The “Cowork” Mandate: A Crash Course in Magical Thinking
Here is the setup. Following an org restructure, a small data team, one data engineer, one analyst, one software engineer, was reassigned to support the R&D department of an industrial materials division. Their brief: find ways to use AI to help researchers do R&D faster and more efficiently, because the company had issued a mandate requiring each sector to generate a defined amount of AI-driven revenue per year.
The team started with interviews. What they found was a graveyard of data hygiene. Each researcher owned a single domain and invented their own work IDs with no naming standard. Sample IDs contained duplicates across experiments. One lab generated internal IDs like 26M0321 when receiving work orders. Another used 26C0926. A third required researchers to manually create test tasks in a web application with zero linkage back to the original work. If you wanted to trace an experiment from the original work, named 22032026_work_paper_exp1, through to all three labs, you had to open every individual file, extract sample IDs, and pray. Some records existed only as email threads or chat replies.
The situation was so bad that two months earlier, the department had engaged an external AI company to build prediction models. The vendor’s first request was simple: send us the past year of research data so we can start training. The department scrambled and managed to produce 48 rows of experiment data for one domain and 147 rows for another. For context, you typically need thousands of clean, structured records minimum to train a model that is worth anything. The engagement stalled.
When the data team lead presented findings to the VP and proposed a ground-up digital transformation requiring three to four months, he was stopped at “3 to 4 months.” The VP asked, “Have you ever heard of Claude Cowork? Just use Cowork, it should be really easy.” The deadline: one month.
Why Garbage In Becomes Garbage Out, Faster
The VP’s confusion is understandable if you’ve only read AI vendor landing pages. Large language models like Claude are remarkable at reasoning over well-structured text, generating code, and summarizing documents. They are not, however, data integration platforms. Feed them a mess of inconsistent IDs, duplicate sample names, and offline Excel sheets, and they will not magically produce a unified schema. They will produce confident nonsense at scale.
As James O’Donnell, head of GTM at Syniti, recently noted, “AI magnifies existing data problems.” When that same AI is rolled out across the whole business, it suddenly sees all the messy data too. That is when things break. O’Donnell gives the example of procurement systems: an AI model may find four vendor records that look similar. Two are old. One does not exist anymore. Another was never approved. The AI treats them all as active suppliers, and orders get placed four times over. Inventory piles up. Cash gets locked into open orders. The model did not make a random mistake, it scaled an existing data-quality failure across the enterprise.
This is not a theoretical corner case. Current industry data shows a 68% deployment failure rate for AI marketing tools, with the most common collapse pattern being enterprises purchasing AI expecting immediate personalization while their data still lives in a dozen disconnected systems with inconsistent identifiers.

The Shelf-Ware Cycle
One of the most expensive failure patterns in enterprise AI is buying the tool before building the foundation. According to implementation research, enterprises that purchase advanced analytics or personalization AI before unifying their data end up with nine to eighteen months of shelf-ware while they scramble to build the infrastructure the tool was supposed to replace. Estimated waste runs between $120,000 and $400,000 in subscription fees plus lost opportunity cost.
The R&D department is already living this movie. The external AI firm did not stall because the algorithms were faulty. It stalled because the organization could not produce a clean dataset. Forcing the internal team to “just use Cowork” to patch that same dataset together in a month does not solve the root cause, it simply accelerates the timeline to the next failure. The output might look like a database for a few weeks, but the moment it has to interact with the third lab’s web application or a new researcher’s bespoke Excel sheet, the heuristic glue will crack.
The Data Readiness Gap Is Not a Tech Problem, It Is a Culture Problem
Healthcare is further along in learning this lesson, and the parallels are painful. Organizations routinely discover that most healthcare AI pilots fail at scale because they were tested on curated data that does not reflect the full dataset. When the pilot goes live across the entire organization, the AI encounters reality, inconsistent coding conventions, fragmented EHR systems, and duplicate patient records. Clinicians lose confidence. Administrators quietly shelve the tool. The organization moves on to the next pilot without ever fixing the root cause.
There are five specific warning signs that an organization’s data is not ready for AI: you cannot trace where a data point originated, results vary significantly by site or department, your team spends more time cleaning data than analyzing it, there is no formal data governance policy, and critical data domains live in completely separate systems with no clean integration. Most health systems need six to eighteen months of foundational work before AI can scale reliably.
The industrial R&D division hits every single warning sign. Work IDs are untraceable. Results vary by researcher. The team is already spending all its time cleaning. Governance is nonexistent. And the labs operate as data silos.
Data Version Drift: When the Map Stops Resembling the Territory
Even if the team somehow stitched together a one-month parser, they would immediately face another problem: the data is not static. One researcher might change their naming convention next quarter. Another lab might adopt a new web form. The gap between the data the model was trained on and the data flowing into it right now is called data version drift.
During COVID-19, 72% of companies reported a negative impact on their supply chains, but the quieter failure behind the headlines was forecasting models collapsing the moment the data underneath them stopped reflecting reality. When supply chains shifted, models kept recommending decisions based on the world they last saw. In the R&D scenario, the equivalent happens when every new experiment invents its own schema. The parser built for 22032026_work_paper_exp1 is useless when the next researcher uses Exp_1_March_2026_v2. Without governance, drift is guaranteed.
Data-Driven Theater and the Bias of Convenience
There is another layer to this dysfunction. The VP is not asking for data infrastructure because he wants a reliable system. He is asking for it because the company has mandated AI-driven revenue, and he needs to show something quickly. This is data-driven theater.
Across the industry, data scientists report the same demoralizing pattern: leadership asks for a “data-driven decision”, but they have already decided what they want to do. The prevailing sentiment among practitioners is that most stakeholders are not looking for insight, they are looking for confirmation of existing bias. One analyst tried implementing statistical rigor for marketing holdouts and found the team did not appreciate having their inefficacy highlighted. Another realized that business decisions are often actually career decisions, people optimize for bonuses and visibility, not for the truth.
The VP who stopped the conversation at “3 to 4 months” does not want to hear that transformation takes time. He wants the AI to confirm that a shortcut exists.
What “Easy” Actually Costs
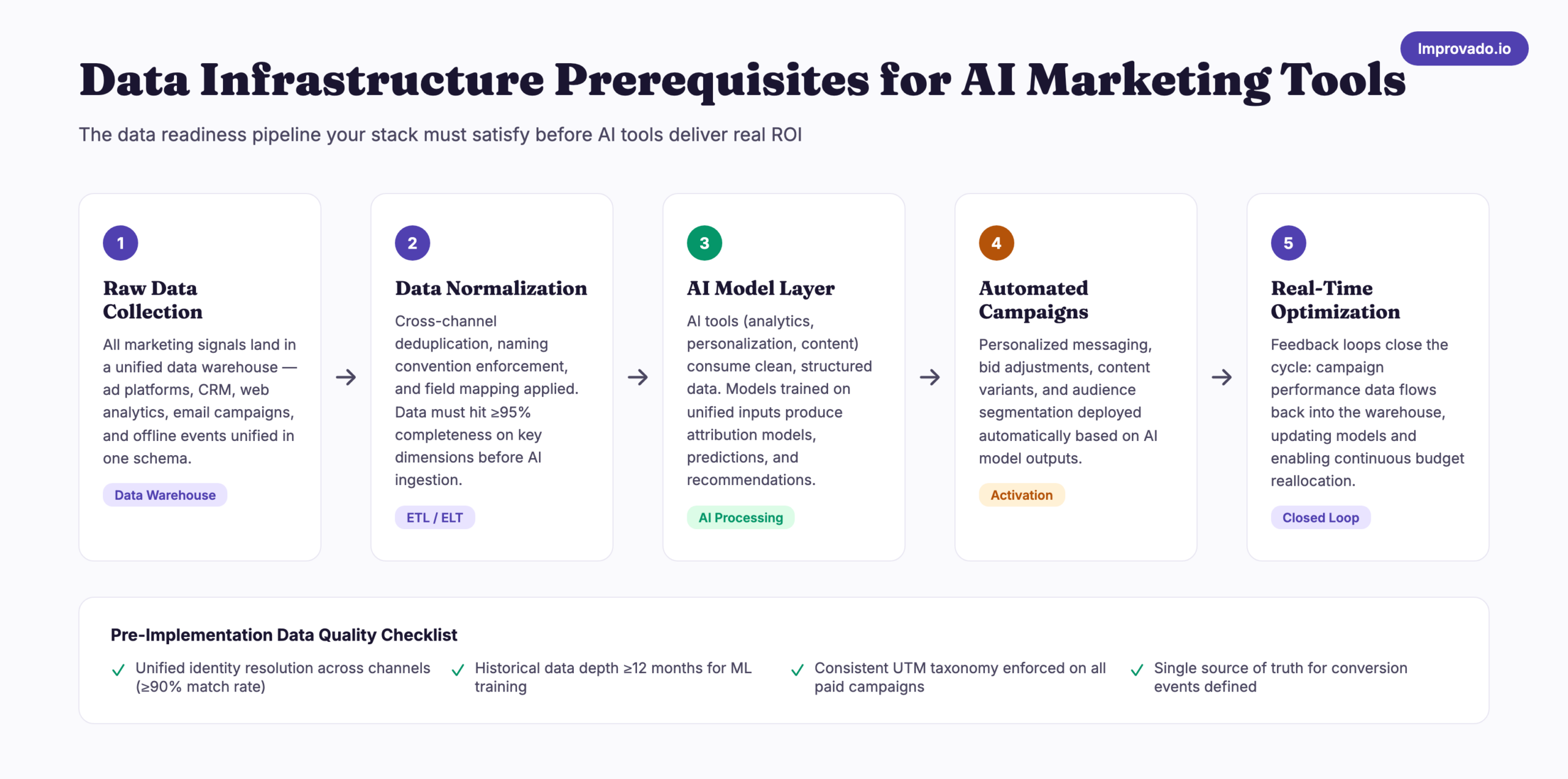
If the organization were serious about doing this correctly, the prerequisites are well documented. Analytics AI requires 70%+ clean data, unified identifiers, consistent naming conventions, and a centralized data warehouse or database. The implementation roadmap looks like a five-step pipeline: raw data collection, normalization, model input, automated campaigns, and real-time optimization. None of those steps can be skipped by prompting an LLM.
For an enterprise deployment, integration and setup alone typically demand 200 to 500+ hours. Data preparation adds another 150 to 400+ hours. Training a team requires 200 to 600+ hours. Even mid-market implementations run between $25,000 and $100,000 in total cost of ownership over twelve months. The VP’s one-month timeline is not ambitious. It is mathematically incoherent.
How to Survive an Unwinnable Mandate
So what should the data lead do? Some developers advocate for malicious compliance, feeding the mess into Claude, generating the terrible output, and letting the VP own the consequences. A more defensible strategy is controlled exposure with guardrails.
Scope ruthlessly. Do not try to parse every researcher’s output. Pick one domain, one researcher, and build a heuristic parser for that single thread. The goal is not to fix everything. It is to deliver a narrow proof of concept that makes the structural problems visible.
Document the lineage. Build a map showing exactly where each data point originates. If the VP wants to scale it, the first question becomes: who owns the schema for Lab 3? Without ownership, there is no scale. This avoids the data governance automation pitfalls that plague teams who try to automate their way around accountability.
Use precedent as a shield. The external AI engagement produced 48 rows and died. That is not a footnote, it is a risk assessment. Ask leadership directly whether they want to repeat a known failure on an arbitrary deadline.
Explain production risk. Rushing an AI system on untrusted, unstructured inputs into production does not just create bad data. It creates active liabilities. AI agent failures in production happen when systems consume inputs they cannot verify under pressure. A Sev0 outage built on top of 26AS0265436 is still a Sev0.
Get the mandate in writing. If the VP insists on the one-month timeline, confirm the scope, the handoff criteria, and the maintenance plan via email. When the inevitable drift and quality issues surface, the paper trail protects the team and concentrates accountability where it belongs.
The Bottom Line
The VP does not want AI. He wants a time machine that skips the tedious, expensive work of building a data foundation. That machine does not exist. Real transformation requires data stewards, enforced naming conventions, reliable pipelines, and months of unglamorous groundwork. Anything less is not innovation. It is a faster way to burn money, lose institutional knowledge, and stall yet another AI engagement. The only thing an LLM can do with years of data chaos in one month is help you document exactly why the job takes longer than that.