Code-as-Middleware: The 98% Token Reduction That Could Make Local AI Agents Actually Viable
The current generation of AI agents has a dirty secret: they’re drowning in their own context windows. Every tool definition, every intermediate result, every piece of data that flows between services gets crammed into the model’s limited attention span. For developers running agents locally, where context windows are smaller and compute is precious, this inefficiency isn’t just expensive, it’s crippling.
Anthropic’s recent code execution pattern proposes a radical solution: stop feeding everything to the model. Instead, have the agent write code that orchestrates tools directly. The result? A 98.7% reduction in token usage in their demonstration case. But here’s where it gets interesting: this “innovation” isn’t entirely new, and that’s precisely why it might actually work.
The Context Window Tax on Agentic Systems
Traditional MCP (Model Context Protocol) implementations suffer from two fundamental inefficiencies that scale linearly with complexity:
- 1. Tool Definition Bloat: Most MCP clients preload every available tool definition into the context window. When you’re connected to dozens of services, each with hundreds of possible actions, this can easily exceed 150,000 tokens before the model even sees your actual request. As the Anthropic team notes, this creates a scenario where “agents need to process hundreds of thousands of tokens before reading a request.”
- 2. Intermediate Result Amplification: When an agent transfers a 50,000-token meeting transcript from Google Drive to Salesforce, that data passes through the model twice, once as a tool result, once as a parameter to the next tool call. For complex workflows, this multiplier effect can break even the most generous context windows.
The problem compounds brutally for local deployments. While cloud APIs can throw 128K+ context windows at the problem, a local developer running Llama 3.1 8B might be capped at 8K. Suddenly, that meeting transcript workflow isn’t just inefficient, it’s impossible.
Code-as-Middleware: The Pattern
The solution is conceptually simple: treat the model as a code generator, not a tool caller. Instead of executing tools directly, the agent writes a script that imports tool functions and orchestrates them in a standard execution environment.
Here’s the concrete implementation from Anthropic’s blog:
// File system structure of available tools
servers/
├── google-drive/
│ ├── getDocument.ts
│ └── index.ts
├── salesforce/
│ ├── updateRecord.ts
│ └── index.ts
// Individual tool implementation
// ./servers/google-drive/getDocument.ts
import { callMCPTool } from "../../../client.js";
interface GetDocumentInput {
documentId: string;
}
interface GetDocumentResponse {
content: string;
}
export async function getDocument(input: GetDocumentInput): Promise<GetDocumentResponse> {
return callMCPTool<GetDocumentResponse>('google_drive__get_document', input);
}
// Agent-generated orchestration code
import * as gdrive from './servers/google-drive';
import * as salesforce from './servers/salesforce';
const transcript = (await gdrive.getDocument({ documentId: 'abc123' })).content;
await salesforce.updateRecord({
objectType: 'SalesMeeting',
recordId: '00Q5f000001abcXYZ',
data: { Notes: transcript }
});
The agent discovers tools by exploring the filesystem, listing directories, reading specific files, loading only the definitions it needs. The data flows through JavaScript variables, never re-entering the model’s context.
The Numbers: From 150K to 2K Tokens
In Anthropic’s example, a workflow that previously consumed 150,000 tokens now uses 2,000 tokens, a 98.7% reduction. This isn’t incremental optimization, it’s architectural surgery.
The breakdown is revealing:
– Tool definitions: ~148K tokens eliminated through on-demand loading
– Intermediate results: ~50K tokens saved by avoiding data round-trips
– Control flow: Additional savings from code-based logic vs. model-evaluated conditionals
For local AI enthusiasts, this is the difference between requiring a 70B parameter model with 128K context and running an 8B model with 8K context. The agent that once needed an A100 can now run on your laptop’s RTX 4090.
The Local AI Game-Changer
The implications for local deployment are profound. As one developer noted in discussions, “context limits hit way harder when you’re running smaller models.” A pattern that reduces context requirements by 50x doesn’t just improve performance, it fundamentally changes what’s possible.
Consider a complex agent that:
– Searches a codebase for relevant files
– Analyzes dependencies across multiple services
– Generates reports by querying several databases
– Updates project management tools
With traditional tool calling, this might require 200K+ context. With code-as-middleware, the model generates a ~500-line script that does the work offline, then returns a summary. The heavy lifting happens in the execution environment, not the model’s attention mechanism.
The privacy angle is equally compelling. Sensitive data “never enters model context, flows directly between tools.” For companies handling PII, financial data, or health records, this means the agent can orchestrate workflows without exposing sensitive information to the model provider, or even to your own logs.
The “Innovation” That Wasn’t (And Why That Matters)
Here’s where the controversy begins. Within hours of Anthropic’s announcement, the AI community pointed out that Hugging Face’s smolagents framework has used this pattern for months. The sentiment was blunt: “Anthropic copying other people’s ideas again and presenting it as their own.”
And they’re not wrong. The smolagents library explicitly uses model-generated code instead of JSON tool calls. The pattern existed. What Anthropic contributed was:
- Explicit framing as a runtime design pattern with clear architectural boundaries
- Quantification of token savings with concrete examples
- Integration with MCP as a standardized protocol
- Validation from Cloudflare’s independent discovery (they call it “Code Mode”)
The frustration is understandable. When a major AI lab “announces” a community-discovered pattern, it can feel like appropriation. But there’s value in institutional validation. Cloudflare independently arriving at the same solution suggests this isn’t a hack, it’s a natural evolution of agent architecture.
As one developer put it in a more measured take: “what stood out to me in the Anthropic post is how explicitly they frame it as a runtime design and quantify the token savings.” The searchable filesystem approach to tool definitions was particularly praised as “a very clean way to avoid preloading huge schemas.”
The Sandboxing Imperative
The elephant in the room is security. Running model-generated code locally is a “security nightmare” if done naively. The code could contain malicious operations, infinite loops, or unintended side effects.
The solution is aggressive sandboxing. As security-minded developers emphasize, “the whole approach should depend on strong sandboxing.” The typical recommendation is:
– Containerization: Fresh containers without network access for each execution
– Resource limits: CPU, memory, and timeout constraints
– File system isolation: Read-only access except to designated workspace directories
– API token scoping: Minimal permissions for the MCP client
Anthropic’s own Claude Code implementation uses a sandboxed Node.js environment with strict resource limits. The overhead is real, containers take seconds to spin up, but for many workflows, this is still faster and cheaper than processing tokens through a massive model.
Beyond Token Reduction: Emergent Benefits
The pattern enables capabilities that go far beyond efficiency:
- Progressive Disclosure: Agents can explore tool hierarchies dynamically. A
search_toolsfunction allows finding relevant tools without loading all definitions. Detail-level parameters let agents fetch just names, names with descriptions, or full schemas, conserving context strategically. - Stateful Execution: Agents can persist intermediate results to the filesystem, enabling resumable workflows. A data processing job that runs for hours can checkpoint its progress, surviving interruptions.
- Skill Accumulation: Perhaps most intriguingly, agents can save successful code snippets as reusable functions. Anthropic describes this as building a “toolbox of higher-level capabilities.” An agent that figures out how to migrate data between two services can save that function, evolving from a one-shot code generator to a cumulative skill builder.
- Privacy-Preserving Tokenization: For ultra-sensitive data, the MCP client can automatically tokenize PII. Email addresses become
[EMAIL_1], phone numbers become[PHONE_2], while the real data flows directly between tools via a secure lookup table. The model never sees the actual values, even in logs.
Implementation: A Glimpse at the Future
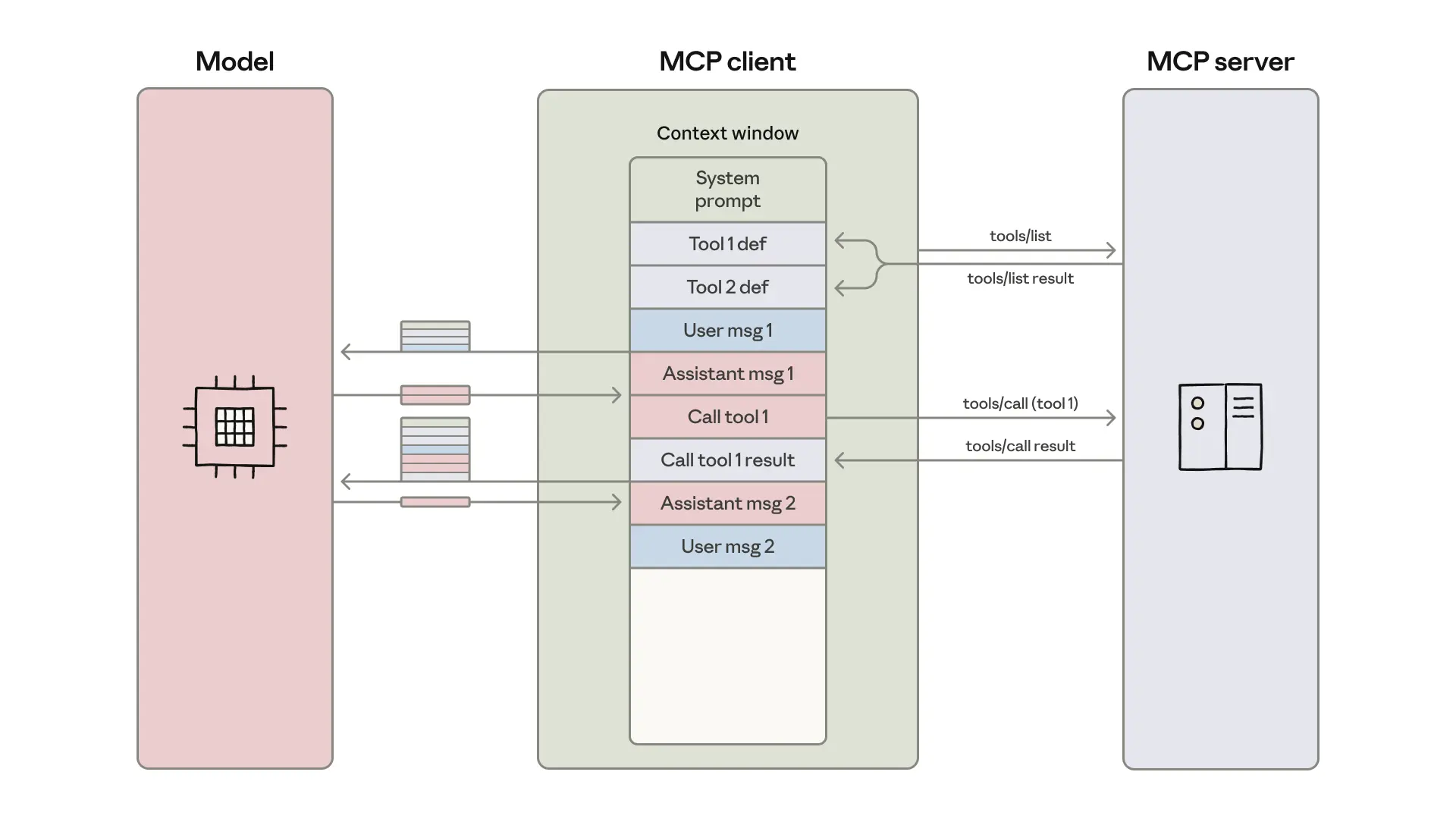
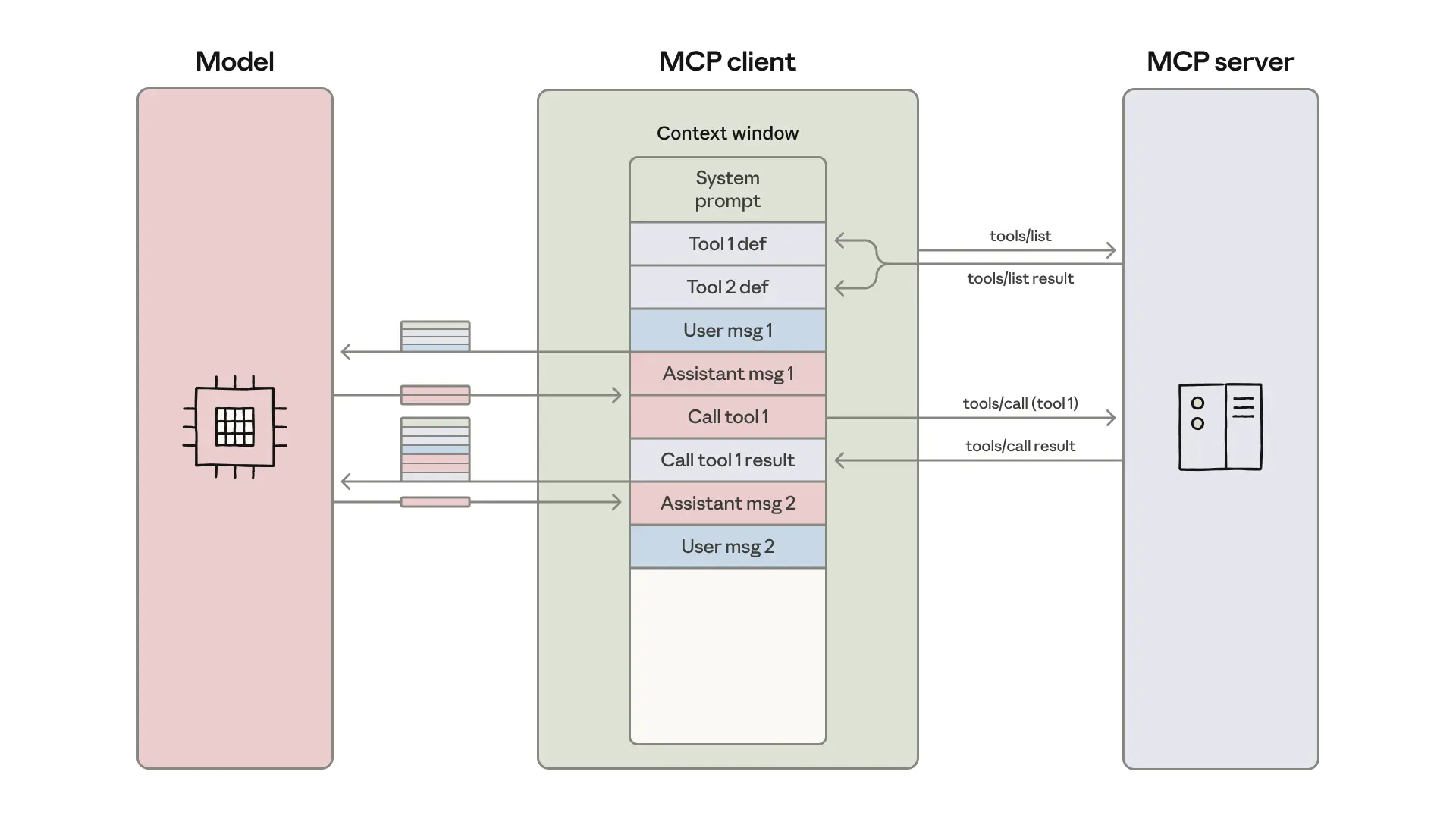
The pattern is already manifesting in production systems. The image below illustrates how the traditional MCP client loads everything into context versus the code execution approach:
In practice, an agent might generate code like this for a complex workflow:
// Multi-step research agent
import * as web from './servers/web-search';
import * as db from './servers/internal-db';
import * as analysis from './servers/text-analysis';
// 1. Search for recent papers
const searchResults = await web.search({
query: "code execution agents MCP 2024",
maxResults: 20
});
// 2. Filter for relevant ones
const relevantPapers = searchResults.filter(paper =>
paper.abstract.includes('token reduction') ||
paper.abstract.includes('code generation')
);
// 3. Extract key findings
const findings = await Promise.all(
relevantPapers.map(async paper => {
const fullText = await web.fetchFullText(paper.url);
const summary = await analysis.extractKeyFindings(fullText);
return { ...paper, summary };
})
);
// 4. Save to database
for (const paper of findings) {
await db.insert({
table: 'research_findings',
data: {
title: paper.title,
summary: paper.summary,
source: paper.url,
discovered_at: new Date().toISOString()
}
});
}
console.log(`Processed ${findings.length} relevant papers`);
The model generates this script using ~2K tokens, then the execution environment runs it. The agent only sees the final console log, not the 20 search results, 15 full-text papers, or individual database insertion calls.
When to Use This Pattern
Code-as-middleware isn’t a universal replacement for tool calling. It’s a tradeoff:
- Use it when:
– Agent needs to orchestrate many tools (100+ definitions)
– Workflows involve large data transfers between tools
– Privacy requirements mandate data minimization
– Running locally with limited context windows
– Cost is a primary constraint (cloud API fees) - Stick with direct tool calls when:
– Simple workflows with few tools
– Need for real-time model intervention at each step
– Security requirements prohibit code execution entirely
– Debugging transparency is critical (easier to trace individual tool calls)
The pattern represents a maturation of agent architecture. Early agents were chatbots with tool access. Current agents are sophisticated orchestrators that can write their own execution plans. The next evolution is agents that build and reuse their own tooling, a software development team compressed into a single model.
For the local AI community, this could be the inflection point where complex agents graduate from research curiosity to practical utility. When a pattern cuts resource requirements by 50x, it doesn’t just optimize the old world, it enables a new one.
The controversy around attribution will fade. The pattern will be implemented, improved, and standardized. What matters now is that developers running models on consumer hardware can finally build agents that were previously confined to data centers. That’s not just an optimization, that’s a democratization.