
Eight years ago, a retailer set out to build a modern, scalable Order Management System. They ended up with 24 Spring Boot microservices that process 300,000 transactions daily, orchestrated through a central Camunda instance, sharing a single database, and requiring a custom Python tool just to coordinate deployments.
The architecture diagrams look like microservices. The operational reality is a distributed monolith that manages to be worse than the monolith it replaced.
This is the story of how integration middleware, specifically, an orchestration engine that evolved into a “bus with opinions”, became the tightest coupling point in the system. And why fixing it requires admitting that your services aren’t actually services at all.
When the Orchestrator Becomes the Monolith
The original sin was architectural: no two services talk directly. Everything routes through a central Camunda orchestrator over RabbitMQ, plus a homegrown mini-BPMN framework for correlations and retries. What started as a workflow coordinator gradually mutated into a message bus that happens to have strong opinions about how your business logic should flow.
The result? Every release is a major release. Non-trivial changes touch 50% or more of the services. BPMN changes aren’t backwards-compatible with in-flight process instances, eliminating rollback options entirely. When your orchestrator holds the state for in-flight orders, you can’t simply deploy a new version of a workflow definition without either waiting for existing processes to complete or writing complex migration scripts.
This pattern, where an orchestration layer becomes the de facto API contract, is what turns modern system architecture demands into wishful thinking. You’ve built a distributed system that behaves like a monolith, except now you also have network latency and distributed debugging.
The Seven-Headed Hydra of Shared State
The orchestrator isn’t the only coupling point. The system shares a “god model” and a single database across all 24 services, packaged as a common/core dependency. Change a field in the shared library, and you’re looking at coordinating 24 deployments. The shared library has become the de facto API contract, meaning services can’t evolve independently because they’re bound at the compile-time level.
Add to this: shared libraries for logging, monitoring, testing, and infrastructure connections (RabbitMQ, Kafka, Couchbase, Elasticsearch). When everything shares everything, you’ve achieved the worst of both worlds, the operational complexity of microservices with the deployment coupling of a monolith. As one architect noted in analyzing similar failures, this is essentially one problem wearing seven different hats.
Configuration management is similarly centralized and fragile: 90% of configuration lives in Helm values and environment variables. Changing a threshold requires a commit, pipeline run, and pod restart. There’s no real audit trail beyond logs, with one document per order being updated repeatedly without versioning, making debugging “how did this order end up in this state” a forensic exercise in grepping through distributed logs.
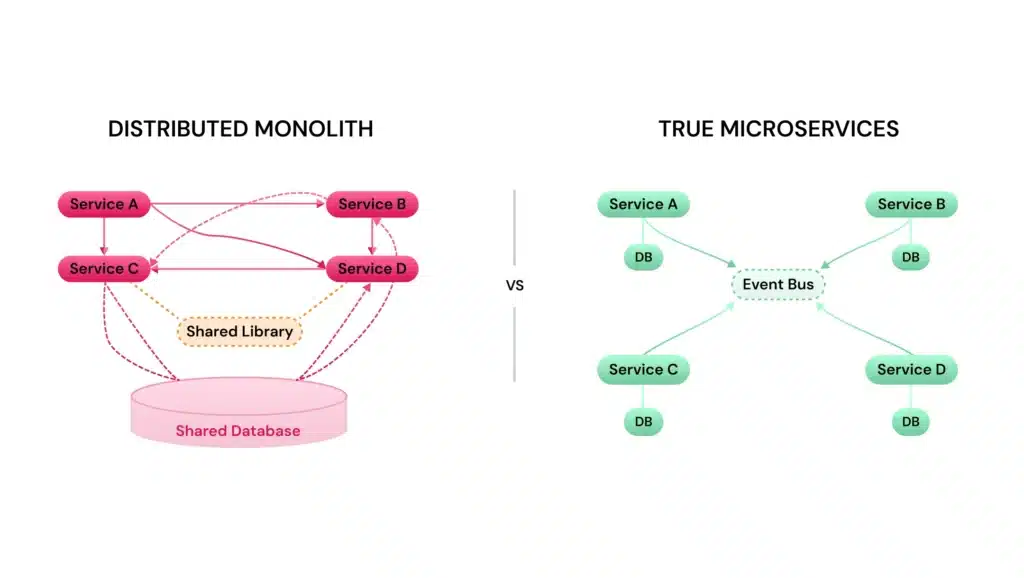
The Distributed Monolith Trap
This architecture has a name: the distributed monolith. It’s what happens when you decompose a system into separate services that can’t be developed, tested, or deployed independently. The services are physically distributed, different containers, separate repositories, maybe even a service mesh, but they behave like a tightly coupled monolith.
The characteristics are unmistakable:
- Shared persistent state: Multiple services hammering the same database tables, preventing independent schema evolution
- Excessive synchronous communication: Request chains that traverse multiple services, where one slow component degrades the entire flow
- Coordinated deployments: The smoking gun, if you can’t deploy Service A without deploying Service B, you don’t have microservices
- Shared libraries: Compile-time dependencies that force coordinated releases
The retailer in question has all of these, plus a homegrown Python tool wired into CI/CD that decides build order, opens merge requests across repositories to bump shared libraries, and sequences deployments. If you need a bespoke coordination tool to ship code, your services aren’t independent. Full stop.
The Political Load-Bearing Problem
Here’s where it gets spicy: Camunda is politically load-bearing. Management is attached to it, and it’s the only real monitoring and reprocessing capability the team has today. Developers open Camunda Cockpit every morning to unblock stuck orders. “Just drop Camunda” is easy to say but operationally terrifying when it’s the only visibility you have into order state.
This creates a perverse incentive structure. The orchestrator is both the problem (tight coupling, single point of failure) and the only solution (operational visibility, manual intervention capabilities). Replacing it requires not just technical migration but rebuilding operational muscle, implementing proper sagas, event sourcing for state reconstruction, and distributed tracing that can actually answer “where is my order” without a GUI console.
The legacy orchestration migrations many teams are facing today follow similar patterns: the tool that was supposed to coordinate workflows became the workflow itself, and extracting it feels like performing surgery on a beating heart.
The Escape Plan That Doesn’t Involve Burning It Down
The instinct is to rewrite everything. Event-source the aggregates! Drop Camunda! Consolidate to Kafka! Kill the shared libs! But this is the kind of system you don’t big-bang unless you have infinite time and zero revenue requirements.
A more viable path starts with accepting that 24 services talking to the same database might not need to be 24 services. If non-trivial changes always touch the same subset of services, those services are actually one bounded context. Merge them. Start by consolidating the services that always deploy together into a modular monolith communication trade-offs pattern, separate modules, single deployable unit. This immediately reduces your coordination surface area and makes your homegrown Python tool 50% less necessary.
Once you’ve consolidated the obvious candidates, you can begin true decoupling:
(Order, Payment, Inventory) where history matters, leaving CRUD entities as simple CRUD
with lightweight state machines in code plus saga orchestrators for cross-aggregate flows
for distributed tracing before you need it, not after
Route new order flows through new infrastructure while legacy processes drain
The key insight from teams who’ve survived this migration: don’t event-source for the sake of it. Not every aggregate needs an event log. Sometimes a simple state machine in the service that actually owns the data is sufficient, avoiding the complexity of optimizing orchestration workflows that span dozens of services.
The Real Lesson
The “orchestrator bus” anti-pattern emerges when teams treat microservices as primarily an infrastructure problem, containerize it, add Kubernetes, set up a workflow engine, and autonomy will follow. It doesn’t. Without deliberate domain boundaries, data ownership, and communication patterns, the underlying coupling survives the migration and hides inside your BPMN diagrams.
If your services can’t deploy independently, don’t share databases, and don’t require a Python script to coordinate releases, you might actually have microservices. If not, you’re running a distributed monolith with extra network hops. And no amount of BPMN XML will fix that.



