
Kernel Panic: Your OS Crash is Actually a Well-Designed Failure

That frozen screen with cryptic error messages? It’s not a failure of engineering, it’s the system’s last line of defense. When Linux hits a kernel panic, it’s making a deliberate choice to shut down rather than risk corrupting your data or compromising system integrity. Modern exploration tools are finally revealing what’s actually happening when your system stops cold.
The Kernel Explorer’s Revelation: It’s All About Control, Not Code
The Linux Kernel Explorer isn’t just another code browser, it’s a visualization of system design principles in action. As the tool demonstrates through interactive exploration of core files like init/main.c and kernel/fork.c, the kernel serves as “the always-present authority bridging hardware and software.”
This architectural insight exposes why kernel exploration matters: you’re not just reading code, you’re witnessing the enforcement of separation and control that keeps modern computing systems stable. The kernel’s layered design, virtual, mapped, isolated, and controlled, isn’t just theoretical architecture, it’s the reason your applications don’t crash the entire system when they misbehave.
Consider this fundamental truth the explorer reveals: The kernel isn’t a process, it’s the system itself. This distinction explains everything about why panics happen and why they’re often the correct response to catastrophic failure.
Anatomy of a Deliberate Shutdown
When your Linux system hits a kernel panic, research shows it’s executing a sophisticated safety protocol. The panic message “not syncing: Fatal exception” isn’t an admission of defeat, it’s the system declaring “I cannot guarantee data integrity beyond this point, so I’m shutting down.”
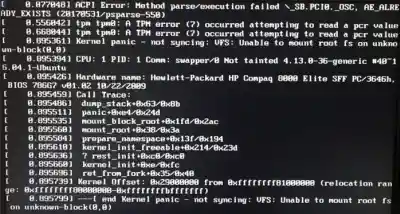
Modern debugging tools like kgdb and kdump reveal the sophistication behind what appears to be a system failure. When configured properly, kdump captures a full memory snapshot at the moment of failure, creating a vmcore file that preserves the exact system state for post-mortem analysis.
As security researchers note, “The function names and module identifiers point directly to where the kernel failed. Watch the taint flags, they tell you if nonstandard modules or forced loads were involved.” This level of diagnostic capability transforms what looks like random crashes into traceable fault chains.
Why Exploration Tools Are Revolutionizing OS Education
Traditional kernel documentation presents Linux as a static codebase to be memorized. Interactive explorers flip this model, they treat the kernel as a dynamic system that reveals its design through interaction. When you can see how kernel/fork.c handles process creation or how arch/x86/kernel/entry_64.S manages context switches, abstract concepts become tangible engineering decisions.
The educational shift is profound. Instead of reading about scheduling algorithms, you’re exploring the actual scheduler code and testing your understanding with interactive knowledge checks. This transforms kernel education from passive consumption to active discovery.
The most insightful tools don’t just show code, they demonstrate relationships. Seeing how memory management interacts with process scheduling, or how device drivers interface with the virtual filesystem, reveals why certain failure modes cascade while others are contained. It’s system design made visible.
The Debugging Paradigm Shift: From Panic to Pattern Recognition
Advanced debugging has evolved from simply fixing crashes to understanding system behavior. As the Linux security research emphasizes, “Some teams go further with live debugging when they can reproduce the crash safely. Tools like kgdb attach a debugger to a running kernel, while netconsole, serial console, and earlycon stream messages off-system before it locks.”
This approach transforms kernel panics from random failures into predictable patterns. The remediation workflow becomes systematic:
- Stabilize and confirm – Turn off auto-reboot to capture evidence
- Boot from known-good kernel – Isolate the change that triggered the issue
- Rebuild the boot path – Repair
initramfsandGRUBconfigurations - Check modules and drivers –
DKMSrebuild failures and unsigned modules are common culprits
The most revealing insight? Modern kernel exploration isn’t about preventing all crashes, it’s about understanding which crashes are acceptable failures versus which ones indicate systemic problems.
What Kernel Design Reveals About Modern Software Architecture
The Linux kernel’s approach to failure handling offers lessons that extend far beyond operating systems:
- Layered Isolation Isn’t Optional – The kernel’s strict separation between kernel space and user space prevents application bugs from becoming system failures. This same principle applies to microservices, containers, and cloud-native applications.
- Graceful Degradation Beats Perfect Reliability – Rather than attempting to recover from every possible failure, the kernel makes calculated decisions about when to shut down. This “fail safe” approach is increasingly relevant in distributed systems where partial failures are inevitable.
- Observability Trumps Prevention – Modern debugging tools focus on capturing system state at failure moments rather than preventing all failures. This shift toward post-mortem analysis reflects reality: complex systems will fail, so we’d better understand why.

The Future: Intelligent Crash Analysis
We’re moving toward systems that don’t just crash safely but learn from their failures. Imagine kernel explorers that not only show code relationships but also correlate crash patterns across systems, identifying common failure modes before they hit production.
The next generation of exploration tools will likely integrate machine learning to predict which code changes are most likely to trigger specific failure modes. Instead of waiting for panics to happen in production, developers could simulate failure scenarios during development.
This transforms system design from reactive debugging to proactive resilience engineering. Understanding why systems fail becomes as important as making them work, and sometimes more revealing about their true architecture.
Beyond the Panic: Seeing System Design Through Failure
The most valuable insight from modern kernel exploration might be this: System architecture reveals itself most clearly at its breaking points. When you understand why and how a system fails, you understand what the architects valued most.
In Linux’s case, that value hierarchy is clear: data integrity over availability, isolation over convenience, control over flexibility. These aren’t just technical decisions, they’re philosophical ones that shape how billions of devices operate.
Next time you see a kernel panic, don’t think of it as a system failure. Think of it as the system successfully executing its most important safety mechanism. The real failure would be continuing to operate when data integrity can’t be guaranteed.
The tools now exist to explore not just what the kernel does, but why it makes the choices it does under pressure. That understanding might be the most valuable debugging skill of all.




