The data industry has perfected the art of false dichotomies. Either you’re “cloud-native”, stringing together AWS Glue, Athena, and Lake Formation like some kind of infrastructure macramé, or you’ve “sold out” to Databricks, surrendering your architecture to a proprietary platform that promises to solve everything while quietly calculating your exit fees.
The reality? Both paths lead to the same destination: a complex migration project that will consume 18 months of your life and make you question every career decision that led you to this moment.
The Architectural Split Nobody Talks About
AWS and Databricks aren’t competing on features anymore. They’re competing on who owns your metadata.
AWS’s approach is distributed by design. You store data in S3, catalog it with Glue, secure it with Lake Formation, and query it with Athena or Redshift. It’s the Unix philosophy applied to data infrastructure: do one thing well, then pipe it to the next service.
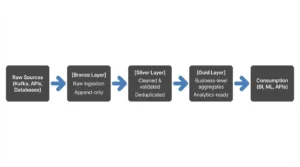
The limitations of raw data lakes and table management systems become apparent when you realize that “schema-on-read” was just a euphemism for “hope nobody changes the underlying Parquet files.” The limitations of raw data lakes and table management systems.
Databricks, conversely, offers the seductive promise of consolidation. One platform for ETL, SQL analytics, ML, and governance. The lakehouse architecture, combining the flexibility of data lakes with warehouse-like performance, sounds like having your cake and eating it too.
Until you read the fine print on Unity Catalog migrations. The migration from legacy Hive Metastore to Unity Catalog isn’t a gentle upgrade—it’s a surgical procedure requiring eight distinct phases: assessment, infrastructure setup, migration planning, table migration, permission mapping, validation, cutover, and decommission.
According to the Unity Catalog Migration Kit, you’ll need to choose between DEEP CLONE (for Delta tables), CTAS (for Parquet/CSV/JSON), or SYNC strategies, each with different risk profiles and rollback procedures.
Key Engineering Insight
Engineers on data engineering forums note that while migration experience looks valuable on a CV, the reality depends heavily on how messy your on-premise legacy setup is. The consensus suggests that proving you can solve business problems matters more than specific tech stack badges, though hiring managers still seem to count AWS services on resumes like scout badges.
The Lock-in Paradox
Here’s where the marketing narratives collapse: you’re locked in either way, but the nature of the lock-in differs fundamentally.
AWS locks you in through architectural complexity. You don’t have a data platform, you have a serverless Rube Goldberg machine of Lambda functions, Step Functions, S3 buckets with lifecycle policies, Glue crawlers, and IAM roles that require a PhD in AWS policy syntax to debug.
Databricks locks you in through workflow consolidation. As noted in recent platform analyses, tool consolidation creates platform concentration risk. If too much of your stack depends on one vendor, migration flexibility shrinks over time.
The platform simplifies tool sprawl, but increases platform dependence. Your notebooks, Delta tables, Unity Catalog permissions, and MLflow experiments form a tightly coupled ecosystem. Moving to open-source Spark isn’t an exit strategy—it’s a downgrade that requires rewriting half your governance layer.
The three-level namespace change (from database.table to catalog.schema.table) seems trivial until you realize it breaks every existing notebook, dashboard, and pipeline reference in your organization. The migration kit recommends running both Hive Metastore and Unity Catalog in parallel for 1-2 weeks to catch missed references, a luxury that requires double the infrastructure costs and operational overhead.
Cost: The Hidden Variable
Surprise Billing Syndrome
Both platforms suffer from “surprise billing syndrome”, but manifest it differently.
AWS data lakes prioritize storage volume and cost over raw query performance. You get cheaper storage, but you pay in engineering hours, tuning Athena query performance, managing Glue ETL jobs, and optimizing S3 partitioning schemes.
The cloud infrastructure cost volatility and scalability challenges aren’t just about compute prices—they’re about the operational tax of maintaining a distributed system where no single component owns the end-to-end user experience. The cloud infrastructure cost volatility and scalability challenges.
Databricks meanwhile, offers compute autoscaling that works beautifully right up until you get the bill. The platform requires Premium or Enterprise plans for Unity Catalog support, and DBR 13.3+ runtimes aren’t free. Without strict governance discipline, including automated cluster termination, workload isolation, and storage optimization, costs drift upward faster than a helium balloon in a thunderstorm.
When to Choose Which
Choose AWS Native When:
- You need granular control over every infrastructure component
- Your team has deep AWS expertise and Terraform fluency
- You want to optimize for specific, narrow use cases (e.g., pure SQL analytics or specific ML services)
- You can tolerate the operational overhead of integrating 5-7 different services
Choose Databricks When:
- Your bottleneck is coordination across data engineering, analytics, and ML teams
- You need ACID transactions and time travel (Delta Lake features) without managing the underlying storage
- You have the platform engineering capacity to enforce naming standards, cost controls, and migration discipline
- You’re willing to trade cloud-agnosticism for unified governance
Avoid Both When:
- Your data fits in a PostgreSQL instance (seriously, stop over-engineering)
- You don’t have dedicated platform engineers or data architects
- You think “lakehouse” is a magic word that eliminates the need for data modeling
The Uncomfortable Truth
The lakehouse architecture, whether implemented via AWS Lake Formation or Databricks Unity Catalog, doesn’t fix messy data. It exposes how messy your company already is.
AWS’s approach lets you blame the integration complexity (“Glue is being weird again”). Databricks forces you to confront the actual problems: undefined data ownership, inconsistent schemas, and analysts who’ve been running SELECT * on terabyte-scale tables since 2019.
The migration to Unity Catalog isn’t just a technical lift—it’s an organizational audit. The assessment phase alone requires cataloging every table, view, and function with metadata, scanning existing permissions, and scoring migration complexity per table.
Governance Reality Check
If your data governance is currently “we think Bob knows where that CSV lives”, Unity Catalog will hold up a mirror you’re not prepared to look into.
Similarly, AWS’s serverless data lake framework promises event-driven, scalable architecture, but requires you to define data structures, schemas, and transformations upfront, or accept that your “data lake” is actually a data swamp with extra steps.
Final Verdict
AWS Approach
The AWS vs. Databricks split isn’t about technical superiority. It’s about risk allocation.
AWS spreads risk across multiple services and teams. When something breaks, it might be IAM, or S3 throttling, or Glue worker capacity, or Athena query limits. You need a broad team to manage it, but no single vendor can hold you hostage.
Databricks Approach
Databricks concentrates risk in one platform. When it works, it’s magical. When it doesn’t, you’re waiting for their support team to tell you why your $50k/month cluster is “optimizing” for the third hour straight.
Bottom Line
Choose based on your team’s tolerance for either distributed operational complexity or concentrated vendor dependence. Just don’t pretend the choice is about open standards—both platforms want you to stay forever. The only question is which cage has better WiFi.