
Transformers v5’s Interoperability Gambit: Ending AI’s Format Wars
For years, the open-source AI community has operated like a collection of walled cities, each with its own incompatible standards, formats, and inference engines. Hugging Face’s Transformers library has been the closest thing to a universal adapter, but even it couldn’t bridge the growing divide between training frameworks and the specialized inference engines that make models actually usable. With Transformers v5, the company is making its boldest move yet: native interoperability with the entire LLM ecosystem, from llama.cpp’s minimalist CPU-first approach to vLLM’s production-grade serving.
The announcement, delivered with characteristic enthusiasm by Hugging Face’s Merve Noyan, frames this as the moment “open source AI” finally lives up to its name, interoperable tools, not walled gardens. The community’s reaction has been a mix of genuine excitement and battle-hardened skepticism. While some developers immediately point to features like GGUF import/export and improved quantization support as game-changers, others are asking the harder question: does this solve the fragmentation problem, or just repackage it?
The Fragmentation Problem Nobody Wants to Admit
The LLM ecosystem has been splitting into three distinct camps. On one side, you have the research and fine-tuning crowd, living in the PyTorch/Transformers universe where models are born. On another, the local inference enthusiasts, who’ve embraced llama.cpp’s philosophy of running massive models on modest hardware through aggressive quantization and clever CPU optimization. And on the third side, the production deployment specialists, who need vLLM’s continuous batching and PagedAttention to serve models at scale.
Moving a model between these worlds has historically been a duct-tape nightmare. A model trained in Transformers needed to be exported, converted, often re-quantized, and then debugged for compatibility issues. The process was so brittle that many developers simply rebuilt their models from scratch for each target environment. As one developer on r/LocalLLaMA noted, trying niche models across different inference engines meant quantization was “more often broken than working.”
What “Interoperability” Actually Means in Practice
The technical meat of Transformers v5 lies in its native support for the formats that power the inference ecosystem. The GGUF format, pioneered by llama.cpp, becomes a first-class citizen. This isn’t just token support, it’s deep integration that respects the quantization schemes that make local inference feasible.
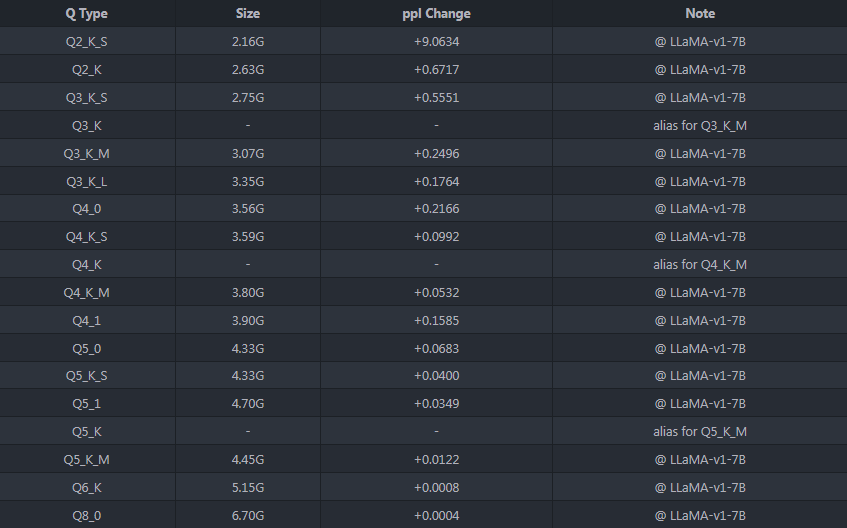
For context, GGUF (GPT-Generated Unified Format) is what allows a 7B parameter model to shrink from 13GB to under 4GB through quantization methods like Q4_K_M. This isn’t just file compression, it’s a carefully calibrated trade-off between model quality and memory footprint that makes running LLMs on consumer hardware possible. The llama.cpp ecosystem has refined these techniques to the point where developers can choose from a menu of quantization strategies, each with different performance characteristics.
Transformers v5 doesn’t just read these files, it understands them. The library now includes native support for the same quantization-aware kernels that llama.cpp uses, meaning a model exported from Transformers to GGUF maintains its performance characteristics rather than becoming a second-class citizen.
The vLLM integration tackles the other end of the spectrum. Where llama.cpp optimizes for accessibility, vLLM optimizes for throughput. Its PagedAttention mechanism eliminates memory fragmentation during batched inference, delivering 10-20x higher throughput than standard transformers for serving workloads. Transformers v5 models can now be loaded directly into vLLM without the intermediate conversion steps that previously added friction to production deployments.
The Llama.cpp Connection: Democratization vs. Performance
The marriage between Transformers and llama.cpp represents something bigger than convenience, it validates the entire philosophy of making AI accessible. Georgi Gerganov’s creation started as a seemingly quixotic attempt to run LLaMA models on CPUs without CUDA, rewriting the inference code in clean, efficient C++. What began as a hacker’s experiment has become the backbone of local AI deployment.
The connection goes both ways. Transformers v5 models can now be exported to llama.cpp’s GGUF format with a single command, but perhaps more importantly, the knowledge transfer flows upstream. The quantization techniques and memory optimization strategies that llama.cpp pioneered are now informing how Transformers itself handles model compression.
This creates an interesting tension. The original appeal of llama.cpp was its independence from the heavyweight PyTorch ecosystem. It was a lean, self-contained tool that didn’t require the baggage of a full ML framework. Some purists worry that deeper integration with Transformers might compromise that minimalist philosophy. As articulated in a Russian technical deep-dive on the engine, llama.cpp’s strength lies in its “minimalism, flexibility, and accessibility”, not in becoming another component of a larger stack.
The counterargument is that interoperability doesn’t mean homogenization. A model trained in Transformers can now be exported to GGUF and run with llama.cpp’s CPU-optimized inference, but developers can still use llama.cpp as a standalone tool. The integration is about removing walls, not building a monoculture.
Production Realities: vLLM and the Serving Challenge
While llama.cpp democratizes access, vLLM addresses the economic reality of serving AI at scale. The difference in performance is stark. Benchmarks comparing llama.cpp’s GPU backend against TensorRT and other production inference engines show that while llama.cpp is competent, it’s not designed for maximum throughput. It’s a “people’s engine”, not a data center workhorse.
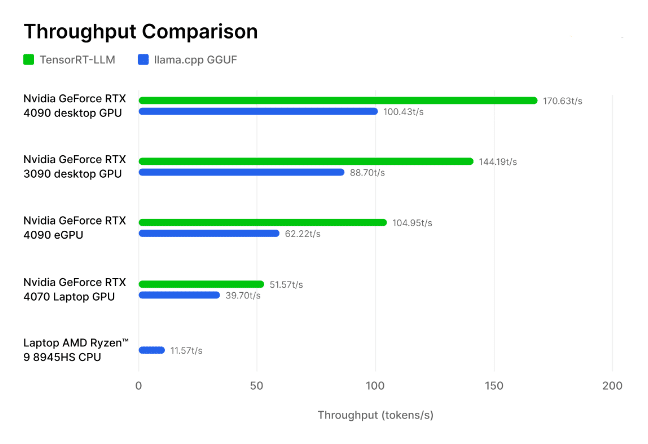
This is particularly relevant for the emerging class of developer who needs to straddle both worlds: fine-tuning on specialized hardware but deploying to cost-effective inference infrastructure. The ability to validate a model in the same framework that will serve it eliminates an entire category of deployment surprises.
The Skeptic’s View: Vaporware or Victory?
Despite the promise, experienced developers are withholding judgment. The AI field has a long history of announcements that sound revolutionary but deliver incremental improvements. The mention of “Llama5Tokenizer” in the release notes, referencing a model that doesn’t exist yet, hasn’t helped the credibility, feeding speculation that some features are aspirational rather than implemented.
The real test will be in edge cases. Interoperability is easy to demonstrate with standard models, it’s much harder with the quirky, fine-tuned variants that populate the long tail of Hugging Face’s model hub. The community’s excitement about GGUF import/export stems from exactly this pain point: trying niche models that are too specialized for mainstream inference engines and finding quantization support broken more often than not.
Developers are also watching the performance implications. Interoperability layers can introduce overhead, and the quantization support needs to be more than just “technically functional.” It must preserve the model quality that makes each quantization scheme valuable. If Transformers v5 treats quantization as a checkbox feature rather than a precision tool, it will fail the very community it’s trying to serve.
What This Means for AI Development
If Transformers v5 delivers on its promise, the impact extends beyond convenience. It could reshape how we think about the AI development lifecycle. The current mental model separates training, optimization, and deployment into distinct phases with handoffs between tools. A truly interoperable ecosystem blurs these lines, enabling iterative refinement where a model can be fine-tuned in Transformers, tested locally with llama.cpp, then deployed to production via vLLM, all in a tight feedback loop.
This approach aligns with the original promise of open-source AI: modularity, transparency, and the freedom to compose tools based on need rather than vendor lock-in. The walled gardens have been a necessary evil, growing up around the complexity of making LLMs practical. By standardizing formats and interfaces, Transformers v5 could lower the barriers to entry for custom AI solutions.
For developers building on top of these tools, the immediate benefit is reduced maintenance. No more maintaining separate conversion pipelines or debugging why a model works in one engine but not another. The long-term benefit is more subtle: it enables a richer ecosystem of specialized tools that can focus on doing one thing well, confident they can interoperate with the rest of the stack.
The Bottom Line: Promise and Peril
Hugging Face’s Transformers v5 represents a critical inflection point. The technical work enabling GGUF support and vLLM integration is substantial and genuinely useful. It addresses real pain points that developers face daily when moving models between environments.
However, the true measure of success won’t be the feature checklist, it will be whether the integration preserves the unique strengths of each tool. If llama.cpp becomes just another output format rather than a platform for experimentation, or if vLLM’s performance optimizations get flattened by the compatibility layer, then the interoperability will have come at too high a cost.
The community sentiment captured in the Reddit discussion reflects this duality: excitement about “true model portability” tempered by the hard-won knowledge that AI’s fragmentation problem runs deeper than file formats. The tools that succeed are those that respect the underlying philosophies of their ecosystems while making pragmatic compromises.
For now, Transformers v5 is a step toward the open, interoperable AI ecosystem that many have envisioned. Whether it becomes the foundation of a new, unified toolchain or another transitional technology in AI’s rapid evolution depends on execution. The promise is there. The implementation details will determine whether this is the end of format wars or just the beginning of a new chapter.



