
This isn’t an argument that microservices are always wrong. They’re powerful tools, for scaling teams more than load. When you have independent teams that need to deploy at different cadences, or when you’ve identified genuine resource bottlenecks that require independent scaling, microservices shine. But these are organizational scaling problems, not technical ones.
The hard lessons from Shopify’s modular monolith migration and other major platform re-architectures show that starting with distribution often creates problems that didn’t need to exist. Even Amazon, the patron saint of microservices, has been quietly consolidating services to reduce costs and complexity.
If you’re starting today, treat your internal module boundaries as if they were API contracts from day one. Use domain events for communication rather than direct database access. Build for the next 10x, not the next 1000x. And remember: your microservices obsession killing your startup isn’t just a possibility, it’s the statistical likelihood if you’re under 50 engineers.
The Path Forward
Most of these architectural sins are fixable without a rewrite. Usually, it takes a few targeted changes, consolidating services that never needed to be separate, clarifying data ownership, or simply admitting that you don’t need that message queue, to unlock the next stage of growth.
Before you spin up that next service, ask yourself: are you solving a coordination problem or a scaling problem? Are you building for the CV or the customer? And do you actually understand what happens at 3 AM when things break?
The architecture should align with actual demand, not anticipated demand. Start simple, keep it as complex as necessary, and remember that over-engineering mistakes when scaling users are expensive lessons learned in production. Your business isn’t Netflix, and trying to architect like it is won’t make it so, it’ll just make you slower.



