Every time you write a SQL query, you’re invoking magic that took decades to perfect. Every time your ACID transaction commits, you’re standing on the shoulders of researchers who fought brutal hardware constraints with nothing but mathematical rigor and sheer stubbornness.
Edgar Codd gets the Turing Award. Jim Gray gets the obituaries. Michael Stonebraker gets the keynotes.
But ask most engineers under 35 who invented cost-based query optimization, and you’ll get blank stares. Ask them who designed the SELECT statement itself, and you’ll hear “I dunno, SQL just… exists.”
This amnesia isn’t just academically embarrassing. It’s architecturally dangerous. The decisions these unsung pioneers made under extreme constraints directly dictate the trade-offs you wrestle with today, from query planning to transaction isolation to the fundamental tension between consistency and scale.
The Woman Who Made SQL Actually Work
Here’s a name that should be on every database engineer’s wall: Patricia G. Selinger.
In 1979, Selinger published what remains one of the most cited papers in database history: Access Path Selection in a Relational Database Management System. She led the team at IBM’s San Jose Research Lab that built the cost-based query optimizer for System R, the prototype that proved Codd’s relational model could actually perform.
Before Selinger’s work, query optimization was essentially a manual process. You wrote your query, the system looked at a few obvious access paths, and you prayed. If you were smart, you’d add some hints. If you weren’t, you’d wait.
Selinger’s insight was brutally practical: model the cost of different execution plans using statistics about the data, then pick the cheapest one. This sounds obvious now. In 1979, it was revolutionary. The paper introduced dynamic programming for join ordering, selectivity estimation using statistical histograms, and the fundamental cost model that every modern query optimizer, PostgreSQL, MySQL, Oracle, SQL Server, still uses today.
She wasn’t just an architect of System R. She was also instrumental in shaping the SQL standard itself, defining how SELECT, JOIN, and subqueries would work at a time when the very idea of a declarative query language was controversial. Her 1990 paper The Impact of Hardware on Database Systems, presented at the IBM Symposium on Database Systems of the 90s, was eerily prescient about how shifting hardware economics would reshape database architecture, a conversation we’re still having with disaggregated storage and NVMe.
Yet for every hundred developers who can name the “Codd rules”, maybe one can tell you who actually made those rules run fast enough to be useful.
Raymond Boyce: The Ghost Who Wrote the Language
Raymond Boyce has a footnote in history because of the Boyce-Codd Normal Form (BCNF). That’s the kind of recognition that gets you a Wikipedia stub and a mention in third-year database courses.
What he actually did was more consequential: he co-designed the original SQL language.
In 1973, Boyce and Donald Chamberlin began developing SEQUEL (Structured English Query Language) as a more accessible front-end for Codd’s relational algebra. Boyce brought a linguist’s sensibility to the design, insisting on readability and natural language structure that made SQL accessible to mere mortals, not just mathematicians.
He died tragically young in 1974, before SQL became the lingua franca of data. He never saw his creation conquer the world. He never got a Turing Award. He never even got to see the SQL-86 standard that codified his design.
The SELECT ... FROM ... WHERE syntax you use without thinking? That’s Boyce’s architecture. The way SQL reads almost like English, making it the most successful declarative language in history? Boyce fought for that when the mathematicians wanted more symbolic notation.
He also co-developed the Boyce-Codd Normal Form with Codd, but that’s the least interesting thing he did. It’s just the only thing that survived in the textbooks.
The Infrastructure That Made It All Possible
These pioneers didn’t work in isolation. They had an entire ecosystem of research infrastructure behind them, infrastructure that’s increasingly at risk of being forgotten.
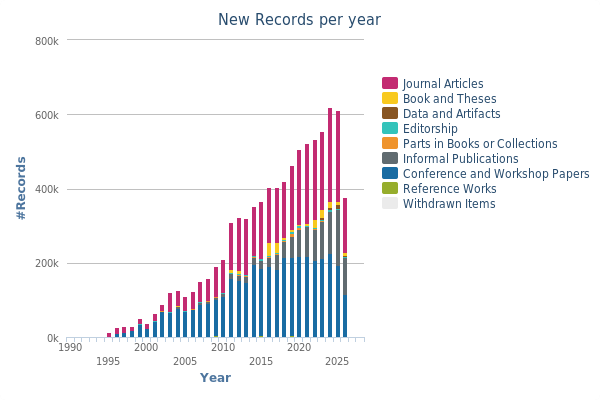
The dblp computer science bibliography, the definitive open bibliographic index of computer science research, was created in 1993 at the University of Trier by Michael Ley. By 2025, it had indexed 8 million publications and over 4 million authors. It’s the backbone of database research history.
Yet dblp operates on a shrinking budget, relying on donations from Schloss Dagstuhl and funding from the German research infrastructure. The very infrastructure that preserves the history of our field is itself becoming a historical artifact, struggling to stay alive in a world that values new content over old wisdom.
The chart below shows the explosive growth of records added to dblp, reflecting how the volume of database research has proliferated, and how much harder it becomes to identify the truly foundational contributions amidst the noise:
When you can’t fund the bibliographic infrastructure that tracks who did what, you lose the ability to properly attribute intellectual history. The pioneers get reduced to footnotes, and their hard-won design rationale gets lost.
Why This Amnesia Hurts You Right Now
You might think this is all academic nostalgia. It’s not. The erasure of these pioneers’ design decisions has real consequences for modern system architecture.
1. You’re Rediscovering Selinger’s Optimizer Issues
Every database team that hits query plan regression is fighting the same demons Selinger’s optimizer had to navigate. The trade-off between accurate cost estimation and planning overhead? She documented it. The problem of stale statistics? She analyzed it. The instability from dynamic programming join orderings? She measured it.
Yet today’s engineering teams waste months rebuilding these insights from scratch, because nobody taught them the Selinger paper. The same debates about cost model assumptions play out in Slack channels, unaware that they were settled (or at least thoroughly framed) 45 years ago.
2. The ACID vs BASE Debate Was Predicted
The architects of System R didn’t just build relational databases, they also grappled with the fundamental tension between consistency and availability that defines the modern NoSQL vs SQL debate. Jim Gray’s work on transaction processing, Andreas Reuter’s analysis of performance and reliability issues, and Selinger’s own work on distributed database logic all foreshadowed the trade-offs formalized in the CAP theorem.
The pioneers knew that ACID had costs. They chose it anyway because they understood the value of correctness in business systems. Today’s architects sometimes treat ACID as an accidental artifact of old technology, rather than a deliberate design choice with deep theoretical foundations.
3. You Inherit Constraints You Don’t Understand
The SQL standard’s restrictions, the rigid column definitions, the lack of natural version control, the impedance mismatch with code, exist for reasons that made sense in the 1970s. Hardware limitations. I/O costs. The physics of disk drives.
If you don’t understand those constraints, you can’t make intelligent decisions about when to stay within them and when to break them. The rise of projections vs real-time aggregation challenges in modern databases is a perfect example: engineers struggle because they don’t understand the design lineage of their systems.
The Architecture We Forgot to Build
The most tragic part of this historical amnesia is that we keep making the same mistakes.
In the 1970s and 80s, database researchers systematically analyzed the trade-offs between data models, query languages, and consistency guarantees. They published their findings in venues that still exist, SIGMOD, VLDB, PODS, but the institutional memory is fading.
Consider the evolution of architectural patterns from relational to event-driven. Many engineers treat event sourcing as a radical new idea, unaware that the database research community studied similar patterns under names like “temporal databases” and “historically-aware storage” for decades. The academic work on managing multimedia complex objects and object-oriented databases in the ’90s, presented at systems like the IBM Symposium on Database Systems, had already laid groundwork for modern data architectures.
The implicit system design assumptions impacting data integrity that cause production disasters today were often explicitly addressed in papers written 30 years ago. But those papers aren’t being read. The context is lost. Each generation reinvents the wheel, but with less understanding of the material science involved.
What This Means for Architects Today
If you’re designing data systems in 2026, you face a choice. You can treat the history of your field as irrelevant, a bunch of old papers by dead people that don’t apply to your cloud-native, distributed, AI-powered world.
Or you can recognize that the fundamental trade-offs haven’t changed. The constraints have shifted, storage is cheap, memory is abundant, networks are fast but unreliable, but the mathematical landscape of data management is remarkably stable.
The pioneers weren’t stupid. They were working with primitive tools, but their reasoning was often more rigorous than ours. Selinger’s cost model, Boyce’s language design, Gray’s transaction theory, these are not museum pieces. They are living intellectual capital that can inform your design decisions today.
Three practical actions for modern architects:
-
Read the original papers. Not the Wikipedia summary. The actual papers. Selinger’s 1979 optimizer paper, Gray’s transaction survey, Codd’s relational model paper. They’re all available through databases like dblp. The insights are still relevant.
-
Teach the history to your teams. Every database onboarding should include a session on who built what and why. Understanding design rationale prevents cargo-cult engineering. When your team understands why Boyce designed SQL the way he did, they’ll use it more intelligently.
-
Design with awareness of legacy. The system design principles and architectural decisions in legacy systems that frustrate you today were often brilliant solutions to problems you don’t face, and brilliant solutions to problems you’ve forgotten exist. Respect the constraints before you break them.
The Uncomfortable Conclusion
The database field has a branding problem. We celebrate the mathematicians and the theorists, Codd, Gray, Stonebraker, while forgetting the engineers who made those theories work in practice. Selinger’s optimization algorithms run billions of times a day, and almost nobody knows her name.
This isn’t just unfair. It’s inefficient. When we erase the context of our systems’ design, we lose the ability to reason about them properly. We become cargo-cult engineers, modifying systems we don’t truly understand, chasing performance improvements that the pioneers already considered and rejected for good reasons.
The next time you write a query and wonder why the optimizer chose a particular plan, remember Patricia Selinger. The next time you type SELECT, remember Raymond Boyce. The next time you assume ACID is the default, remember the decades of research that went into making it practical.
These pioneers are ghosts in the machine. The least we can do is learn their names.