
Manual PII Masking Is a Trap Disguised as a Security Measure
Manual data masking is a trap disguised as a security measure. Every data engineer knows the drill: a product manager asks for “realistic” test data, QA needs production-like volumes to catch edge cases, and suddenly you’re writing Python scripts to hash email addresses at 2 AM, praying you didn’t break the foreign key relationships between users and orders.
The reality is harsher than most security audits admit. When developers share production CSVs with QA teams, they’re forced to choose between three bad options: manually obscuring columns (error-prone and tedious), writing brittle scripts that explode when the schema changes, or simply hoping nobody notices the PII leaking into Slack channels. This isn’t a workflow, it’s a liability factory.
The Referential Integrity Nightmare
The pain runs deeper than simple column substitution. Developers struggling with production data sharing face a trilemma: maintaining relationships across multiple tables while scrubbing sensitive fields, keeping masking consistent across distributed datasets, and handling schema drift without rewriting entire transformation pipelines.
Hashing a single column is trivial. Hashing user_id across fifteen related tables while preserving the ability to join them, handling nullable fields differently, and ensuring that customer_email in the analytics warehouse matches the masked version in the application database? That’s a full-time job. The moment your data spans multiple systems with evolving schemas, ad-hoc scripts become technical debt magnets.
The 80% Configuration Tax
Here’s where the “just write a script” brigade misses the point. According to Tonic.ai’s analysis, configuration accounts for an estimated 80% of the total work required in Test Data Management. Even with sophisticated masking tools in place, teams burn engineering hours hunting through legacy schemas, writing complex SQL transformations, and meticulously mapping generators to thousands of columns.
This is the hidden cost of “secure” data pipelines: they’re only secure if someone manually updates the masking rules every time a developer adds a new column. When governance relies on human diligence rather than automated enforcement, sensitive data has a habit of slipping through the cracks.
The Agentification of Data Sanitization

The shift from static scripts to AI-driven governance agents represents more than a tooling upgrade, it’s a fundamental architectural change. Instead of treating data masking as a preprocessing step, modern pipelines are embedding intelligence directly into the data layer.
Take the Structural Agent approach: by combining LLM-powered schema understanding with domain-specific masking algorithms, these systems eliminate the manual configuration bottleneck. The agent clusters PII by type (emails, names, financial data), proposes bulk generator applications across entire workspaces, and handles referential integrity automatically. When a schema changes, the agent detects the drift and suggests new generators rather than letting sensitive data leak into unmasked columns.
This matters because Deloitte forecasts that 50% of enterprises using generative AI will deploy AI agents by 2027. As data moves faster across cloud platforms and real-time pipelines, manual governance simply cannot keep pace with agent-driven execution.
Policy-Based Masking vs. Script-Based Chaos
Google BigQuery’s column-level data masking illustrates the architectural alternative to scripting hell. Rather than extracting, transforming, and loading masked copies of data, policy-based approaches apply masking rules at query runtime based on user roles.
The mechanism is elegant: you create taxonomies of policy tags (PII, Confidential, Financial), associate data masking rules with those tags, and apply the tags to columns. When a user with the Masked Reader role queries a column tagged as PII, they see SHA-256 hashes or nullified values instead of raw data. Users with Fine-Grained Reader roles see the original values. The same query returns different results based on entitlements, eliminating the need to maintain separate “clean” and “dirty” datasets.
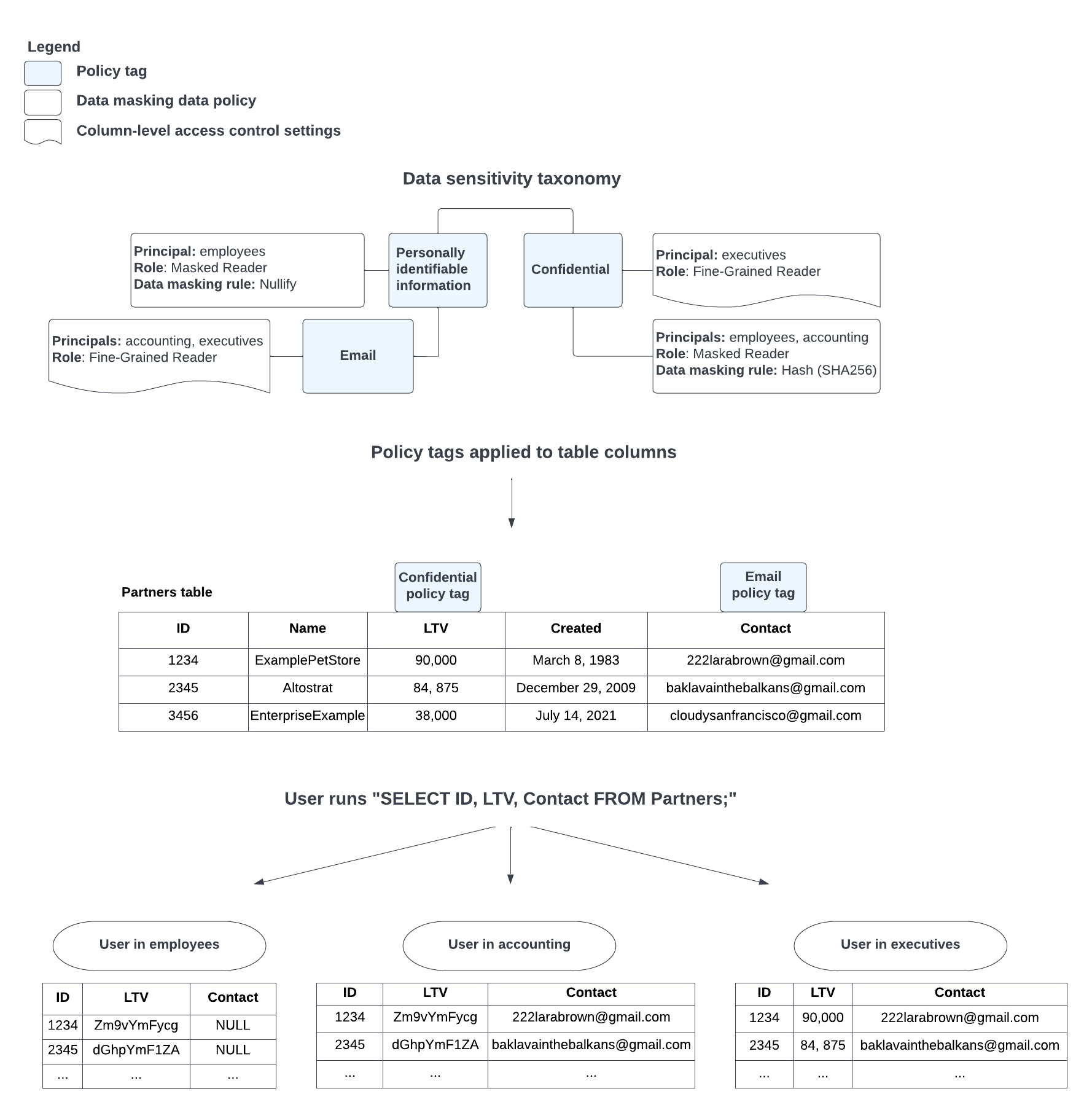
This approach handles the edge cases that break scripts: when conflicting policies apply (a user in both Accounting and General groups), BigQuery prioritizes based on a defined hierarchy (Custom routines > Random Hash > SHA-256 > Email mask, etc.). When there is a conflict between applying the nullify and the hash (SHA-256) data masking rules, the hash rule is prioritized, preserving joinability while maintaining security.
The Legacy Data Problem
Of course, none of this helps if you can’t find the sensitive data in the first place. Uncovering hidden data sources in legacy infrastructure remains the biggest blocker to automated sanitization. You can’t mask what you can’t catalog, and legacy systems have a habit of storing PII in columns named temp_field_3 or legacy_data.
AI governance agents address this by using classification models to scan schemas and identify sensitive information without relying on manual tagging. They detect anomalies, enforce access controls, and trigger remediation workflows in real time, crucial when Cisco’s 2026 Data and Privacy Benchmark Study found that 90% of organizations expanded their privacy programs specifically because of AI adoption.
Embedding Governance in CI/CD
The final piece is treating data masking as a first-class citizen in your delivery pipeline, not an afterthought. Enforcing architectural integrity through CI/CD gates means your builds should fail when sensitive data enters non-production environments unmasked.
Modern agentic frameworks are exploring direct CI/CD integration, allowing teams to interact with masking policies where they already work. Instead of context-switching between database consoles and Python scripts, developers can define masking requirements in plain language alongside their infrastructure-as-code definitions.
The Bottom Line
Manual PII masking isn’t just inefficient, it’s a security anti-pattern. When you rely on developers to remember which columns contain sensitive data and which scripts need updating, you’re betting your compliance posture on human fallibility.
The move toward automated, AI-driven sanitization isn’t about replacing human judgment, it’s about removing the toil that causes mistakes. Whether through column-level policy enforcement, intelligent schema-aware agents, or integrated CI/CD governance, the future of secure data pipelines is one where sensitive data is automatically handled correctly, no 2 AM scripting required.
Start by cataloging where your PII actually lives (agents help here), implement policy-based masking at the query layer rather than the pipeline layer, and stop treating data sanitization as a preprocessing step. Your QA team gets realistic data, your security team gets compliance, and you get your evenings back.