
OpenAI’s GPT-5.2 isn’t just an incremental update. It’s a live demonstration of what happens when you stop iterating on a model and start re-engineering the entire stack around a single goal: agentic dominance. Released in the shadow of internal “Code Red” directives intended to galvanize the company’s pace against competitors like Google, this release is less about a smarter chatbot and more about building the production-grade scaffolding for AI that can run your business.
The official system card and documentation offer more than just benchmark numbers. They reveal an architecture matured under the pressures of real-world enterprise use, scaling lessons that are now prerequisites for anyone building serious AI infrastructure. Let’s dissect the trade-offs, see what the benchmarks hide, and ask if the 40% price premium is architectural genius or just premium gas for the same engine.
Redefining the Endgame: From Model to Agentic System
GPT-5.2 isn’t just a new model checkpoint. Its defining feature is a practical, agentic-first architecture built to handle entire problems, not just prompts.
This manifests as a dramatic 400,000-token context window (as noted by eWeek), five times GPT-4’s capacity. But the breakthrough isn’t just raw size, it’s functional length. The model achieves near 100% accuracy on the “4-needle” OpenAI MRCRv2 task, meaning it can spot and recall distinct, buried pieces of information scattered across massive documents with near-perfect reliability. For an enterprise, this means your RAG (Retrieval-Augmented Generation) system just got a major upgrade: you can throw a full codebase, a multi-hundred-page report, or a complex legal contract straight in, and expect coherent, context-aware reasoning across the entire corpus.
The Microsoft Foundry blog post explicitly calls out GPT-5.2’s “agentic execution” as a leap forward, letting it “coordinate tasks end-to-end, across design, implementation, testing, and deployment.” It’s a model designed to orchestrate complex workflows beyond simple Q&A.
Key Performance Metrics That Tell the Real Story:
| Benchmark | GPT-5.2 Thinking | GPT-5.1 Thinking | Delta |
|---|---|---|---|
| GDPval (Knowledge Work) | 70.9% | 38.8% | +82.7% |
| SWE-Bench Pro (Multi-language) | 55.6% | 50.8% | +9.4% |
| Tau2-bench Telecom (Tool-Calling) | 98.7% | 95.6% | +3.2% |
| ARC-AGI-2 (Abstract Reasoning) | 52.9% | 17.6% | +200.6% |
| Hallucination Rate (rel) | – | – | -30% |
The staggering lifts in GDPval (nearly doubling human expert parity) and ARC-AGI-2 point to a fundamental architectural shift. This isn’t just more data, it’s a different kind of model. The jump from 17.6% to 52.9% on ARC-AGI-2, a benchmark designed to isolate general reasoning, is arguably the most significant number in the release. It suggests OpenAI is cracking problems requiring novel abstractions.
The New Scaling Math: Token Efficiency at a Cost
The most eyebrow-raising detail is the pricing. GPT-5.2 costs $1.75 per million input tokens and $14 per million output tokens. This is a 40% increase over GPT-5.1 ($1.25/$10). OpenAI’s defense? “Token efficiency.” They claim that despite the higher per-token cost, “the cost of attaining a given level of quality ended up less expensive.”
This means OpenAI is betting that GPT-5.2 solves complex tasks in fewer tokens. It’s an architectural optimization for better “reasoning density.” While cheaper models might require long, meandering chains of thought, GPT-5.2’s more sophisticated architecture is designed to produce correct answers with less textual fluff. This is a direct nod to the “o1” series of reasoning-focused models. You’re paying more per unit, but you need fewer units to do the job.
Let’s break it down:
* Input Tokens: $1.75/million (GPT-5.1: $1.25/million)
* Cached Input Tokens: $0.175/million (90% discount)
* Output Tokens: $14/million (GPT-5.1: $10/million)
The rationale is that its massive context window ($400K) allows you to send enormous documents once, pay the caching discount for subsequent queries ($0.175/M), and receive precise, multi-step answers without back-and-forth API calls. This changes the calculus for enterprise-scale deployments.

What the Architecture Actually Optimized For
The system card updates and performance metrics reveal the engineering priorities:
- Long-Context Coherence: The near-perfect scores on needle-in-a-haystack tests prove they’ve figured out how to maintain attention and retrieve information reliably across 256k+ token spans. This isn’t a bigger bucket, it’s a smarter, more stable one.
- Tool Execution Reliability: Scoring 98.7% on Tau2-bench Telecom for multi-turn, tool-using workflows means the model isn’t just suggesting an API call, it’s managing entire stateful processes end-to-end with high reliability.
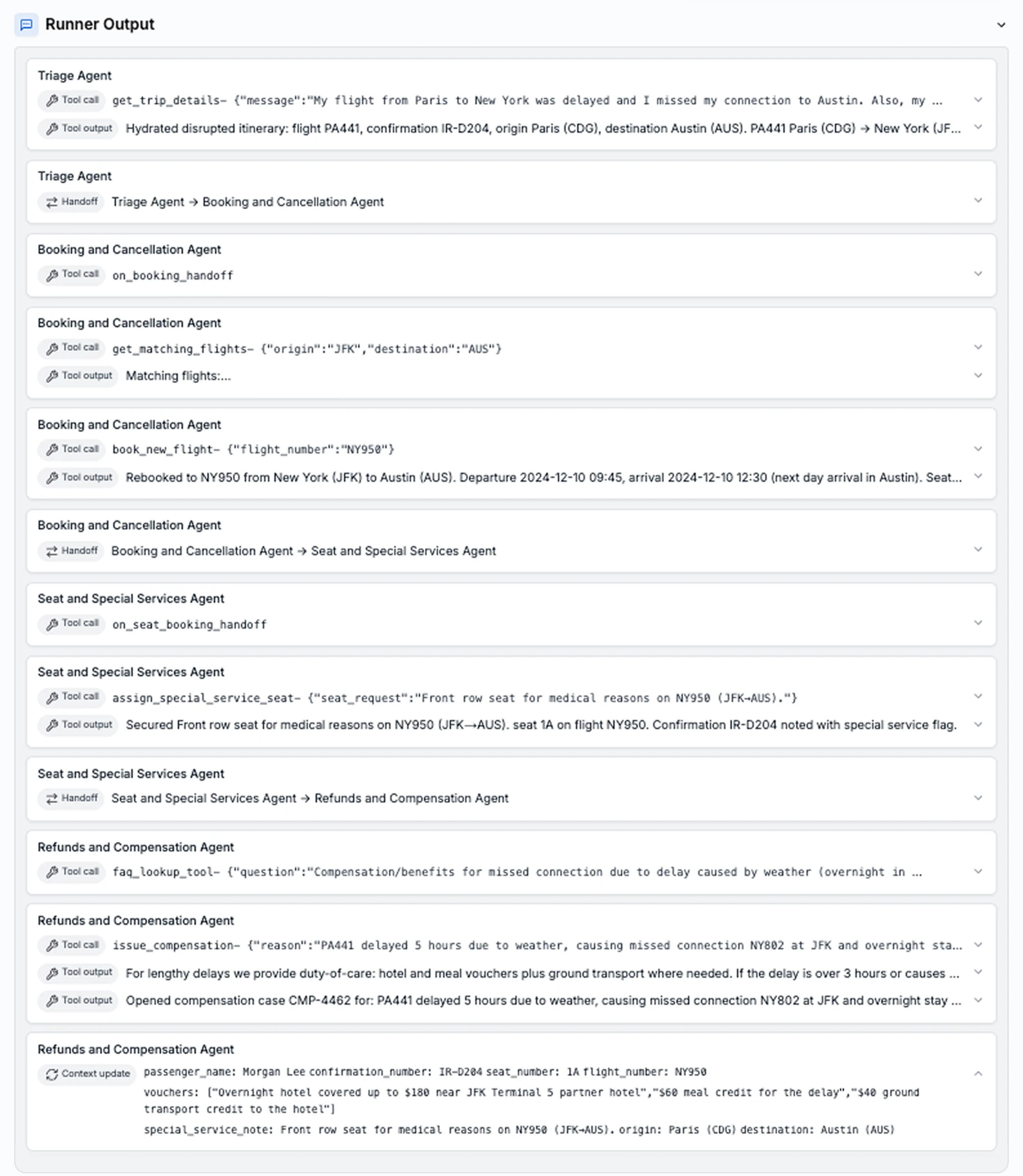
-
Spatial and Visual Reasoning: OpenAI’s own visual comparison shows GPT-5.2 making a qualitative leap. While GPT-5.1 slapped a few labels on a motherboard image, GPT-5.2 demonstrates a superior grasp of spatial arrangement and component relationships.
-
Iterative Enterprise Feedback Loop: The model excels at professional artifact generation. On an internal benchmark of junior investment banking analyst spreadsheet tasks, GPT-5.2’s average score rose from 59.1% to 68.4%. This suggests an architecture fed with high-quality, structured enterprise data, perhaps directly from tools like Excel or PowerPoint, not just scraped web text.
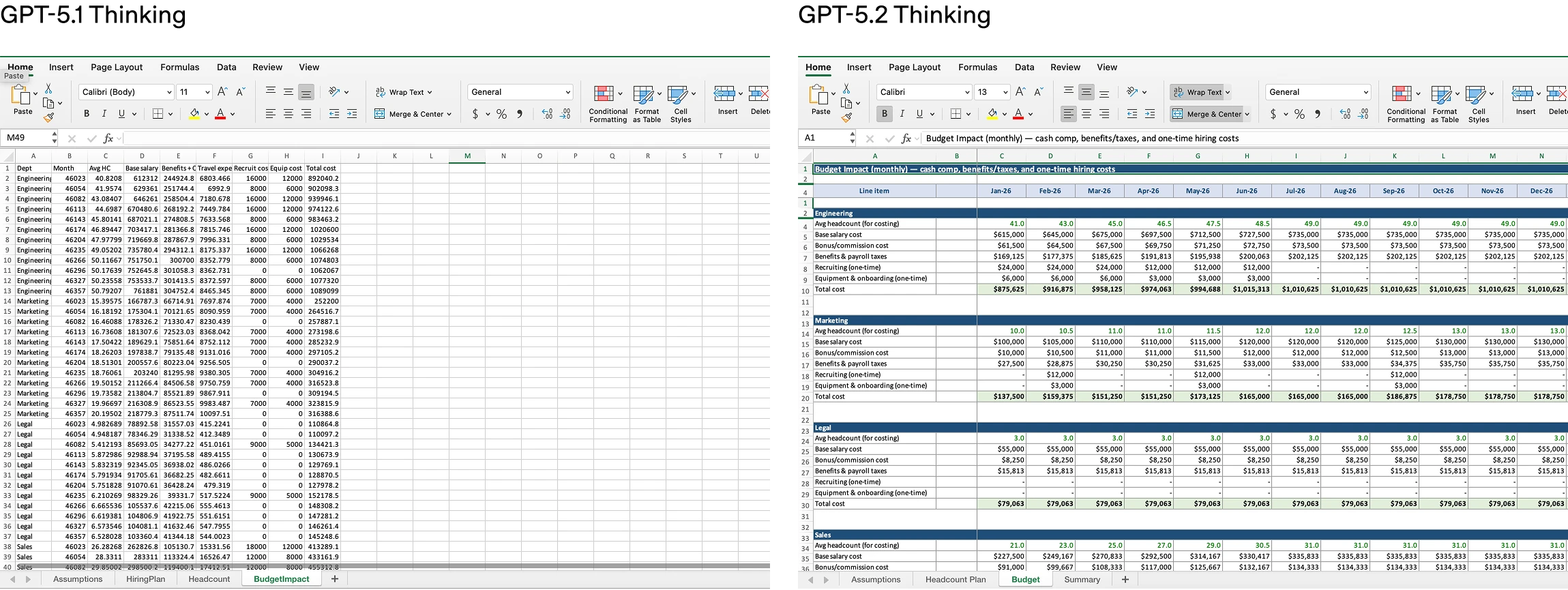
The Scalability Cage Match: NVIDIA H200, GB200, and Azure
Hardware partners are crucial to this story. The model was “built in collaboration” with NVIDIA and Microsoft Azure, explicitly naming NVIDIA’s H100, H200, and GB200-NVL72 systems. This is a signal. The GB200 NVL72 is a liquid-cooled, multi-node monster designed for ultra-large models. OpenAI is telling us GPT-5.2 is architected to exploit the latest in high-bandwidth, inter-GPU communication, likely a necessity for its large-context, high-reasoning workloads.
The Microsoft blog frames GPT-5.2 as the cornerstone for “long term success in complex professional tasks”, highlighting its “structured outputs, reliable tool use, and enterprise guardrails.” The architecture wasn’t just optimized for brainpower, it was optimized for production readiness on Microsoft’s cloud, integrating with managed identities, policy enforcement, and the Foundry agent platform.
The Lesson: Enterprise AI Demands a Systems-First Approach
GPT-5.2 shows us where the frontier is moving. The primary challenge for modern AI is no longer raw intelligence, it’s systemic reliability inside a predictable architecture. Key takeaways for architects and engineers:
- Reasoning is a Feature, Not a Bug: The explicit “reasoning token” support and dramatic ARC-AGI-2 gains show OpenAI is baking chain-of-thought logic directly into the mainline architecture. This is a departure from chatbots that are winging it.
- Context is King, but Coherence is Emperor: A massive context window is useless if the model can’t reason across it. GPT-5.2’s benchmarks suggest they’ve prioritized cross-contextual coherence above all else.
- The Unit is the Workflow, Not the Output: You’re no longer buying tokens, you’re buying completed tasks. The price premium is justified only if the model’s architectural improvements genuinely collapse multi-step workflows into fewer, more reliable API calls.
The enterprise race isn’t about who has the smartest model, it’s about who can build the most robust system. GPT-5.2 is OpenAI’s answer, an architecture forged not just in the training cluster, but in the crucible of real-world, complex, multi-step enterprise demands. The 40% price hike is the toll for crossing from prototype to production-grade platform. Whether it’s worth it depends entirely on whether your AI projects are still experiments or are now mission-critical operations.



