Something strange is happening in data engineering teams. After years of treating PySpark as the default hammer for every transformation nail, practitioners are increasingly reaching for plain SQL when they hit the final stage of their pipelines. The Gold layer, that last refinement step before data reaches analysts and dashboards, is becoming SQL territory, and the reasons have almost nothing to do with query optimization.
This shift challenges a long-held assumption in data engineering: that code-heavy solutions are inherently more powerful, flexible, and "serious" than declarative alternatives. The reality emerging from production systems suggests the opposite. For the specific work of organizing cleaned data into final facts and dimensions, SQL isn’t just sufficient, it’s strategically superior.
The Accidental Consensus
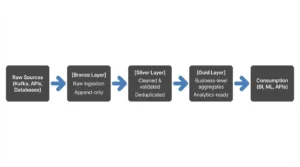
A recent observation from someone learning Databricks captured what many experienced engineers already knew: "every industry-ready pipeline I’m seeing almost always has SQL in the gold layer rather than PySpark." The pattern they described, Bronze (PySpark), Silver (PySpark + SQL), Gold (SQL), reflects a broader architectural evolution that has developed organically rather than through vendor prescription.
The explanation is straightforward once you untangle it. Gold layer transformations are fundamentally different from earlier stages. Where Bronze handles raw ingestion with schema flexibility and Silver manages complex cleaning, deduplication, and business rule enforcement, Gold performs a narrower function: organizing already-validated data into final structures optimized for consumption.
As one practitioner noted, Gold should have "basically zero complex code." It’s about organizing Silver data into facts and dimensions, and for that specific task, SQL is not just adequate, it’s highly performant and dramatically more maintainable.
Why PySpark Loses Its Edge
The technical case for PySpark weakens considerably at the Gold layer for several interconnected reasons.
First, the complexity gradient flattens. PySpark’s real power, distributed processing, custom UDFs, integration with Python libraries, complex error handling, addresses problems that have largely been solved by the time data reaches Gold. The heavy lifting of handling malformed records, managing schema evolution, and enforcing data quality gates belongs in Silver. What’s left for Gold is primarily aggregation, filtering, and projection: operations where SQL’s declarative nature is actually an advantage.
Second, the execution model converges. Under Databricks’ runtime, PySpark DataFrame operations and Spark SQL become the same query plan very early in execution. The performance difference between df.groupBy().agg() and a GROUP BY query is negligible. What differs is readability, debuggability, and who can understand the code six months later.
Third, and most critically, the maintenance burden shifts. PySpark code requires Python proficiency to modify. SQL requires SQL proficiency. The latter pool is vastly larger in most organizations, including the analysts and business users who are often the Gold layer’s primary consumers. When a metric definition needs adjustment, the SQL query can often be modified directly by the team that understands the business context. The PySpark implementation creates a ticket, a handoff, and a delay.
The Medallion Architecture Skeptics
Not everyone accepts the framing that makes this shift meaningful. The Medallion Architecture itself, Bronze, Silver, Gold, has drawn significant criticism as "a silly marketing term invented a few years ago by Databricks" that rebrands the venerable layered architecture pattern without adding conceptual clarity.
Critics argue that the terminology creates confusion about what "the layer" actually represents. Is it the data representation or the code that produces it? If Gold tables can be consumed or produced with any tool, why constrain the implementation choice based on an arbitrary metaphor?
These objections have merit, but they don’t invalidate the underlying pattern. Whether you call it Gold layer, semantic layer, or "the place where analysts get their tables", there’s a genuine architectural boundary where transformation complexity gives way to presentation simplicity. The SQL preference at this boundary reflects practical experience rather than marketing compliance.
Some teams have found clearer terminology helps. Describing the tiers as import, staging, and semantic, rather than precious metals, strips away the metaphorical baggage while preserving the functional separation.
The Hidden Cost of Code
The PySpark-to-SQL transition reveals a broader tension in data engineering between engineering purity and operational sustainability. PySpark offers genuine capabilities SQL cannot match: complex business logic, external API integration, sophisticated error handling, access to Python’s entire library ecosystem. For problems requiring these capabilities, PySpark is the correct choice.
But capability and appropriateness are different dimensions. The question isn’t whether PySpark can handle Gold layer transformations, clearly it can, but whether it should given the total cost of ownership.
Consider the full lifecycle of a Gold table implementation:
| Aspect | PySpark | SQL |
|---|---|---|
| Initial development | Moderate (boilerplate, type handling) | Fast |
| Code review | Requires Spark expertise | Broader reviewer pool |
| Debugging | DAG visualization, driver logs | Direct query execution |
| Business user modification | Rarely possible | Often possible |
| Testing | Framework-dependent, complex | CTE-by-CTE verification |
| Documentation | Separate from code | Often self-documenting |
The SQL advantage compounds over time. A Gold layer implemented in SQL creates less organizational dependency on specific individuals, reduces the friction of iterative refinement, and aligns the implementation tool with the consumption tool, analysts query the same language they would use to explore the data.
When PySpark Still Belongs in Gold
The SQL preference is a tendency, not a rule. There remain legitimate reasons to maintain PySpark through the Gold layer.
Complex derived metrics involving multi-step business logic may be cleaner in Python, especially when that logic is shared with other systems. Data products requiring API enrichment, external validation, or ML feature engineering at serving time need PySpark’s integration capabilities. Teams with strong Python data engineering cultures may find the consistency of a single language across layers outweighs the SQL advantages.
Some practitioners advocate for consistency above all: "coding should be done equally between the layers. Either do SQL or PySpark, and only use the other ones when there is a special reason to require it. But don’t mix it wildly for no good reason."
This position has organizational benefits, reduced context switching, simpler hiring profiles, unified testing approaches. But it risks subordinating layer-appropriate design to administrative convenience. The "special reason" for SQL in Gold is that the work has changed character, not that the team prefers one technology.
The Platform Economics
The shift toward SQL in Gold layers intersects with broader platform evolution. Databricks has increasingly positioned DBSQL, its SQL warehouse offering, as a first-class execution environment, not merely a compatibility layer. This creates genuine architectural alternatives: Spark clusters for heavy transformation, SQL endpoints for serving and light aggregation.
The economic implications are substantial. SQL warehouses typically run on smaller, less expensive compute configurations than Spark clusters. They start faster, scale more granularly, and can be paused more aggressively. For workloads that don’t require distributed processing, which describes most Gold layer transformations, the cost differential matters.
More fundamentally, the SQL preference reflects a maturation of the data platform market. Early lakehouse implementations required Spark for virtually everything because the SQL engines weren’t sufficiently capable. Modern platforms have closed that gap for analytical workloads, making the "use the right tool for the job" principle genuinely actionable rather than aspirational.
Implications for Data Engineering Practice
For practitioners, this evolution suggests several actionable shifts.
Reconsider layer boundaries. If your Gold layer contains substantial PySpark, examine whether that complexity belongs there. Complex business logic may be more maintainable in Silver, with Gold performing simpler aggregation. The goal is clean separation: Silver handles "how we understand this data", Gold handles "how we present this understanding."
Invest in SQL sophistication. The SQL appropriate for Gold layers is not basic SELECT * FROM. Modern analytical SQL, CTEs, window functions, pivoting, sophisticated joins, deserves the same engineering attention as Python code. SQL-focused data engineering careers are increasingly viable, and Gold layer implementation is one reason why.
Evaluate platform capabilities honestly. The "Spark or SQL" decision should be driven by actual workload characteristics, not vendor positioning or team preference. PySpark performance limitations driving architectural changes are real in some contexts, in others, they’re imagined constraints that create unnecessary complexity.
Maintain architectural flexibility. The pendulum may swing. New capabilities in Spark SQL, changes in cost structures, or evolution in consumption patterns could alter the optimal choice. Implementations that hard-code PySpark or SQL assumptions throughout the stack create future migration costs.
The Broader Pattern
The Gold layer SQL preference is one manifestation of a larger trend: the reassertion of domain-appropriate tools over platform uniformity. Embedded SQL database alternatives to Spark clusters like DuckDB are challenging assumptions about necessary infrastructure. Legacy data technology shifts and vendor narratives are forcing re-evaluation of once-default choices.
In this context, PySpark’s retreat from the Gold layer isn’t a failure, it’s a sign of ecosystem maturation. The tool is finding its appropriate scope: genuinely complex, large-scale, or integration-heavy transformations where its capabilities justify its complexity. SQL is reclaiming territory where declarative expression and broad accessibility matter more than programmatic flexibility.
The "death of PySpark" framing is overheated. The technology remains essential for substantial portions of the data engineering workload. But its unquestioned dominance of the entire pipeline, from raw ingestion to final presentation, is ending. That’s not a eulogy. It’s a more honest accounting of what different tools do well, and a recognition that the best architecture uses each where it fits.
For Gold layer work, that increasingly means SQL. Not because PySpark can’t do it. Because, finally, teams are asking whether it should.