Copilot’s New Tax: Why Token-Based Billing Is Forcing Developers Off The Cloud
This isn’t merely a price hike. It’s a fundamental shift in the developer-AI relationship, directly catalyzing a parallel, unstoppable trend: the rise of capable, local LLMs.
The Meter Starts Running: GitHub’s Pricing Pivot
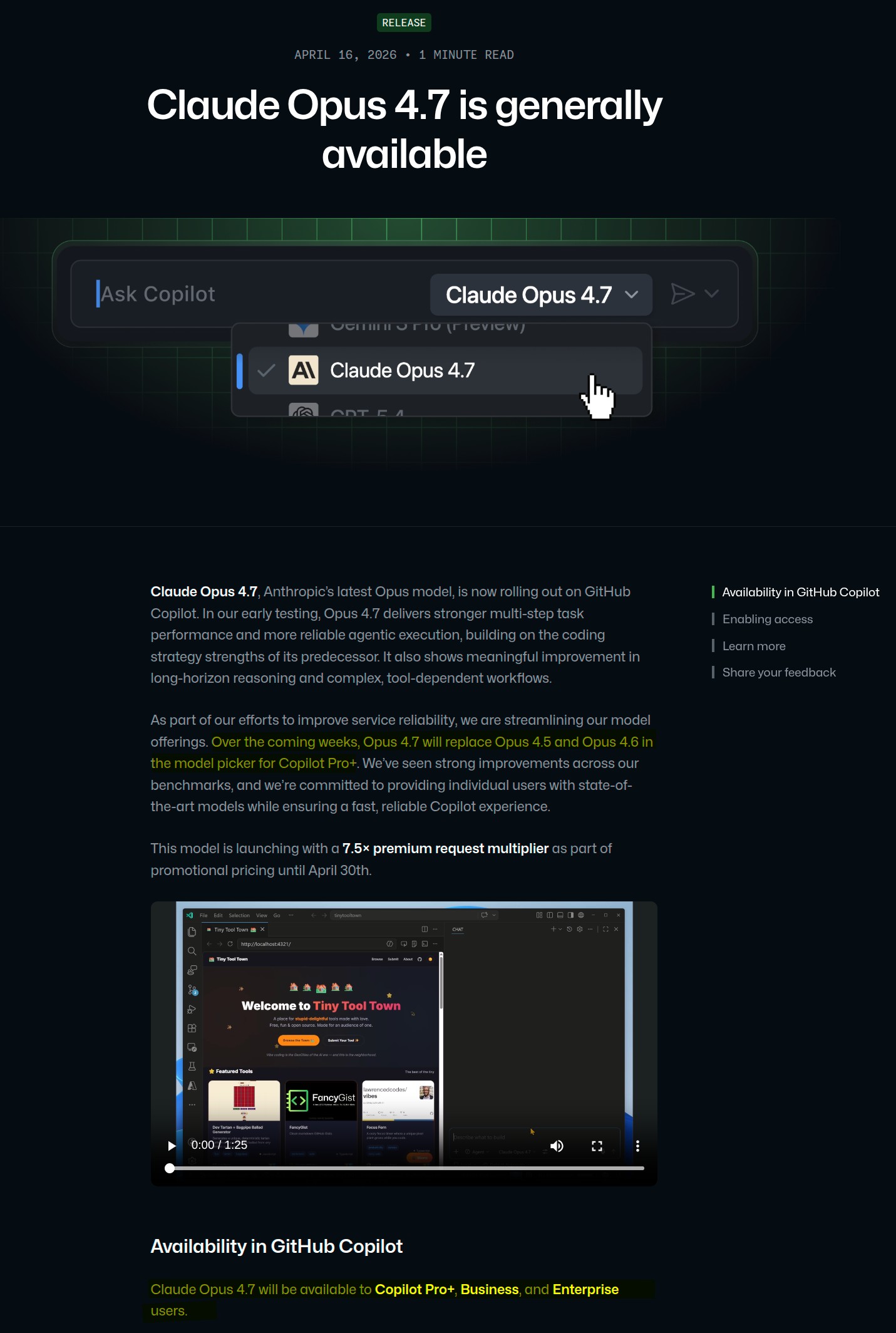
Let’s decode the move. Under the new system, your $10/month Copilot Pro plan grants you $10 worth of AI credits at API rates. Gone are the familiar “300 premium requests.” Instead, every interaction is metered by tokens consumed, scaled by the model used. The official model multiplier table reveals the new calculus: Claude Opus 4.7 now carries a 27x multiplier. That single agentic session you ran last week? That could now cost you your entire month’s $10 credit.
The community’s FAQs to GitHub admins tell a story of confusion and alarm. “Will there be any free models anymore with this shift?” Answer: “No.” “Will unused AI credits roll over?” Answer: “No.” The message is clear: pay for what you use, down to the token, and don’t expect leftovers.
The most revealing comment came from a user trying to estimate their new bill: “I expect that there will be granularity down to the penny… a single session with something like Opus or GPT-5.5 while doing a plan and implement can easily run into the realm of $30-40.” For developers used to a predictable $10 or $39/month, this is a budgetary earthquake. It transforms AI from a semi-reliable tool into a resource you must actively ration.
The Local Reality Check: It’s Already Here
While cloud providers jockey for your dollars, the performance floor for local inference has been quietly demolished. Developers are already voting with their local GPUs.
Take the experience of one engineer who runs Qwen3.6-35B on an M2 Max MacBook Pro with 64GB RAM.
In the last month, they’ve one-shotted landing pages, built full frontend/backend features, and fixed complex race condition bugs, tasks they “would have called fantasy on this hardware a year ago.” While acknowledging that cloud models like Claude Opus are still faster (“3-4 minutes vs. 8-9 minutes” for a landing page), the trade-off is stark: latency for sovereignty.
Zero Usage Anxiety
No more token counting. The cost is sunk into the hardware.
Built-in Privacy
Client code, internal repos, and half-baked ideas never leave your machine.
Radical Cost Control
A one-time purchase versus a recurring, unpredictable operational expense.
An analysis piece from The Register frames this as an enterprise no-brainer: “you could buy one machine that sits in a corner, basically silent, that could serve an entire dev team with this smaller model… that’s less than the cost of one developer for a year.”
The tooling ecosystem is maturing rapidly. Projects like Cline and Tabby offer direct, open-source alternatives to Copilot’s agentic features, while Claude Code already supports local LLM backends. The harnesses are catching up.
The Technical Leap: Why Now Isn’t Five Years Ago
- Mixture-of-Experts (MoE): Models like Qwen3.6-35B only activate a subset of parameters per token (around 3B), drastically reducing memory bandwidth requirements. This is why a 35B-class model now runs briskly on a high-end laptop where a dense 27B model would crawl.
- Test-Time Scaling: Inspired by frontier models like OpenAI’s o1, smaller local models can be instructed to “think longer.” By dedicating more compute (time) per token, they can achieve higher-quality outputs, partially compensating for fewer parameters.
Google’s recent Gemma 4 release with Multi-Token Prediction (MTP) pushes this further, fundamentally changing the generation loop to predict multiple future tokens simultaneously. This isn’t just a post-processing trick like speculative decoding, it’s a core architectural change that can improve local throughput by 2-3x on the same hardware.
Consider the performance leap: “A year ago this needed an A100. Today it runs on a… MacBook M2 Max 64GB laptop at roughly 27 tokens per second.” The curve is bending sharply.
The Hybrid Future: Pragmatism Over Purity
As one commenter astutely noted, “The future isn’t local OR frontier, it’s local AND frontier so you only spend money when you absolutely need to.”
Local for Iteration & Privacy
Use your local Qwen or Gemma 4 instance for rapid prototyping, internal code review, and routine tasks where absolute top-tier reasoning isn’t critical. This is where Local 27B models prove themselves as viable alternatives to monthly cloud subscriptions.
Cloud for Final Polish
When you hit a wall, or need that final architectural review from a deep-reasoning model like Opus, you spin up a cloud session. You pay the premium, but only for the critical, high-value reasoning moments.
This is the cost-efficient workflow the new pricing forces. It’s also the workflow that tools are beginning to support natively, with agents capable of routing tasks between local and cloud backends based on complexity.
The Path Forward: Practical Steps for Developers
1. Assess Your Hardware
The VRAM requirements for competing with closed-source models on consumer hardware have standardized. A machine like a Mac Studio with 96GB unified memory or a PC with 24GB+ on a single GPU (like an RTX 4090) is now the effective starting point for serious work. Be wary of Apple’s hardware restrictions, but know that the M-series Macs, with their matmul acceleration, are surprisingly capable.
2. Choose Your Stack
Start with a user-friendly manager like Ollama or LM Studio. These abstract away the complexity of model formats and quantization. For agentic workflows, explore Cline (a VS Code extension) or Claude Code configured with a local endpoint.
3. Benchmark Relentlessly
Don’t accept “it’s slower.” Measure it. How many seconds slower is Qwen for a git helper? How much longer does a React component take? Quantify the latency tax against the privacy and cost benefits. Tools now exist to help you do this.
4. Integrate Securely
Never run a local agent in “YOLO mode” on your main system. Use Docker containers or virtual machines with strict resource and network constraints. The security model of local tools varies wildly, understand it.
5. Start Hybrid
Keep your cloud subscription for now. Run a local model in parallel for a month. Use the cloud for the hardest 20% of tasks, and the local model for the rest. Watch your usage dashboard. The economic rationale will become brutally clear.
Conclusion: The End of Blind Cloud Faith
GitHub’s metered billing isn’t an isolated business decision. It’s a market correction. The “AI for pennies” era, fueled by venture capital subsidizing your workflow, is sunsetting. What rises in its place is a more mature, diversified ecosystem.
The hyperscale cloud will remain for training colossal models and serving inference at planetary scale. But for the individual developer, the small team, or the enterprise with sensitive IP, the economics are tilting definitively towards the metal on your desk. The cloud is becoming a specialty tool, the scalpel for your most complex tasks, not the all-purpose workbench.
The next 12-24 months will see this trend accelerate. As open-source tooling enables unified local training and inference workflows, and as models continue their march down the performance-per-watt curve, the primary barrier to local adoption will shift from hardware to habit.
The question is no longer if local LLMs will take over a significant portion of development workloads, but when you’ll start building the muscle memory. The meter is running. Your move.
Ready to take control? Start your journey with our guide to setting up your first local coding agent.