The Open-Source Tipping Point: INTELLECT-3 Proves 100B+ MoE Models Can Outperform Corporate Giants
The AI landscape just got a seismic shock that corporate labs won’t want you to notice. While Big Tech continues to hoard their biggest models behind API gates, Prime Intellect just dropped a tactical nuke in the open-source space: INTELLECT-3, a 106B parameter Mixture-of-Experts model that actually beats larger frontier models in critical reasoning benchmarks.
Oh, and they’re giving away everything, weights, training code, datasets, the whole stack.
The Performance That Shouldn’t Be Possible
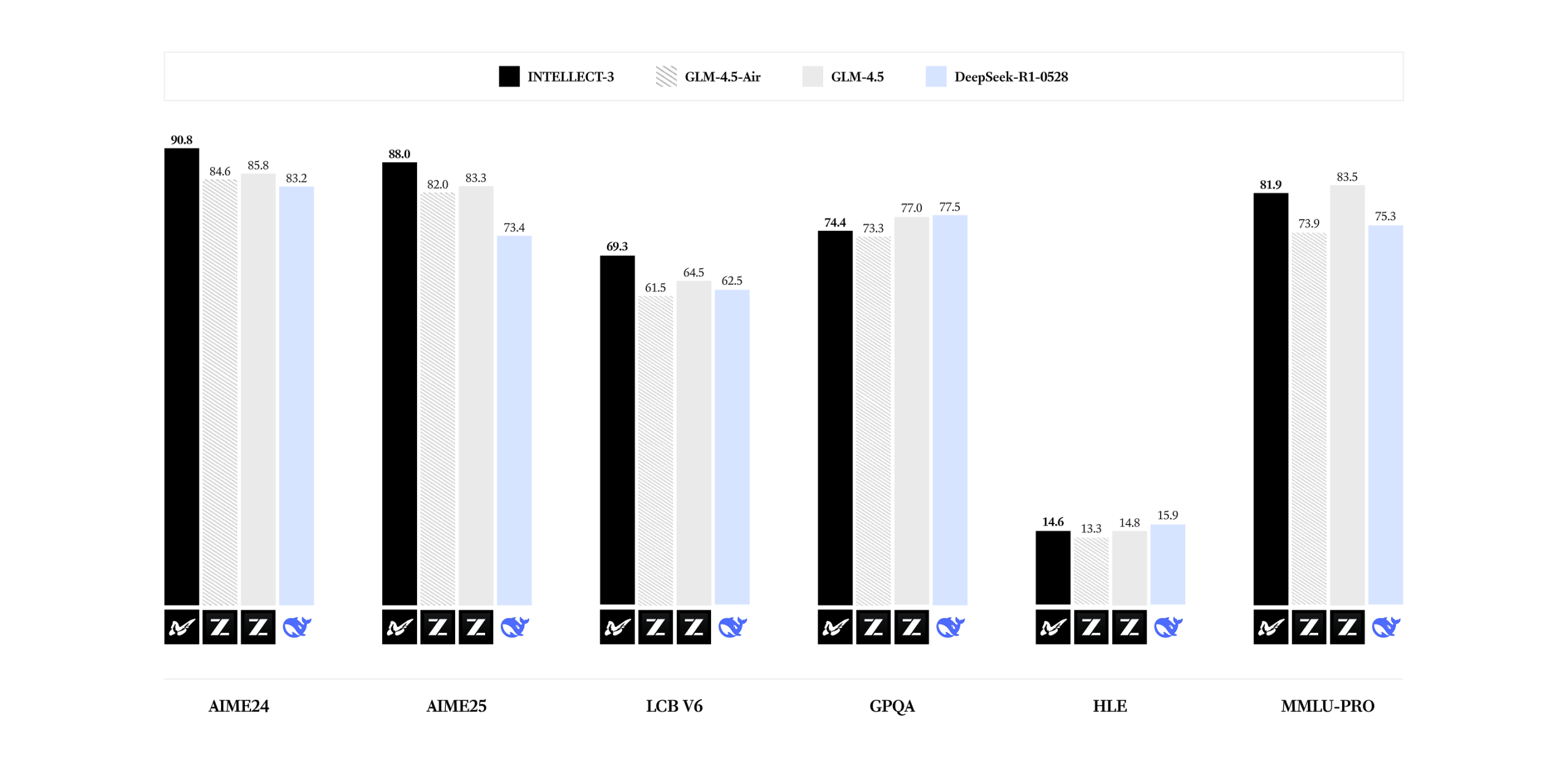
Let’s get straight to what matters: numbers that make established players uncomfortable. According to the official benchmarks, INTELLECT-3 achieves staggering performance:
- 98.1% on MATH-500
- 90.8% on AIME24
- 88.0% on AIME25
- 69.3% on LCB
What makes these numbers particularly spicy? This model consistently outperforms its base model, GLM-4.5-Air, and in many cases surpasses significantly larger models. The open-source version is trading blows with, and often beating, models that would normally cost millions to develop and remain locked behind corporate firewalls.
As one developer noted on forums after trying it, “This is the first model that made me want to immediately install it locally after testing their online chat.” The sentiment echoes across developer communities witnessing something unprecedented: open-source catching up and even surpassing closed-source equivalents in sophisticated reasoning tasks.
The Secret Sauce: RL at Scale Done Right
INTELLECT-3 isn’t just another fine-tuned model. The team executed large-scale reinforcement learning using their open-sourced Prime-RL framework, which represents one of the most sophisticated public RL training systems available.
What sets Prime-RL apart is its async-first architecture. As the Prime Intellect team discovered early on, synchronous RL training creates bottlenecks when dealing with long-horizon agentic rollouts. Their async approach means the training process doesn’t get held up waiting for the slowest rollout, critical when you’re scaling to hundreds of GPUs.
The system architecture reveals why this works:
- Orchestrator: Lightweight CPU process handling data flow between trainer and inference
- Trainer: FSDP-based with native PyTorch parallelism for efficient MoE training
- Inference: vLLM-powered servers that can be updated mid-training via custom endpoints
This isn’t theoretical research code, this is production-grade infrastructure that ran on 512 GPUs to produce INTELLECT-3, as documented in Yacine Mahdid’s insider account of visiting their San Francisco headquarters.
Accessibility That Changes the Game
Here’s where it gets practical for the rest of us. While the BF16 version requires 2x H200s, the FP8 quantized version runs on a single H200. For those playing the home game, that means you can serve this model without needing a data center.
The vLLM configuration makes deployment straightforward:
vllm serve PrimeIntellect/INTELLECT-3-FP8 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser deepseek_r1The quantization approach uses row-wise FP8, with developers reporting “we can’t tell the difference neither with eval or with vibe check” between FP8 and BF16 versions. This level of optimization means organizations can deploy frontier-level performance without frontier-level infrastructure costs.

Why This Actually Matters
Beyond the technical fireworks, INTELLECT-3 represents something more profound: the democratization of frontier AI research. The team isn’t just releasing a model, they’re releasing the entire training ecosystem: Prime-RL framework, verifiers environment library, and their Environments Hub.
This fundamentally changes the power dynamics in AI development. Previously, reproducing results from papers like these required massive compute budgets and proprietary infrastructure. Now, any research lab or company with modest GPU access can build upon this work.
As one developer put it, “This is the kind of stuff should be taught at colleges now.” They’re not wrong, this release package essentially provides a complete curriculum for modern RL training at scale.
The Business Model Behind the Generosity
Prime Intellect isn’t just being altruistic. They’re building a platform play where the open-source releases serve as both proof points and onboarding mechanisms for their compute platform. By proving they can build frontier models, they demonstrate their infrastructure’s capabilities while building community trust.
It’s a brilliant strategy: use open-source to showcase competency, then monetize the compute platform that made it possible. As noted in their documentation, their compute platform “aggregates compute across datacenters and provides a single unified interface to access compute, from single-node spot-instances to large-scale cluster reservations.”
What This Means for the Ecosystem
INTELLECT-3 accelerates several trends that should worry established players:
- The performance gap is closing: Open-source models can now compete with proprietary ones in specialized domains
- Training methodology matters more than scale: Efficient RL training can extract more performance from smaller architectures
- The infrastructure is commoditizing: What once required proprietary systems now runs on open-source frameworks
The Future Is Open (Whether They Like It or Not)
The most telling reaction came from developers who immediately wanted to run this locally. While corporate labs build ever-larger models requiring ever-more compute, the open-source community keeps finding ways to do more with less.
INTELLECT-3 proves that sophisticated RL training applied to well-architected MoE models can punch far above their weight class. More importantly, it demonstrates that the secret sauce isn’t just in the model architecture, it’s in the training methodology and infrastructure.
As the AI landscape continues to fragment between closed and open approaches, releases like INTELLECT-3 make an increasingly compelling case that the future of AI development might not belong to the biggest corporations, but to the most open ecosystems.
The model weights are available now on Hugging Face, and you can chat with INTELLECT-3 to see the performance for yourself. The revolution won’t be centralized, it will be distributed.



