The medallion architecture is supposed to set you free. Bronze captures raw truth. Silver cleans and conforms. Gold serves business magic. It’s a beautiful, three-tiered utopia that every Databricks tutorial sells like a miracle cure for data chaos. But here’s what the glossy architectural diagrams don’t show: the silver layer can become a straightjacket that leaves your data teams burning out and your analysts screaming into Power BI dashboards.
A recent Reddit post titled “Silver Nightmare” (scoring 29 upvotes in under 28 hours) captures the pain perfectly. A junior data engineer at a large organization describes a setup where the silver layer is a single, massive schema. Every source, SAP, CRM, PIM, is crammed into the same tables. Customers from one system sit next to customers from another, distinguished only by a hashed surrogate key that couples every record to its source system forever. The result? A data layer that feels less like a trusted foundation and more like an active obstacle.
This isn’t a one-off horror story. It’s a symptom of a deeper architectural tension that the medallion pattern creates when implemented with too much rigidity and too little empathy for downstream consumers.
The Architecture That Promised Freedom but Delivered a Monolith
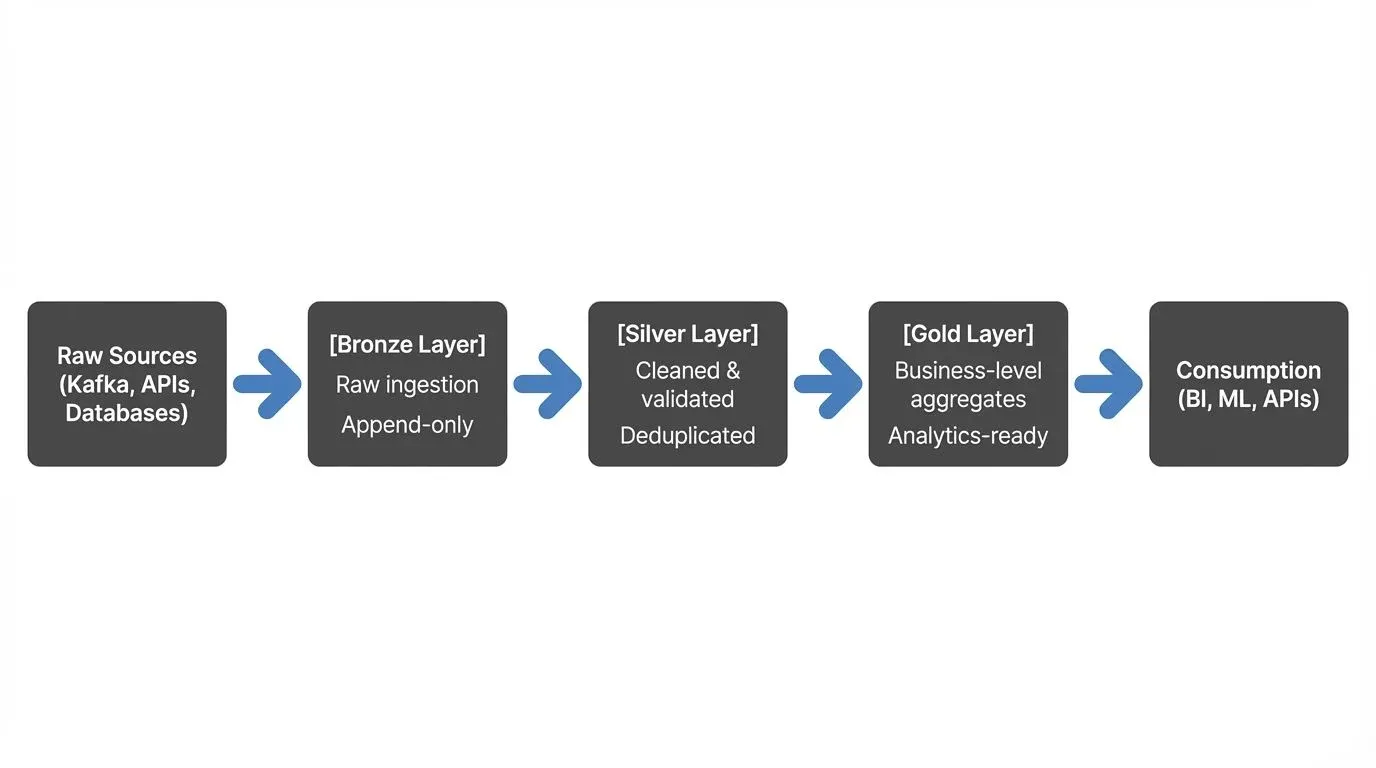
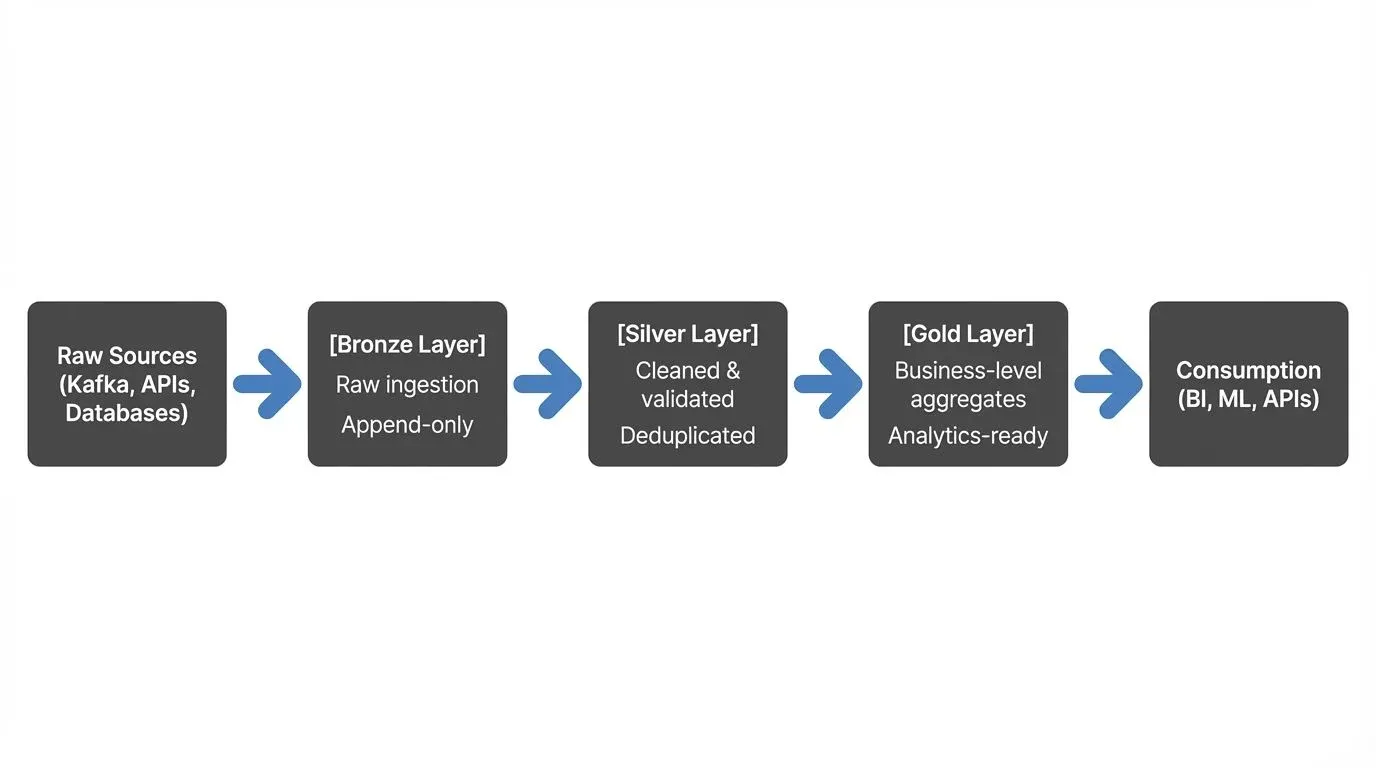
The medallion architecture is a design pattern that organizes a data lake into three layers with distinct purposes. Bronze is the raw landing zone, append-only, schema-on-read, preserve everything. Silver is the cleaning stage, deduplication, type enforcement, data quality gates. Gold is the business layer, star schemas, aggregated metrics, ML feature tables.
In theory, this separation of concerns is elegant. In practice, the silver layer often becomes a monolithic bottleneck that violates the very principles it was designed to enforce.
Look at the common anti-patterns that emerge when organizations implement silver:
| Anti-Pattern | Impact |
|---|---|
| Single massive schema for all sources | Every downstream team fights over schema changes, onboarding new data requires negotiation with every existing consumer |
| Surrogate keys hashed from source-specific natural keys | Master data changes become a nightmare, records from different systems that represent the same entity cannot be reconciled |
| Rigid star schema enforced at silver | Forces business logic into the cleaning layer, prevents exploratory analytics that don’t fit the dimensional mold |
| No quarantine layer for bad records | Records silently dropped or corrupting downstream tables, data quality issues invisible until reporting breaks |
The junior engineer’s list of grievances from the Reddit post reads like a checklist of everything that can go wrong:
“The silver layer is one massive schema for everything… Sources are all mixed into the same table… Tables are all split into fact/dimension modeling and must follow a star schema… All dimensions in fact tables are surrogate keys which are really just a hashed natural key… Even if a business key is a global field, so every value is coupled tightly with its source.”
This isn’t a silver layer. It’s a data swamp dressed up in Delta Lake clothing.
When Hub-and-Spoke Becomes Hub-and-Stuck
The hub-and-spoke model is seductive. A central data team owns the silver layer as the single source of truth. Multiple “spokes”, business domains, analytics teams, data science groups, build gold layers on top. In theory, this creates consistency. In practice, it creates a dependency hell where every spoke’s velocity is determined by the slowest-moving part of the hub.
The World Bank Group faced a version of this problem. As described in their Databricks case study, they had “tens of millions of documents in its knowledge repositories and three million publication downloads every month.” Their bottleneck wasn’t a rigid silver layer, but the challenge was structurally similar: centralized knowledge that couldn’t be accessed efficiently by distributed teams.
The solution the World Bank Group found was not to tighten central control but to build an agentic layer on top. They created an intent classifier, a domain classifier, and a query decomposer that could route questions to the right underlying data assets without requiring all data to pass through a single monolithic transformation.
This is the lesson that many enterprise data teams miss. The goal of silver is not to make all data look the same. The goal is to make data trustworthy enough that it can be used in different ways by different teams without each team needing to reinvent the cleaning process.
The Surrogate Key Trap
The most pernicious design choice in the “Silver Nightmare” post is the surrogate key strategy. Hashing (business value + source) to create a unique identifier seems reasonable at first glance. It preserves lineage, you always know which source a record came from. But it creates a fundamental problem: it prevents entity resolution across sources.
If a customer exists in both the CRM and the ERP system, with slightly different addresses and phone numbers, the surrogate key produces two distinct records. The silver layer has no mechanism to recognize them as the same entity. Every downstream consumer must implement their own entity resolution logic, which defeats the entire purpose of having a trusted intermediate layer.
One commenter on the Reddit thread noted: “It sounds like maybe there is no entity resolution/reconciliation from bronze to silver to try to define ‘the truth.'” That’s the core issue. Silver should be where you resolve entities, not where you perpetuate fragmentation.
Star Schema: The Wrong Abstraction for the Right Problem
Kimball dimensional modeling is a legitimate and powerful technique for data warehousing. But applying it rigidly at the silver layer creates friction that burns out junior engineers and slows down innovation.
The silver layer should not be forcing business-specific modeling choices. Silver should be source-aligned, a cleaned, standardized version of what the source systems provide. Business logic, dimensional modeling, and aggregation belong in gold, where they can be tailored to specific consumption patterns.
The Conduktor guide to data lake zones defines silver correctly: “The Silver layer represents your cleaned, validated, and standardized data. This is where data engineering rigor comes into play, transforming raw data into a reliable foundation for analytics.” Note the phrase “foundation for analytics”, not “final shape for analytics.”
When you enforce star schema at silver, you’re making assumptions about consumption patterns that may not hold for all downstream use cases. Data scientists need different shapes than Power BI dashboards. ML feature engineering needs different structures than financial reporting. Silver should provide clean, reliable building blocks, not finished products.
The Quarantine Pattern: Because Sometimes Data Is Just Bad
One of the most common anti-patterns in medallion implementations is the silent failure. Records that fail validation are simply dropped. Engineers never see them. Analysts never know they’re missing. The data quality scorecard looks great because the bad data was invisible.
The DriveDataScience guide on medallion architecture in Azure calls this out specifically: “No quarantine layer, bad records silently dropped or corrupting Silver. Always route bad data to a quarantine folder for investigation.”
Here’s the quarantine pattern in practice:
# During Silver processing, separate good and bad records
df_good = df_bronze.filter(
col("email").rlike("^.+@.+\..+$") & col("customer_id").isNotNull()
)
df_bad = df_bronze.filter(
~col("email").rlike("^.+@.+\..+$") | col("customer_id").isNull()
)
df_good.write.format("delta").mode("append").save(".../silver/customers/")
df_bad.write.format("delta").mode("append").save(".../quarantine/customers/")
print(f"Good: {df_good.count()}, Quarantined: {df_bad.count()}")
This pattern forces transparency. Engineers can see how many records are failing and why. Source system owners have visibility into data quality issues. And most importantly, downstream consumers know that the data they’re working with has passed known validation gates.
Breaking the Deadlock: Practical Strategies for Silver Layer Sanity
If you’re trapped in a rigid silver layer implementation, or if you’re designing one and want to avoid these traps, here are strategies that work:
1. Separate Schemas Per Source Domain
Don’t put everything in one schema. Create logical separations for each source domain, silver_sap, silver_crm, silver_pim. This allows teams to evolve their schemas independently while still maintaining consistent cleaning standards.
2. Implement Entity Resolution at Silver
The silver layer is the right place to reconcile entities across sources. Build lookup tables that map source-specific identifiers to global business keys. Yes, it’s hard. Yes, it requires business rules. But that’s exactly the work that should happen once, not N times in every gold layer.
3. Keep Silver Source-Aligned, Not Consumer-Aligned
Resist the temptation to model silver for specific consumption patterns. Clean the data. Standardize types. Deduplicate records. Resolve entities. Then let gold layers shape the data for their specific needs.
4. Build a Quarantine Layer
Silent data loss is a governance failure. Every pipeline that transforms bronze to silver should quarantine records that fail validation, along with metadata about why they failed and when.
5. Enable Direct Bronze Access for Supervised Use Cases
Data scientists who understand the data model should be able to read directly from bronze when they need raw detail that silver has aggregated away. The blanket rule “analysts should never read bronze” is governance theater, not engineering wisdom. Provide training and guardrails instead of hard blocks.
The Real Cost of Rigidity
The metadata unification challenges that plague silver layer implementations are not just technical problems. They’re human problems. The junior engineer who posted “Silver Nightmare” isn’t complaining about a technical nuance. They’re burned out. They feel like “it feels impossible to achieve anything.”
When your architecture makes competent engineers feel incompetent, the problem isn’t the engineer. The problem is the architecture.
The enterprise data chaos that results from overly rigid governance creates a predictable response: teams bypass the system entirely. Analysts export data to Excel. Data scientists build pipelines that read from bronze directly. The “single source of truth” becomes the “single source of delays.”
Organizations that successfully implement the medallion pattern treat silver as a negotiated contract between upstream data producers and downstream consumers. Governance is continuous, not static. Schemas evolve based on usage patterns. The team that owns silver has a mandate to iterate, not just enforce.
The Bottom Line
The medallion architecture is not a product you install. It’s a discipline you practice. The silver layer can be your greatest asset or your biggest bottleneck, depending entirely on how rigidly you define it.
If your silver layer feels like a deadlock, step back and ask the hard questions: Are you modeling for control or for velocity? Are you enforcing standards that serve governance or that serve inertia? Are you building a foundation for analytics or a cage for your engineers?
The teams that succeed with medallion are the ones that recognize silver as a living layer that must evolve with the business. The teams that fail are the ones that treat it as a monument to architectural purity.
Which approach does your organization use? If you’re fighting the silver layer deadlock, you’re not alone, and you’re probably right to challenge it.