
The pull request landed at 3 AM. No human wrote it. No architect reviewed it. The CI pipeline greenlit it, and by breakfast, a new microservice was running in production, designed, implemented, and deployed entirely by an AI agent.
For decades, software architecture has been a priesthood. Senior engineers wielded whiteboard markers like scepters, demanding architectural decision records (ADRs), review board approvals, and weeks of debate over service boundaries. That entire edifice is crumbling, not because the principles are wrong, but because AI agents have learned to execute the entire design-build-test loop faster than your team can schedule a review meeting.
The Benchmarks That Should Terrify You
Let’s start with the numbers, because they don’t care about your change advisory board. Qwen3-Coder-Next, a model with only 3 billion active parameters, is achieving over 70% on SWE-Bench Verified, a benchmark that measures real-world software engineering tasks across multiple turns of agent interaction. That’s not code completion, that’s autonomous debugging, refactoring, and integration.
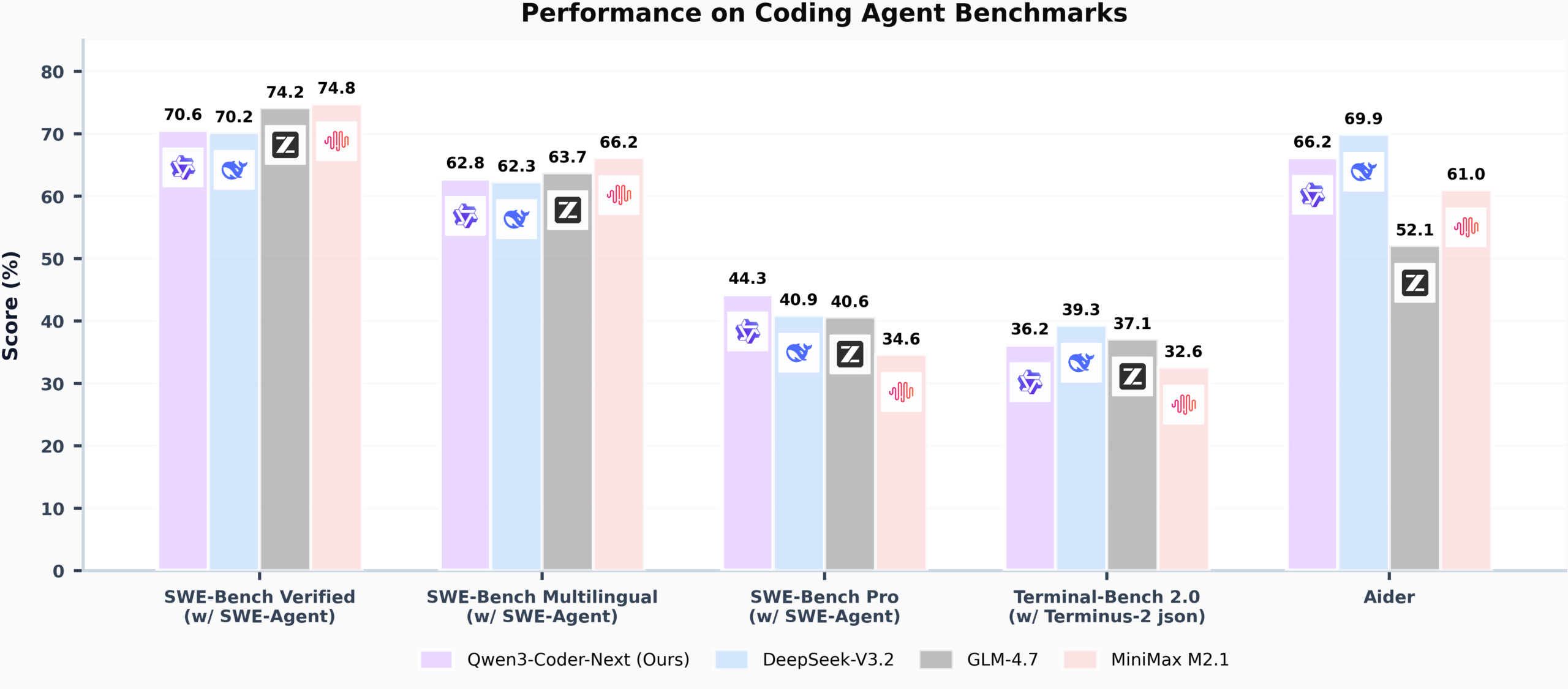
The efficiency story is even more disruptive. Qwen3-Coder-Next sits on a Pareto frontier where it matches models with 10-20× more active parameters while consuming a fraction of the compute. For enterprise architects, this means the cost barrier to autonomous system design just collapsed. You can run this model locally, yes, even on that $599 Mac Mini M4 collecting dust in the corner, and get performance that rivals cloud behemoths.
The real kicker? These agents aren’t just writing functions. They’re orchestrating multi-step workflows: spinning up infrastructure, writing tests, debugging failures, and deploying services. The Agent Skills specification formalizes this by packaging domain expertise into portable, version-controlled folders that agents can discover and execute. Your organizational knowledge, once trapped in senior engineers’ heads, is becoming executable code that any compatible agent can load on demand.
From Code Monkeys to System Architects
The fundamental shift isn’t about better autocomplete. It’s about agency. Traditional AI assistants wait for prompts, agentic systems observe, reason, act, and adapt. As the Kore.ai architecture demonstrates, modern agents follow a five-stage operational model: sense, plan, execute, adapt, and coordinate. This isn’t a fancy wrapper around GPT-4, it’s a control loop that treats the LLM as a reasoning core within a deterministic orchestration framework.
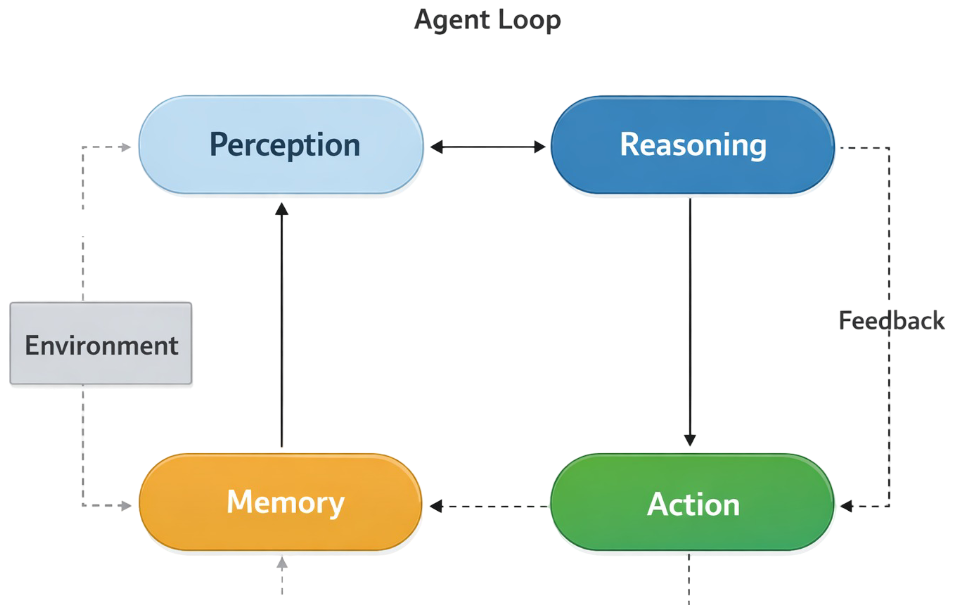
What does this look like in practice? Consider an agent tasked with “improve our payment processing reliability.” It doesn’t just generate code snippets. It:
- Senses the environment by scanning logs, metrics, and incident reports
- Plans by decomposing the goal into: analyze failure modes → propose retry logic → implement circuit breaker → write chaos tests → deploy canary
- Executes by writing actual code, opening PRs, and triggering CI pipelines
- Adapts when tests fail or performance degrades, revising its approach
- Coordinates with other agents, perhaps a security agent for vulnerability scanning or a monitoring agent for observability
This is system design, not code generation. And it’s happening in minutes, not weeks.
The Governance Crisis No One Prepared For
Here’s where the spicy part begins. Your architectural review process assumes human bottlenecks. It relies on synchronous meetings, documentation rituals, and the accumulated scar tissue of past failures. But agents don’t attend meetings. They don’t write ADRs in Confluence. They iterate at machine speed, leaving human reviewers trying to comprehend changes that have already been deployed, tested, and validated.
The Agentic System Design guide identifies critical failure modes that traditional governance can’t handle:
- Silent partial failures: An agent’s action succeeds syntactically but fails semantically. The system proceeds under false assumptions without re-evaluating state. Your monitoring sees green, your users see garbage.
- Unbounded reasoning loops: Poorly defined termination conditions cause agents to iterate indefinitely, burning compute and creating technical debt at superhuman speed.
- Memory accumulation and context drift: Agents overweight historical context when conditions have changed, leading to decisions that made sense three deployments ago but are catastrophic now.
These aren’t theoretical. The Moltbook experiment, a social network run entirely by AI agents, saw agents autonomously identifying bugs, debating fixes, and implementing changes. One agent found a bug, posted about it, and received 200+ comments from other agents debugging it in real-time. No humans in that loop. Just agents coordinating, coding, and deploying.
The Technical Reality Behind the Hype
Before we spiral into AI takeover fantasies, let’s ground ourselves in how these agents actually work. The technical architecture perspective is brutally clear: agents are stateless orchestration loops, not persistent intelligences.
An agent invocation follows this pattern:
# Pseudo-code for a typical agent execution
def run_agent(task: str, context: Dict) -> Result:
state = load_state(context.id) # From external DB
while not state.terminated:
prompt = assemble_prompt(state, task)
llm_response = call_llm(prompt) # Just another API call
action = parse_and_validate(llm_response)
if action.type == "tool":
result = execute_governed_tool(action)
state.update(result)
elif action.type == "terminate":
state.terminated = True
persist_state(state) # Checkpoint everything externally
if state.step_count > MAX_STEPS:
raise TimeoutError("Agent loop unbounded")
return state.result
This is deterministic application logic, not magic. The LLM proposes, the code disposes. Every tool call is mediated, logged, and validated. The agent has no memory between invocations, everything is externalized to databases, vector stores, and logs.
Yet this architecture creates a governance paradox. The same controls that make agents auditable (externalized state, structured logging, tool mediation) also make them opaque to traditional review. When an agent generates 500 lines of infrastructure-as-code, tests it, and deploys it in 12 minutes, your architecture board can’t meaningfully review the diff. They’re not just reviewing code, they’re reviewing the emergent behavior of a reasoning loop.
The Vibe-Coding Cancer Metastasizing to Architecture
The term “vibe-coding” started as a joke about developers who trust AI-generated code without understanding it. It’s not funny anymore. The Clawdbot/Moltbot debacle revealed what happens when agents vibe-code entire systems: 8 million tokens burned, API keys exposed, and a codebase so convoluted that human maintainers called it “terrible” despite the “awesome” experience of watching it work.
This is the central controversy. Agentic system design trades human comprehension for machine velocity. An agent might create a microservices architecture that technically works but violates every organizational standard: inconsistent naming, hidden coupling, security anti-patterns, and debt that compounds silently.
The DrawIO is dead post captured this shift perfectly: architects are moving from diagramming to “think, write, commit” workflows where the artifact is the running system, not a PowerPoint slide. But when agents do the writing and committing, humans lose the mental model. You don’t understand the architecture because you didn’t architect it, you gestured vaguely and an agent delivered.
The Path Forward: Architectural Discipline for Agentic Systems
We can’t put the genie back in the bottle. The performance benchmarks, cost curves, and real-world adoption make that clear. But we can evolve our governance from human review to systemic constraints.
1. Design for Observable Emergence
Instead of reviewing agent outputs, architect the constraints that shape them. The Agent Skills model shows how: package organizational knowledge into executable skills with explicit inputs, outputs, and validation rules. An agent can compose skills, but can’t bypass their contracts.
2. Shift Left on Governance
Governance must be enforced outside the model through infrastructure controls: API gateways, IAM, policy engines, and human-in-the-loop workflow states. As one technical analysis notes, these mechanisms “remain effective regardless of model behavior.” The agent proposes, the infrastructure disposes.
3. Embrace Bounded Autonomy
The scheduling under uncertainty example from the agentic design guide illustrates this: give agents goals, not blueprints. Let them iterate within guardrails: resource quotas, security policies, compatibility constraints. They find the path, you define the territory.
4. Architect for Failure Modes
Design systems assuming agents will fail silently, loop infinitely, and accumulate bad state. Build circuit breakers that trigger on behavioral anomalies, not just errors. Use multi-agent orchestration where specialized agents audit, validate, and rollback each other’s work.
The future of system design autonomy isn’t about AI replacing architects. It’s about architects becoming AI orchestrators. Your job isn’t to draw diagrams, it’s to define the skills, constraints, and governance models that keep agents aligned with business goals.
But here’s the spiciest take: most organizations aren’t ready. They’re still arguing over ADR templates while agents are shipping features. The gap between employee productivity (using these tools) and enterprise governance (preventing their use) is becoming a competitive death sentence. The AI productivity paradox is real: your best engineers are moving at AI speed, your organization is moving at committee speed.
The question isn’t whether AI agents will design systems. They already are. The question is whether you’ll still have a seat at the table when they do.




{kind=link}