The Momentum Reversal Nobody Saw Coming
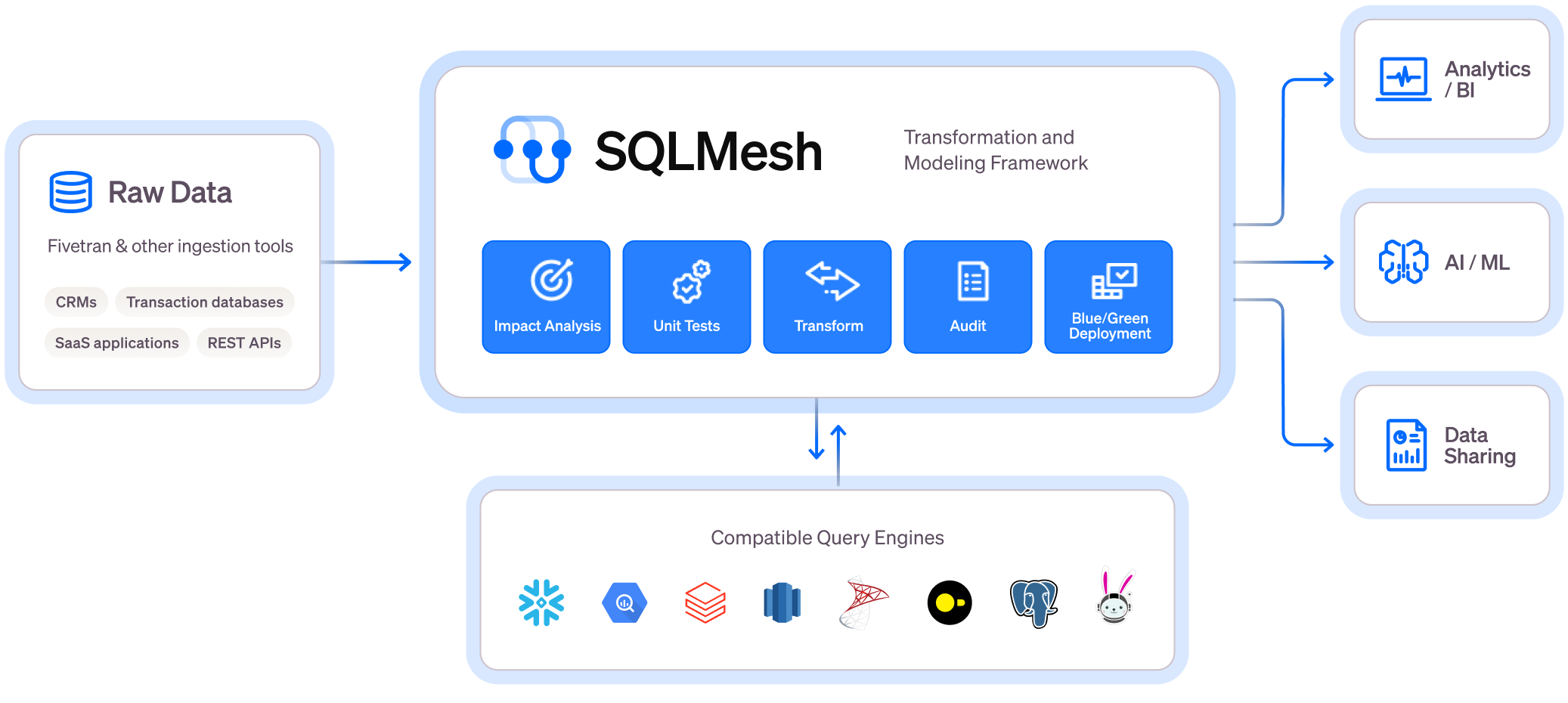
When Tobiko Data built SQLMesh, they didn’t just ship another transformation tool. They mounted a direct assault on dbt’s core architecture. dbt is a text templater, it stitches Jinja strings together and hopes the warehouse understands the result. SQLMesh, via its SQLGlot engine, parses SQL into an Abstract Syntax Tree (AST) before execution. It knows your columns, your aliases, your joins. It can trace lineage natively, run dry plans that preview exact impact, and spin up virtual data environments without copying a single row.
For a while, it felt like an insurgency. Then dbt started moving faster than expected, and SQLMesh’s velocity did the opposite.
Following its donation to the Linux Foundation in March 2026, SQLMesh’s commit activity cratered. Developer sentiment on forums suggests this wasn’t a charitable act of corporate altruism but rather a soft landing after a quiet absorption by Fivetran, who already swallowed Census and is now folding dbt into its empire under the “dbt Platform” rebrand. concerns about dbt’s open-source future compared to SQLMesh
The practical impact is stark. Teams that bet on SQLMesh as the future-proof alternative are discovering that the “future” requires substantially more hands-on maintenance than the sales pitch implied.
dbt’s Counter-Attack Is Working
Let’s be blunt about the feature race: dbt is winning it right now. The Uvik Data Engineering Tool Score (UDETS) for 2026 puts dbt Core at 4.7 across adoption, DX, and enterprise readiness, while SQLMesh languishes at 4.1, a gap driven largely by community momentum and ecosystem maturity.
| Tool | OSS? | Best For | Strength |
|---|---|---|---|
| dbt Core | Yes | SQL-based transformation | The de facto standard, testing + docs built-in |
| SQLMesh | Yes | dbt successor contender | Virtual envs, column-level lineage |
The decision rule from that same analysis is unambiguous: dbt is the default transformation standard, SQLMesh remains the most credible challenger. Challenger, not successor.
The arrival of dbt Fusion, a Rust-based execution engine, has closed the performance gap that SQLMesh evangelists loved to highlight. Meanwhile, dbt Labs keeps shipping integrations and UI improvements at a clip that makes SQLMesh’s roadmap look stagnant. The confusion around dbt’s product branding hasn’t slowed its technical momentum, if anything, the reconsolidation under “dbt Platform” has streamlined what was becoming a fragmented product maze.
Where dbt has genuinely leapfrogged the challenger is in the one domain that matters most in 2026: artificial intelligence integration.
The LLM Flywheel Has Declared a Winner
This is where the conversation gets genuinely controversial. In 2026, LLMs are still giving dbt solutions to SQLMesh problems. Ask Copilot, Claude, or GPT-4o to debug a SQLMesh pipeline issue, and you’ll get perfectly formatted Jinja macros and dbt run commands. You have to explicitly prompt the model to consult SQLMesh’s official documentation via Context7 before it stops hallucinating dbt syntax.
This isn’t a minor annoyance. It is an accelerating competitive advantage. LLM training data is overwhelmingly biased toward dbt because millions of practitioners have written dbt code, blog posts, and Stack Overflow answers for years. SQLMesh’s narrower footprint means its patterns barely register in the latent space. The result? governance of AI tools like LLMs in data workflows isn’t just about security policy, it’s about which tool gets free coding labor from every AI assistant on the planet.
SQLMesh’s Slack AI bot reportedly helps users navigate the gaps, but that’s a band-aid on a structural problem. When your AI-assisted development workflow defaults to the incumbent’s patterns, the incumbent’s adoption flywheel spins faster. SQLMesh engineers are effectively paying a cognitive tax every time they open an AI chat window.
Where SQLMesh Still Punches Above Its Weight
Despite the stalling momentum, writing SQLMesh off would be premature. There are three architectural areas where it remains objectively superior to dbt Core, and dbt has not yet shipped a credible answer.
Native Branching and Virtual Environments
dbt development is physical and expensive. You build to a target schema like analytics_dev_yourname, which means copying or rebuilding production data into personal sandboxes. At scale, this is a warehouse budget firehose.
SQLMesh treats environments as virtual pointer layers. When you run sqlmesh plan dev, it doesn’t copy data, it creates lightweight views that point to existing physical tables. Only modified models get new physical storage, everything else is a reference swap.
sqlmesh plan dev
The output shows exactly what will change before a single compute dollar is spent:
======================================================================
Plan: dev
======================================================================
New environment `dev` will be created from `prod`
Added Models:
├── jaffle_shop.customers (Full Refresh)
└── jaffle_shop.orders (Full Refresh)
Apply - Create dev environment and backfill models [y/n]:
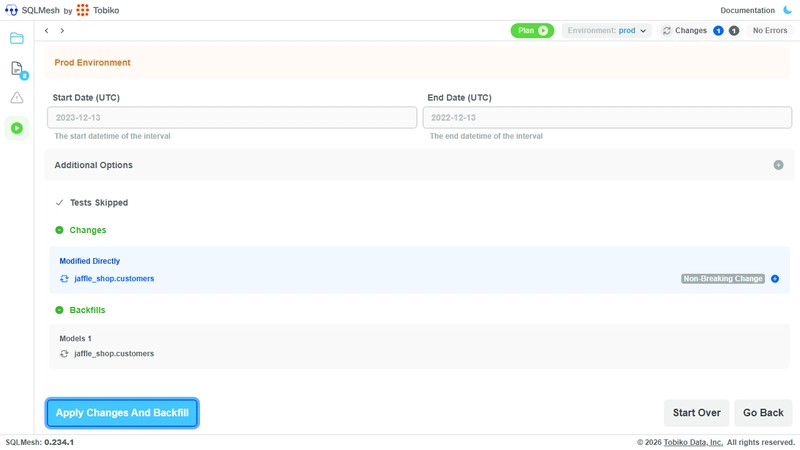
Review the impact, confirm, and apply:
This isn’t just cost optimization. It’s a fundamentally different approach to CI/CD. SQLMesh’s native GitHub Action spins up temporary PR environments, posts the exact execution plan as a comment, and guarantees that main is always deployable. dbt CI remains comparatively coarse-grained.
Column-Level Lineage Without the Tax
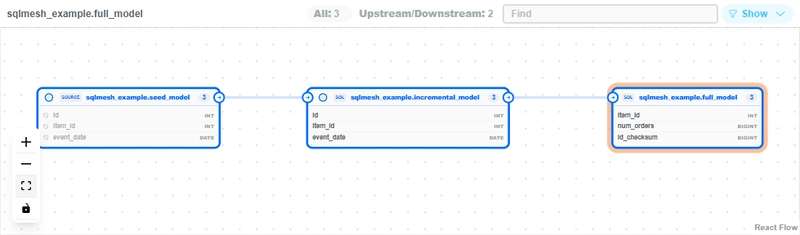
Because SQLMesh parses ASTs rather than templates, it offers column-level lineage natively. In dbt, tracing a column through aliases and CTEs requires a global text search and a prayer. SQLMesh’s UI traces the exact path:
`raw_customers.email` (PII) -> `stg_customers.email` -> `customers.email`
This makes impact analysis for deprecations and PII compliance genuinely trivial instead of a multi-hour archaeology project.
The Consolidated MODEL Block
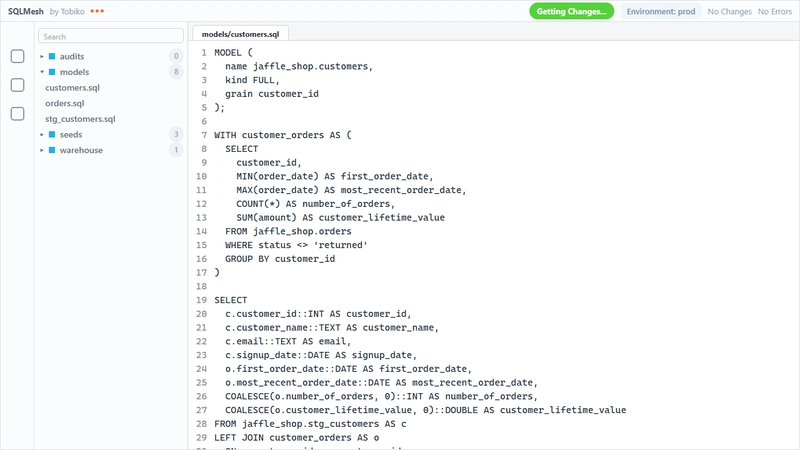
SQLMesh eliminates the split-brain problem of dbt, where your SQL lives in .sql files but your tests and configuration are scattered across YAML. The MODEL block encapsulates metadata, grain, dependencies, and materialization in one place:
MODEL (
name jaffle_shop.customers,
kind FULL,
grain customer_id
);
-- SQL logic follows, with automatic dependency detection
-- No Jinja refs, no separate schema.yml
Running sqlmesh audit auto-generates uniqueness and not-null checks from the grain declaration. It’s cleaner, and for teams migrating from dbt, SQLMesh can parse existing Jinja models directly via its dbt adapter.
The Implementation Reality Check
If SQLMesh’s architecture is so sound, why is the community anxious? Because architectural elegance doesn’t pay the debugging bills.
The Snowflake dialect remains incomplete in 2026. Multi-project orchestration is clunky, you can plan across projects to align lineage, but you can’t run sqlmesh run -p projectpath1 -p projectpath2 in a single command. The state database concept, while theoretically powerful, has earned a reputation as a source of painful debugging sessions when things go sideways.
Documentation is another sore spot. Users report that when something breaks, the official docs often leave them stranded, resorting to the Slack AI bot for answers. That’s a dangerous dependency for a tool positioning itself as production-grade infrastructure.
These aren’t fatal flaws, but they are friction points that accumulate fast in enterprise environments. When UVik maps the 2026 transformation layer, the decision rule is unambiguous: dbt is the default standard. SQLMesh is the credible alternative for teams that prioritize compute economics and lineage precision over ecosystem breadth.
Making the Call for Greenfield Projects
So where does that leave you if you’re picking a tool today?
Choose dbt if:
- You want maximal ecosystem compatibility and LLM assistance out of the box
- Your team is analyst-heavy and comfortable with Jinja templating
- You need enterprise support and a vendor-backed roadmap (even if that vendor is now Fivetran)
- You’re already inside the dbt Platform/Cloud ecosystem and want Fusion’s performance gains
Choose SQLMesh if:
- Your warehouse bill is bleeding from dev environment copies
- You need column-level lineage for compliance or data governance
- Your engineers want Terraform-style plan/apply guardrails before touching production
- You’re willing to trade ecosystem polish for architectural correctness, and have the patience to debug edge cases
For most teams in 2026, dbt is the pragmatic default. The skills strategy in the AI salary landscape increasingly rewards tool fluency over tool purity, and dbt’s market dominance is self-reinforcing.
SQLMesh didn’t die. It just stopped being the obvious next step. In a tooling market where LLM integration has become table stakes, being technically superior isn’t enough when the AI assistants keep writing dbt macros for your SQLMesh project. The challenger’s best hope lies in the Linux Foundation governance proving it can sustain development without Tobiko Data’s commercial engine. Until then, the incumbent accelerates.