
Proof Is the New Vibe: How Mistral’s Leanstral Just Killed 'Move Fast and Break Things'
The “vibe coding” era is officially on life support. While the rest of the industry was busy generating JavaScript spaghetti that passes unit tests 60% of the time, Mistral just dropped a thermonuclear device into the conversation: Leanstral, the first open-source code agent specifically trained to write mathematically provable code in Lean 4. And it's not some academic toy, it's a 119-billion-parameter Mixture-of-Experts beast that costs $18 per run compared to Claude Opus 4.6's $1,650 to achieve similar results on formal verification tasks.
If you're still shipping code that “probably works”, you might want to sit down.
The Unification: One Model to Replace Three
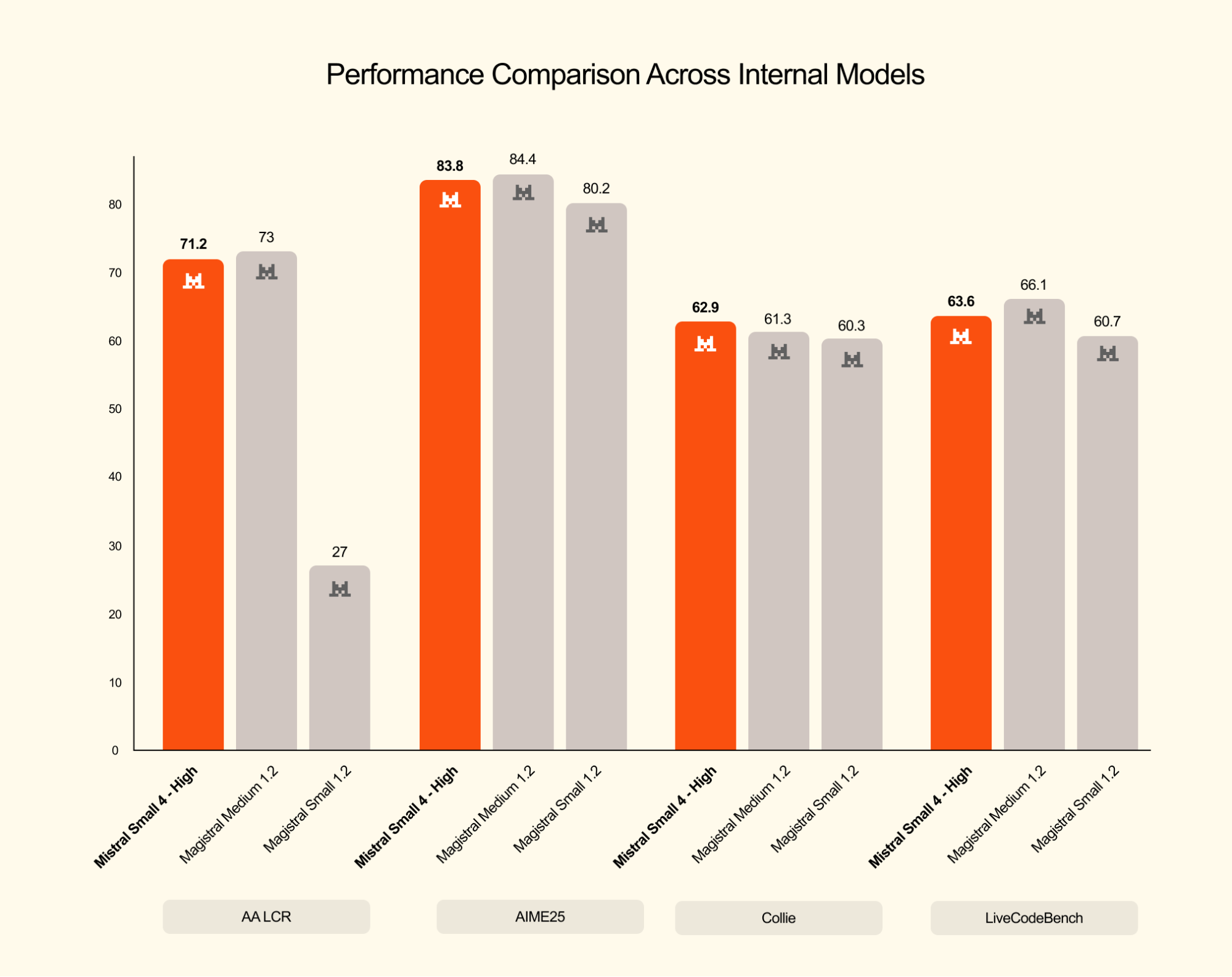
Mistral Small 4 isn't just another entry in the strategic shift toward efficient small open-source models, it's a fundamental architectural pivot. With 128 experts and only 6.5 billion active parameters per token, this 119B-parameter model unifies three previously distinct model families into a single Apache 2.0-licensed package:
- Instruct capabilities for general chat and instruction following
- Reasoning (formerly Magistral) for deep, step-by-step logical analysis
- Devstral for agentic coding and software engineering automation
The kicker? You toggle between “fast instant reply” mode and deep reasoning mode via a simple reasoning_effort parameter, "none" for quick tasks, "high" for when you actually need the model to think before it speaks. In latency-optimized setups, Mistral Small 4 achieves a 40% reduction in end-to-end completion time compared to its predecessor, while throughput-optimized deployments handle 3x more requests per second.
But the real story isn't the generalist model, it's the specialist that rides shotgun.
Leanstral: When Your Code Agent Has a PhD in Mathematics
Leanstral is the first open-source code agent designed specifically for Lean 4, the proof assistant capable of expressing everything from perfectoid spaces (advanced algebraic geometry) to formal specifications of Rust program fragments. If that sounds esoteric, consider this: Lean 4 is what mathematicians use when they want to be absolutely certain their proofs are correct, and what verification engineers use when they want to prove a Rust program won't crash in production.
Built on the same 119B-parameter MoE architecture as Mistral Small 4 (6.5B active, 256k context window), Leanstral represents a radical departure from the “spray and pray” approach of generic coding agents. Instead of generating code that might work, it generates code accompanied by formal proofs of correctness, or identifies exactly why your specification is impossible to satisfy.
The comparative benchmarks for Mistral's coding models reveal why this matters. On the FLTEval benchmark (designed to test realistic proof engineering scenarios rather than isolated math competition problems), Leanstral achieves a 26.3 score at pass@2 while costing just $36. Claude Sonnet 4.6 scores 23.7 at $549, and Claude Opus 4.6 hits 39.6 at a staggering $1,650. That's not a typo, Leanstral delivers competitive formal verification at 1/46th the cost of the best closed-source alternative.
The Efficiency Paradox: Doing More With Less (Output)
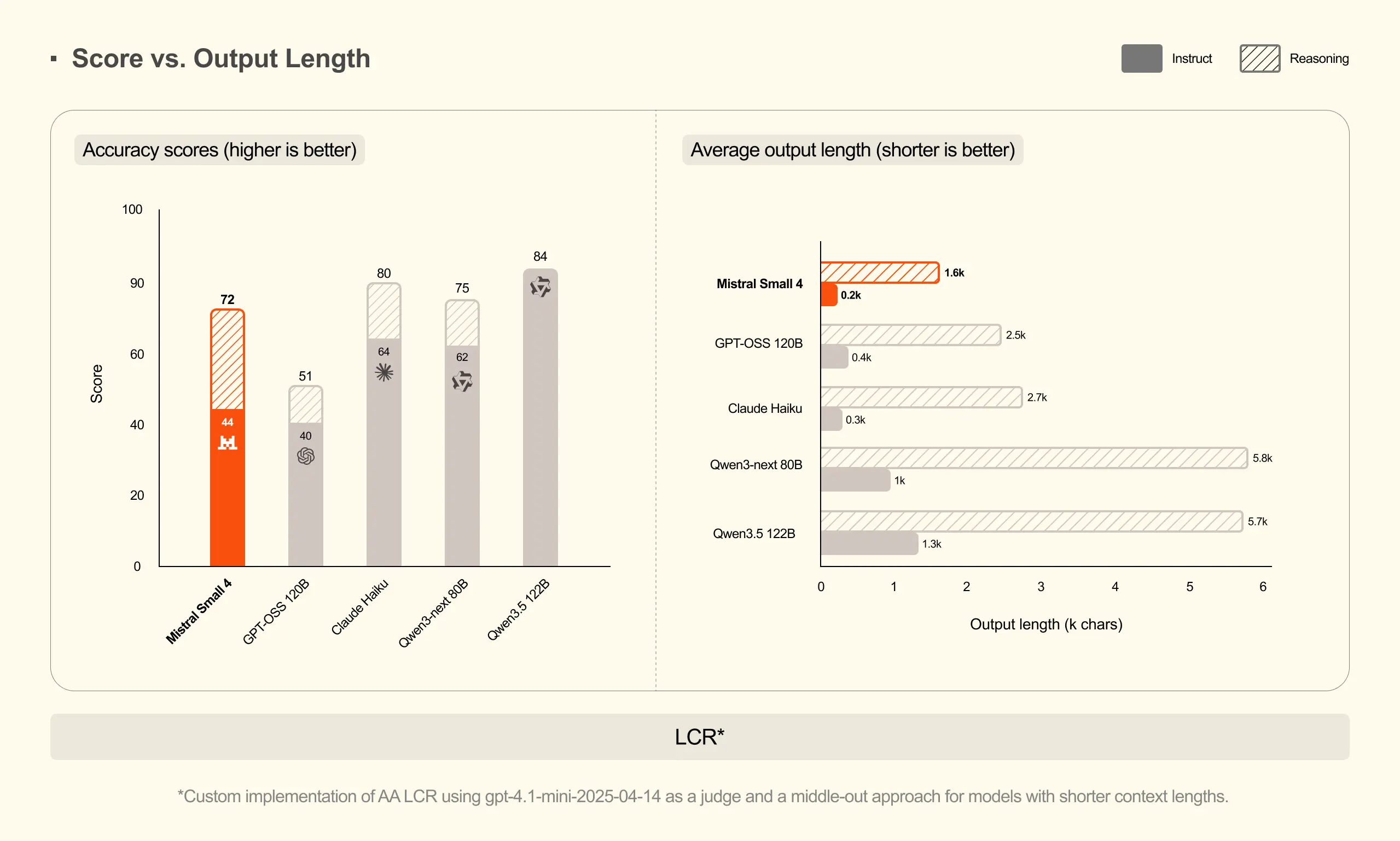
Where Leanstral really embarrasses the competition is in output efficiency. On the AA LCR benchmark, Mistral Small 4 scores 0.72 with just 1,600 characters of output, while Qwen models require 3.5-4x more tokens (5,800-6,100 characters) to achieve similar performance. On LiveCodeBench, it outperforms GPT-OSS 120B while generating 20% less output.
This isn't just about saving tokens, it's about signal-to-noise ratio. In formal verification, extraneous output isn't just wasteful, it's dangerous. Every unnecessary character is a potential source of confusion when you're proving the correctness of cryptographic implementations or distributed systems protocols.
The model also supports multimodal inputs (text and image), meaning you can feed it screenshots of mathematical notation or whiteboard diagrams and have it generate the corresponding formal specifications. It's multilingual, handling everything from English to Arabic, and maintains strong adherence to system prompts, critical when you're specifying the exact logical framework for a proof.
From Vibe Coding to Proof Engineering: The Cultural Shift
The Hacker News crowd immediately latched onto the implications: this isn't just a new model, it's a potential paradigm shift in how we write software. As one commenter noted, “Trustworthy vibe coding” is an oxymoron that Leanstral might actually resolve.
The traditional software development cycle, write code, write tests, hope the tests cover the edge cases, ship to production, pray, is fundamentally probabilistic. Leanstral offers a deterministic alternative: specify your properties in Lean 4, let the agent generate proofs that those properties hold, and deploy with mathematical certainty.
Consider the case study from Mistral's announcement: when fed a real-world StackExchange question about a Lean 4 script that stopped compiling in version 4.29.0-rc6, Leanstral didn't just guess at a fix. It built test code to recreate the failing environment, diagnosed the issue with definitional equality, and correctly identified that using def instead of abbrev was blocking the rw tactic from matching patterns. The fix, swap def for abbrev, was trivial, but the reasoning was sound and verifiable.
This is the antithesis of the “move fast and break things” philosophy that has dominated Silicon Valley for two decades. It's also exactly what community feedback and reliability on coding tools has been demanding: agents that don't just write code, but verify it.
Deployment: Actually Running the Beast
For a 119B-parameter model, Leanstral is surprisingly deployable, if you have the hardware. The MoE architecture means only 6.5B parameters are active per token, making inference feasible on high-end consumer hardware (though you'll want 64GB+ RAM and a beefy GPU).
Mistral provides a custom Docker image for vLLM deployment:
docker pull mistralllm/vllm-ms4:latest
docker run -it mistralllm/vllm-ms4:latestFor local serving, the recommended vLLM configuration uses tensor parallelism and FlashAttention:
vllm serve mistralai/Leanstral-2603 \
--max-model-len 200000 \
--tensor-parallel-size 4 \
--attention-backend FLASH_ATTN_MLA \
--tool-call-parser mistral \
--enable-auto-tool-choice \
--reasoning-parser mistralThe model integrates directly into Mistral Vibe (version 2.5.0+) with a simple /leanstall command, adding a dedicated “lean” mode alongside the standard coding agents. For those tracking the feasibility of running reasoning models locally, this represents a significant step up in capability, though you'll need more than a single GPU to run it comfortably.
The Open Source Gambit
Mistral continues its company-wide open-source licensing strategy with Leanstral, releasing the weights under Apache 2.0. This isn't altruism, it's a calculated bet that the future of AI infrastructure belongs to verifiable, inspectable systems rather than black-box APIs.
In an era where European enterprises are increasingly wary of sending proprietary code to American cloud providers (and dealing with the CLOUD Act implications), Leanstral offers a compelling alternative: a state-of-the-art formal verification agent that runs entirely on-premise, costs a fraction of the competition, and can be fine-tuned for specific domain requirements.
The model also supports arbitrary MCPs (Model Context Protocols) through Vibe, specifically optimized for lean-lsp-mcp, allowing it to interact with the Lean Language Server for real-time proof state inspection. This isn't just code generation, it's a full-fledged proof engineering environment.
The Verdict: Proof or Perish?
Leanstral won't replace your React boilerplate generator, and it's not going to write your CRUD apps. But for mission-critical systems, cryptographic implementations, distributed consensus algorithms, financial transaction processors, it represents a fundamental shift from “we tested it” to “we proved it.”
At $18 for a pass@1 attempt versus $1,650 for Claude Opus, the economics alone make formal verification accessible to teams that previously couldn't afford it. When you can run 90 verification attempts for the price of one Opus run, suddenly “prove before you ship” becomes a viable development methodology rather than a luxury.
The “vibe coding” crowd will hate this. They'll complain that it's slower, that it requires thinking about specifications upfront, that mathematics is hard. But as one Reddit user noted in the release thread: “Automated theorem provers running on a $5k piece of hardware is a cool version of the future.”
Indeed. And for the rest of us, those tired of debugging race conditions at 3 AM, those who've watched production systems crash because of edge cases the tests missed, those who actually care about correctness, Leanstral isn't just a new model. It's a declaration of war against technical debt itself.
Time to prove your code, or get out of the way.



