For the past several years, the AI infrastructure market has been dominated by a single, monolithic paradigm: buy by the rack, or don’t bother. NVIDIA and AMD poured their engineering might into power-hungry, ultra-dense OAM/SXM modules designed for hyperscale data centers, think 11kW compute nodes and liquid-cooled racks. It was a brilliant, high-margin play, but it left a glaring, underserved market entirely out in the cold. Today, AMD is exploiting that opening with surgical precision.
The Instinct MI350P is not merely a new product, it’s a strategic correction. By bringing its flagship CDNA 4 architecture to the humble PCIe card, AMD is directly challenging the assumption that serious AI acceleration is only for those buying hardware by the rack. This move isn’t just about specs, it’s about finally offering a drop-in path for the rest of the world: the on-premises enterprise, the research lab, the startup that needs to scale inference without a seven-figure CapEx commitment.
Let’s be clear: the MI350P is not a salvaged or cut-down part. It’s a bespoke, single-I/O die chiplet design built from the ground up for the PCIe form factor. This is a deliberate attempt to own a segment NVIDIA has all but abandoned in its current generation. For anyone not named Meta, Google, or Microsoft, this might be the most important AI hardware launch of the year.

A PCIe Card That’s Actually Half a Server
The technical narrative here is elegantly simple: the MI350P is functionally half an MI350X accelerator forced to fit a very different set of constraints.
The comparison data says it all. Let’s look at the core specs.
| GPU | MI350P | MI350X |
|---|---|---|
| Compute Units | 128 | 256 |
| Matrix Cores | 512 | 1024 |
| Memory | 144GB HBM3E | 288GB HBM3E |
| Memory Bandwidth | 4TB/sec | 8TB/sec |
| MXFP8 Performance | 2.3 PFLOPS | 4.6 PFLOPS |
| I/O | PCIe Gen5 x16 | PCIe Gen5 x16 + 7x Infinity Fabric |
| TBP | 600W (Optional 450W mode) | 1000W |
| Form Factor | PCIe CEM, 10.5" FHFL DS | OAM |
AMD achieved this not by binning failed MI350X dies, but by leveraging a key advantage of its chiplet architecture. The MI350X uses two I/O dies, each with four accelerator complex dies (XCDs) stacked on top. The MI350P uses just one I/O die with four XCDs. This isn’t a compromise, it’s a clean, scaled version of the same silicon, clocked identically at up to 2.2GHz.
This halving extends to memory: four HBM3E stacks instead of eight, delivering a still-massive 144GB at 4TB/s of bandwidth. Crucially, it retains the full CDNA 4 feature set, including native support for MXFP6 and MXFP4 data types critical for efficient LLM inference. The result is a card that, according to Tom’s Hardware, offers a theoretical 20% advantage in FP64, 43% in FP16, and 39% in FP8 compute over NVIDIA’s current PCIe flagship, the H200 NVL.
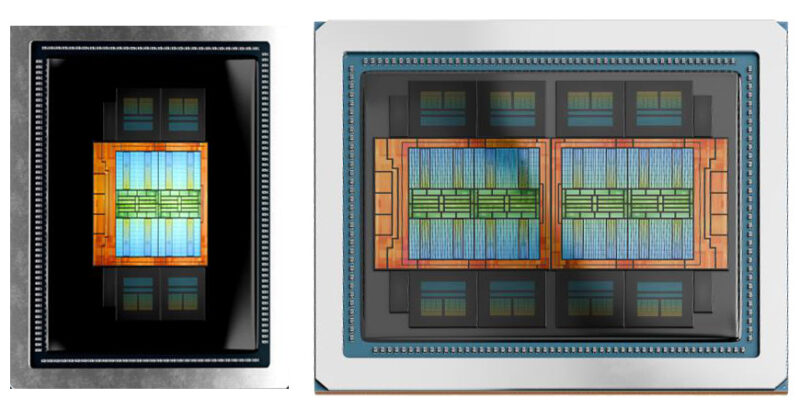
The physical design is aggressively pragmatic. It’s a full-height, full-length (FHFL), dual-slot, passively cooled card designed to dissipate up to 600W, the maximum allowed by the PCIe CEM spec, driven by a 12V-2×6 power connector. For servers that can’t handle that thermal load, AMD provides a configurable 450W mode. Eight of these can be installed in a single air-cooled server rack. The trade-off is significant: with no direct Infinity Fabric links between cards, communication is limited to the PCIe bus. This makes the MI350P ideal for running many independent models concurrently (e.g., multi-tenant inference) rather than spreading a single massive model across eight GPUs.
Filling the Market Void NVIDIA Created
The MI350P exists because, for the last couple of years, the high-end AI accelerator market forgot about the PCIe slot.
As noted by ServeTheHome, both AMD and NVIDIA focused obsessively on modular accelerators destined for compute trays and racks. The economics were simple: they sold as fast as they could be made. This left a “hole in the overall market”, as Patrick Kennedy articulated, for customers who couldn’t retrofit an 11kW AI node into their existing data center. Older facilities with legacy power and cooling simply couldn’t participate.
AMD attempted to plug this gap with Radeon AI Pro series cards, but these workstation-grade GPUs fundamentally lacked the memory capacity, bandwidth (HBM), and architectural optimizations of a server-class part like an Instinct. They were a stopgap, not a solution.
The MI350P is that solution. It makes CDNA 4 acceleration accessible to any organization with a standard, air-cooled PCIe server, which is to say, nearly every enterprise data center on the planet. This is not a niche. This is the vast middle ground between a single RTX gaming card and a $2 million Blackwell rack.
“Designed to deploy inference on premises within your current data center’s power, cooling and rack infrastructure.”
AMD’s official messaging nails the use case: "designed to deploy inference on premises within your current data center’s power, cooling and rack infrastructure." For many, the prospect of avoiding a complete, disruptive infrastructure overhaul is more compelling than a doubling of theoretical peak performance.
The Software Elephant in the Room (And It’s Getting Smaller)
No analysis of an AMD data center GPU launch is complete without addressing ROCm. For years, the narrative was simple: "Great hardware, but the software…" That chapter is being aggressively rewritten.
AMD is touting a mature, unified enterprise AI software stack built on ROCm. The latest version, ROCm 7.0, promises Day 0 support for PyTorch 3.1, TensorFlow, JAX, ONNX Runtime, vLLM, and Hugging Face Accelerate, with full containerized deployments via the AMD GPU Operator for Kubernetes.
The barrier to entry is dissolving. More importantly, the target workload here is inference and RAG (Retrieval-Augmented Generation), not massive-scale training. The memory bandwidth importance for AI inference performance is paramount, and with 4TB/s of HBM3E, the MI350P is well-equipped. For inference, the software requirements are less Byzantine than for cutting-edge, distributed model training. If ROCm is stable, documented, and integrated into the major inference-serving frameworks, many of the traditional objections fade away.
Key Software Features
- Day 0 Support for PyTorch 3.1
- Fully Containerized via Kubernetes
- Optimized for MXFP6/MXFP4 Inference
- Mature ROCm Driver Stack
The partitioning support also remains intact from the MI350X, allowing a single MI350P to be split into up to four virtual GPUs (vGPUs), each with 36GB of HBM3E. This is a killer feature for cloud providers and enterprises looking to maximize hardware utilization across teams.
What This Means for NVIDIA and the Ecosystem
With this move, AMD has executed a classic flanking maneuver. While NVIDIA focuses its Blackwell generation on the monolithic, rack-scale B200/B100, AMD is planting a high-performance flag in territory NVIDIA has tactically ceded. There is no PCIe Blackwell GPU on the horizon, leaving the H200 NVL as the incumbent, and the MI350P appears to outspec it handily.
This creates a fascinating dynamic in the broader rival hardware dominance strategies within the AI infrastructure ecosystem. NVIDIA’s strategy is vertical integration and ecosystem lock-in at the very top of the market. AMD’s, increasingly, is flexibility and accessibility. The MI350P is a tool for deployment, not just pure computation. It fits into existing server procurement processes, existing data center management tools, and existing capital expenditure budgets.
It also forces an interesting economic comparison between enterprise accelerators and consumer inference hardware. While a Mac Studio with unified memory is powerful for an individual, scaling that to serve hundreds of concurrent enterprise users is a different problem. The MI350P offers a more traditional, scalable server-based path.
The Bottom Line: Practical Power Wins
The AMD Instinct MI350P is a recognition that not every AI workload needs, or can justify, a hyperscale deployment. It’s a bet that the next wave of AI adoption will come from enterprises running smaller, specialized models on-premises, where data sovereignty, latency, and predictable costs trump raw petaflops.
By delivering the full CDNA 4 architecture on a PCIe card, AMD isn’t just selling a chip, it’s selling a pragmatism that has been sorely missing from the high-stakes AI hardware race. It offers a bridge for the countless organizations left behind by the "rack-scale or bust" mentality. For them, the MI350P isn’t the second choice, for the first time in years, it might be the only sensible one.
Pricing and availability remain the final unknowns. If AMD prices this aggressively, avoiding the temptation to simply halve the cost of an MI350X module, it could become the default choice for on-premises AI inference. If it’s priced as a premium exotic, it remains a curiosity. But the strategic move is clear: AMD is no longer just competing for the cloud titans’ business. It’s now seriously competing for yours.