The model is a 119B parameter MoE beast with only 6B active parameters, Apache-2.0 licensed, and already finding real bugs in production repositories. Here’s why that matters more than another GPT wrapper.
The “Vibe Coding” Era Just Got a Formal Notice
The industry has been riding a wave of “vibe coding”, generate code, run tests, pray it works, ship it. It’s been working, sort of. But the ceiling is real. AI-generated code that looks correct but contains subtle logical errors is a growing liability, especially in critical infrastructure.
Leanstral 1.5 represents the antidote. It’s not generating code that might be correct. It’s generating machine-verifiable proofs that your code is correct. This is how Mistral’s Leanstral is shifting the paradigm from ‘vibe coding’ to formal verification, and the implications are massive.
What Actually Is Leanstral 1.5?
Before you get excited about another general-purpose coding assistant, let’s be clear: this is a specialized model for Lean 4, a functional programming language and theorem prover. It’s not going to write your React components or optimize your SQL queries.
Leanstral 1.5 is a 119B parameter Mixture-of-Experts model with only 6.5B active parameters per token. It routes each token through 4 of 128 expert modules, making it remarkably efficient for its size. The architecture supports a 256k-token context window, which is critical for handling long proof chains and entire codebases.
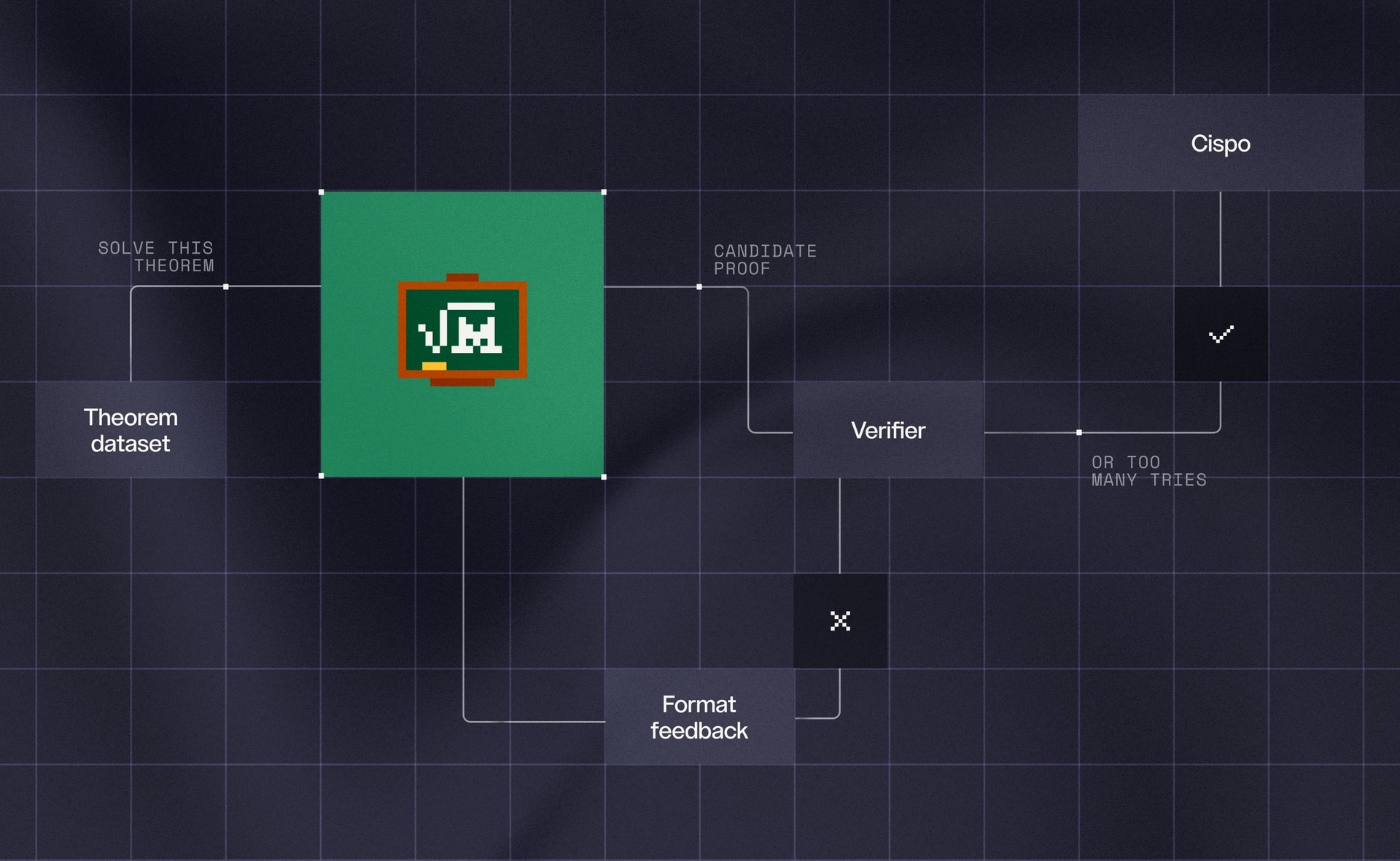
The model is trained through a three-stage pipeline: mid-training, supervised fine-tuning, and reinforcement learning with CISPO (a novel RL algorithm). It operates in two distinct environments:
- Multiturn environment: Given a theorem statement, the model submits a proof, receives Lean compiler feedback, and iterates until the proof compiles or it exhausts its budget.
- Code agent environment: Leanstral operates like a developer in a raw filesystem, editing files, running bash commands, and using the Lean language server to inspect goals, errors, and type information in real time.
The Numbers That Matter
Leanstral 1.5 doesn’t just claim to be better, it saturates benchmarks. Here’s the breakdown:
| Benchmark | Performance | Context |
|---|---|---|
| miniF2F | 100% (saturated) | Cross-system benchmark from elementary to IMO-level problems |
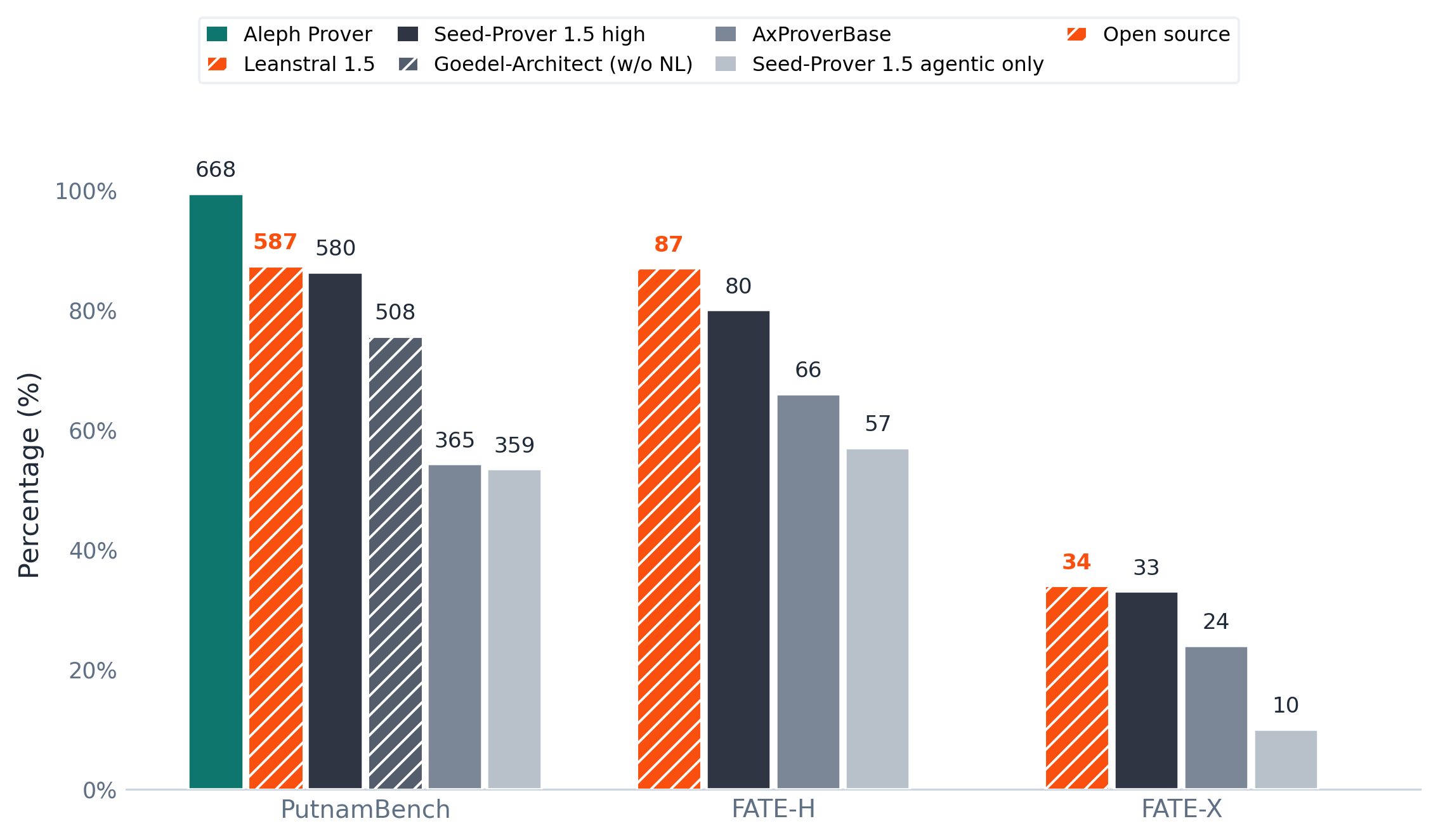
| PutnamBench | 587/672 solved | Putnam Mathematical Competition problems |
| FATE-H | 87% (SOTA) | Graduate-level abstract algebra |
| FATE-X | 34% (SOTA) | PhD-level abstract algebra |
| FLTEval | 28.9% pass@1 (up from 21.9) | Real pull requests from Fermat’s Last Theorem repo |
The PutnamBench results are particularly striking. At a cost of roughly $4 per problem, Leanstral 1.5 edges out Seed-Prover 1.5 high by 7 problems, a system that costs an estimated $300+ per problem running on 10 H20-days of compute. The only provers ranked higher, like Aleph Prover at $54, 68 per problem, operate under fundamentally different conditions, often receiving natural-language proof guidance.
The Training Recipe: More Than Just Next-Token Prediction
Leanstral 1.5’s training pipeline is where things get interesting. It’s not your standard “scrape the internet and predict the next word” approach. The model undergoes three distinct stages:
- Mid-training: Domain-specific continued pretraining on mathematical and formal verification data
- Supervised fine-tuning: Learning from expert demonstrations of proof engineering
- Reinforcement learning with CISPO: A novel RL algorithm that optimizes for proof completion
The RL stage is particularly clever. The model trains in two environments:
- Multiturn environment: Given a theorem, the model submits a proof, receives Lean compiler feedback, and iterates. If the proof compiles, it succeeds. Otherwise, the loop continues until the model solves the problem or exhausts its budget.
- Code agent environment: Leanstral operates like a developer in a raw filesystem, editing files, running bash commands, and using the Lean language server to inspect goals, errors, and type information in real time. This allows it to tackle long-horizon tasks like completing partial proofs in a repository, building auxiliary lemmas, and persisting through multiple rounds of context compaction.
The Cost Efficiency That Changes the Calculus
The economics here are what make this genuinely disruptive. Consider the cost comparison:
| System | Cost per PutnamBench Problem | Performance |
|---|---|---|
| Leanstral 1.5 | ~$4 | 587/672 solved |
| Seed-Prover 1.5 (high) | ~$300+ | 580/672 solved |
| Aleph Prover | $54, 68 | Higher, but with NL guidance |
Leanstral 1.5 solves 7 more PutnamBench problems than Seed-Prover 1.5 at roughly 1/75th the cost. The test-time scaling is equally impressive: performance climbs smoothly from 44 problems solved at 50k tokens to 587 at 4M tokens. The model doesn’t give up when proofs run long, it keeps reasoning, editing files, and revising across millions of tokens.
Real Bugs Found in the Wild
This isn’t just a benchmark toy. Mistral built an automated pipeline that translates Rust code to Lean using Aeneas, then has Leanstral infer user intent and generate correctness properties. Across 57 tested repositories, the pipeline flagged 47 violated properties, with 11 pointing to genuine bugs, 5 of them previously unreported on GitHub.
One particularly nasty bug was in the sign function for zigzag decoding of the datrs/varinteger library. On input Std.U64.MAX, the expression (value + 1) overflowed, causing crashes in debug mode and silent corruption in release mode. This is exactly the kind of edge case that testing and fuzzing routinely miss, but formal verification catches automatically.
The AVL Tree Proof: 2.7 Million Tokens of Persistence
The most impressive demonstration of Leanstral 1.5’s capabilities is the AVL tree time complexity proof. AVL trees are self-balancing binary search trees that maintain O(log n) height through rebalancing during insertions and deletions. Proving this formally required:
- Structural induction to mirror the tree’s recursive structure
- Careful handling of monadic time tracking
- Exhaustive case analysis for rebalancing paths
The model worked through 2.7 million tokens and 22 compactions to systematically unfold each layer of the TimeM monad, exposing the underlying computations despite their interleaving with control flow. It established an almost tight bound of 48 steps per height unit plus a constant for insertion, then connected height to tree size via a logarithmic relationship.
This isn’t a model that gives up when things get hard. It keeps reasoning, editing files, and revising across millions of tokens, turning compute budget directly into solved problems.
The Bug Pipeline: Automated Verification at Scale
The most practical demonstration of Leanstral 1.5’s value is its automated bug-finding pipeline. Here’s how it works:
- Aeneas translates Rust code to Lean
- Leanstral infers user intent and generates correctness properties
- The model attempts to prove each property (4 attempts)
- If all fail, it tries to prove the negation (4 attempts)
- Violations are flagged for human review
Across 57 tested repositories, this process flagged 47 violated properties, with 11 pointing to genuine bugs, 5 of them previously unreported on GitHub. The datrs/varinteger library bug is a perfect example: on input Std.U64.MAX, the expression (value + 1) overflowed, causing crashes in debug mode and silent corruption in release mode. Traditional testing and fuzzing missed it. Leanstral caught it automatically.
This is the kind of capability that makes you rethink your QA strategy. The model isn’t just finding bugs, it’s proving their existence mathematically.
Why This Matters Beyond Math
The knee-jerk reaction is to dismiss this as a niche tool for mathematicians. That’s short-sighted. The Curry-Howard isomorphism means that a successful compilation in Lean is a valid proof of your code’s specification. When Leanstral proves a property about your Rust code (translated via Aeneas), you get a machine-verified guarantee against logical errors.
This has profound implications for:
- Critical infrastructure: Financial systems, medical devices, aerospace software
- Smart contracts: Where a single bug can cost millions
- Cryptographic implementations: Where edge cases are security vulnerabilities
- Protocol implementations: Where correctness is non-negotiable
The model’s ability to find bugs that traditional testing misses is already proven. The 5 previously unknown bugs it discovered across 57 repositories weren’t found by fuzzing, static analysis, or code review. They were found by formal proof.
The Cost Argument That Changes Everything
The economics of formal verification have always been the barrier. Hiring a team of proof engineers is prohibitively expensive for most organizations. Running massive verification systems costs thousands per problem.
Leanstral 1.5 changes that calculus. At roughly $4 per PutnamBench problem, it’s 75x cheaper than Seed-Prover 1.5’s high setting and 15x cheaper than Aleph Prover. The model’s test-time scaling is remarkably efficient: performance climbs smoothly from 44 problems solved at 50k tokens to 587 at 4M tokens, with no signs of plateauing.
This is part of Mistral’s broader open-weight strategy and model ecosystem, where efficient architectures enable capabilities that were previously locked behind massive compute budgets.
The Practical Path Forward
Getting started with Leanstral 1.5 is straightforward. The model is available under Apache-2.0 license on Hugging Face and as a free API endpoint. Here’s the quick start:
# Install Mistral Vibe
uv tool install mistral-vibe
# Install Leanstral 1.5
/leanstall
exit
# Launch the agent
vibe --agent lean
For local deployment, you can spin up a vLLM server:
vllm serve mistralai/Leanstral-1.5-119B-A6B \
--max-model-len 200000 \
--tensor-parallel-size 4 \
--attention-backend FLASH_ATTN_MLA \
--tool-call-parser mistral \
--enable-auto-tool-choice \
--reasoning-parser mistral
The Verdict: This Changes the Game
Leanstral 1.5 isn’t just another model release. It’s a proof point that formal verification is becoming practical, affordable, and automated. The combination of MoE efficiency, RL-based training, and agentic proof engineering creates a tool that can actually verify real-world codebases and find bugs that traditional methods miss.
The challenge of running large models locally remains, 119B parameters isn’t trivial, but the MoE architecture means only 6.5B are active per token, making inference surprisingly efficient. For teams building critical software, the cost of running Leanstral 1.5 is already lower than the cost of a single production bug.
The era of “move fast and break things” is ending. The era of “prove it’s correct” is beginning. Leanstral 1.5 is the tool that makes that transition practical.