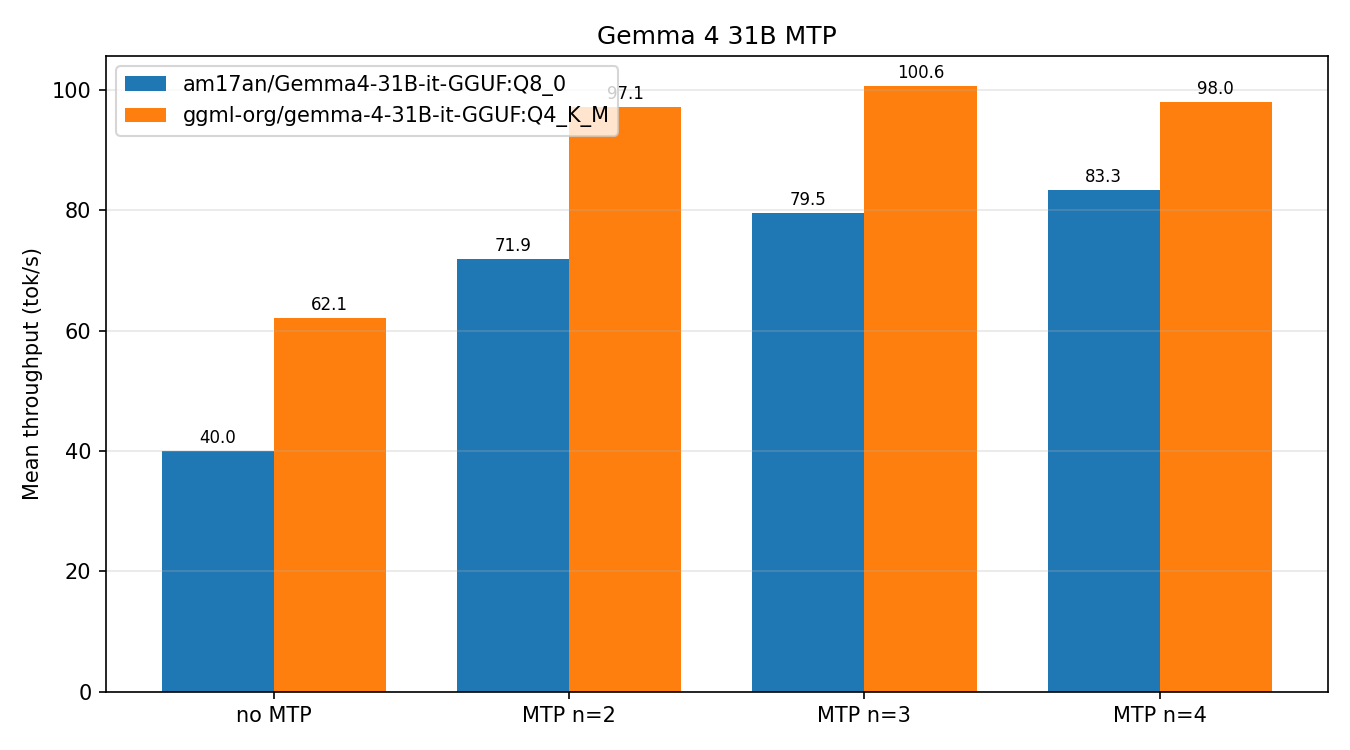
Gemma 4 MTP Just Landed in llama.cpp, And It’s Turning 12GB GPUs Into Speed Demons
The merge of Gemma 4 MTP support into llama.cpp b9549 enables speculative decoding that doubles local inference speeds on consumer hardware. Real benchmarks from the community reveal surprising caveats.