The lakehouse architecture promised to unify data lakes and warehouses, but somewhere between the conference keynote and your first production incident, the reality sets in: open table formats aren’t magic, they’re infrastructure with opinions. Apache Iceberg has emerged as the format of choice for teams wanting to escape vendor lock-in, yet the migration path is littered with operational landmines that vendor case studies conveniently omit.
Why Teams Actually Pull the Trigger
Let’s dispense with the fiction that most Iceberg adoptions start with rigorous technical evaluation. Many implementations trace back to architecture review meetings where someone cited a Databricks blog post or declared that raw Parquet tables were no longer sufficient. The legitimate drivers, however, are harder to ignore once you hit scale.
Teams managing trillions of rows, the ones actually hitting the limits of traditional warehouses, cite cost efficiency at scale and multi-engine access as primary motivators. When your ML team needs Spark while your analysts demand BigQuery, and neither group wants to wait for ETL pipelines to sync copies, Iceberg’s promise of a single source of truth becomes compelling. Snapshot isolation and time-travel capabilities also simplify audit trails and CDC (Change Data Capture) processing, eliminating the need to maintain separate changelog tables for compliance.
The “bring your own compute” model particularly appeals to platform teams tired of mediating resource conflicts between data scientists and BI developers. By decoupling storage from compute, teams can let different groups manage their own preferences while maintaining centralized governance through the catalog.
The Engine Compatibility Maze
The multi-engine dream quickly encounters reality when you discover that not all Iceberg implementations are created equal. Different compute engines support different operations, some can’t handle DDL statements, others lack predicate pushdown, and write capabilities vary wildly depending on whether you’re using the REST catalog, S3 Tables, or Hive metastore integrations.
Single-node engines like DuckDB and Polars have matured significantly thanks to PyIceberg, offering strong read performance for interactive analytics. However, write operations remain a patchwork of capabilities. Spark provides the most comprehensive feature set, but requires careful version alignment between the Iceberg runtime and catalog server. Trino offers excellent query performance but may lag on certain DDL operations or advanced table features.
This fragmentation creates a governance nightmare. When comparing Apache Iceberg and Delta Lake, one critical distinction emerges: Delta’s ecosystem is more mature but locked to Databricks’ implementation outside their platform, while Iceberg’s openness creates a compatibility matrix that requires constant verification. Table-level access controls must be implemented through credential vending systems, and ensuring consistent authorization across Spark, BigQuery, Flink, and Trino requires significant engineering investment.
Performance: The Benchmark Reality Check
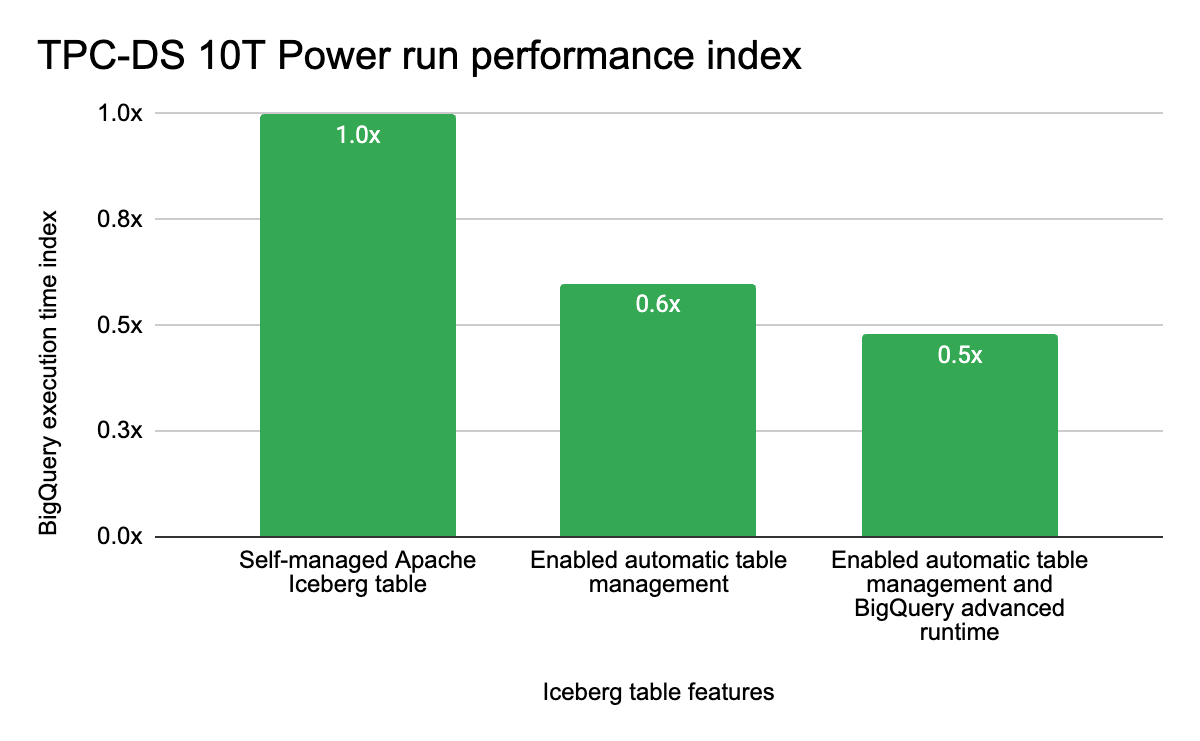
Vendors love throwing around performance numbers, but the self-managed reality is sobering. Google’s internal TPC-DS 10T benchmarks reveal that a fully self-managed Iceberg approach leaves significant performance on the table compared to optimized managed solutions. Their Advanced Runtime for BigQuery delivers approximately 2x faster query performance on Iceberg tables versus standard open-source configurations, while Lightning Engine accelerates Spark workloads by over 4x compared to open-source Spark.
The catch? These optimizations require buying into specific platform ecosystems. Automatic table management, including compaction and garbage collection, can improve TPC-DS performance by roughly 40%, but only if you’re willing to delegate those operations to services like BigLake. For teams committed to pure open-source stacks, this creates a dilemma: accept the operational burden of manual optimization or sacrifice the performance gains that justify the migration in the first place.
Partitioning strategies present another optimization trap. While BigQuery now supports time-based partitioning for Iceberg tables, and clustering helps organize Parquet files for optimal pruning, these features require careful schema design upfront. High-cardinality columns and over-partitioning can turn your lakehouse into a metadata scanning nightmare, forcing full table scans when you expected partition pruning.
The Tooling Gap: What You Wish Existed
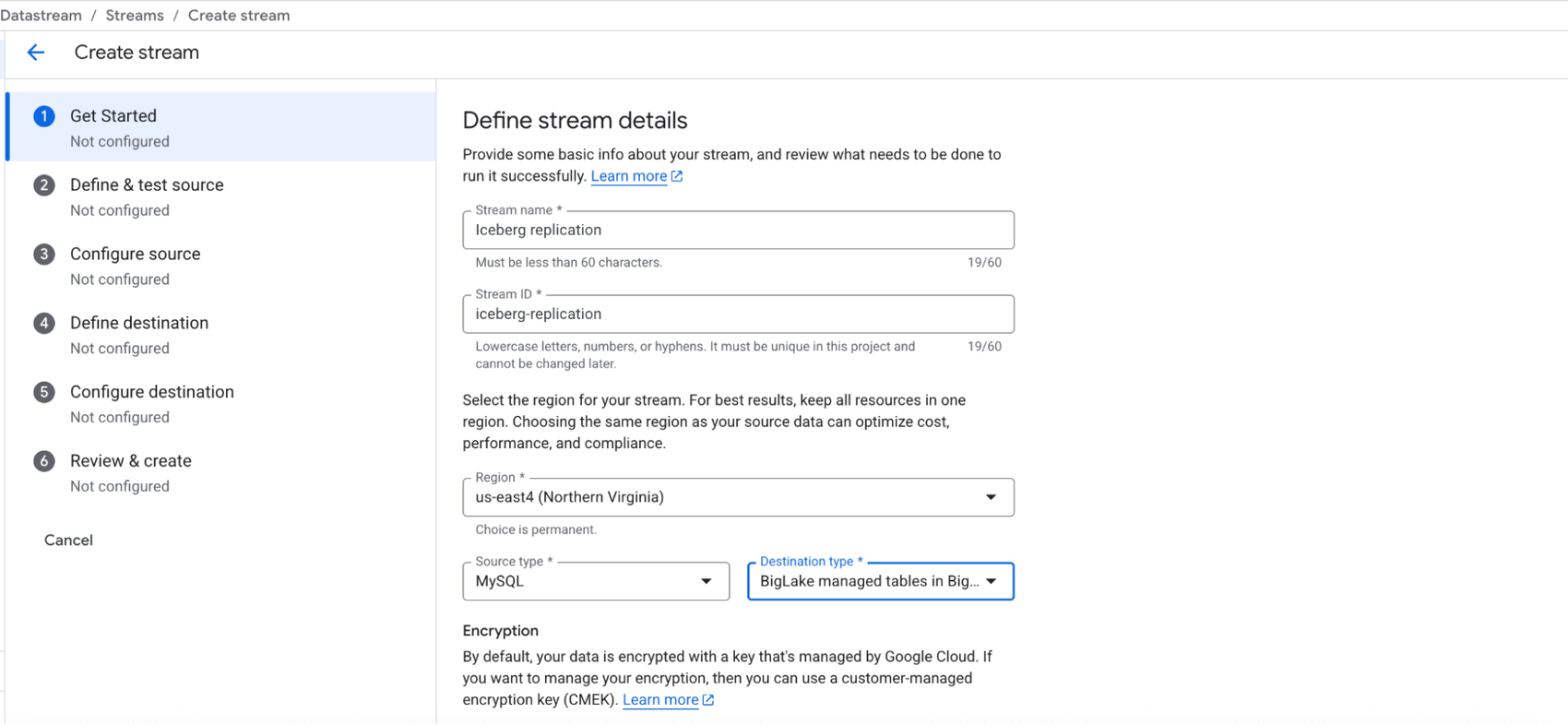
Ask practitioners what they wish existed, and the answers reveal the ecosystem’s immaturity. Unified governance across engines remains aspirational, most teams stitch together Apache Ranger, cloud IAM, and catalog-specific permissions into fragile authorization layers. Architecting event-driven pipelines with CDC into Iceberg tables still requires complex MERGE logic or proprietary replication tools like Datastream, rather than native, format-level change capture.

Multi-statement transactions across tables, essential for maintaining consistency between dimension and fact tables during ETL, have traditionally required application-level coordination. While platforms like BigQuery are introducing ACID transactions spanning multiple Iceberg tables, these capabilities remain preview features in many implementations, leaving teams to manage complex rollback procedures manually when pipelines fail mid-run.
The monitoring and observability tooling specifically designed for Iceberg metadata, tracking table evolution, snapshot growth, and partition skew, remains underdeveloped compared to the rich introspection available in traditional warehouses. Teams often resort to parsing manifest files directly or building custom dashboards atop the Iceberg REST API.
When It Actually Makes Sense
Despite these challenges, Iceberg shines in specific architectural contexts. If you’re evaluating open formats versus managed platforms and your data volumes justify the operational overhead, think trillions of rows where warehouse costs scale linearly into six figures monthly, the format’s efficiency wins. Similarly, if your organization runs diverse analytical workloads requiring Spark for ML, Trino for ad-hoc queries, and BigQuery for BI, all against the same datasets, the engineering investment pays dividends in eliminated data duplication and ETL maintenance.
Teams succeeding with Iceberg share common traits: they have dedicated platform engineering resources to manage compaction and optimization, they implement rigorous schema evolution policies upfront, and they treat the table format as infrastructure requiring SRE-level attention rather than a drop-in replacement for Parquet files.
The Verdict
Iceberg isn’t a free lunch, it’s a trade-off between vendor independence and operational complexity. The format delivers on its promise of open, multi-engine data access, but extracting production-grade performance requires either significant engineering investment or strategic adoption of managed services that handle the optimization burden.
Before migrating, audit whether you’re solving a real scalability problem or just chasing benchmark claims that don’t reflect your workload patterns. If your data fits in a traditional warehouse and your team lacks platform engineering bandwidth, the operational tax of managing compaction, engine compatibility, and governance fragmentation may outweigh the benefits of format openness. But for teams hitting the limits of closed systems and willing to pay the infrastructure tax, Iceberg remains the most pragmatic path to a truly open lakehouse architecture.