
The narrative of American AI supremacy didn’t just crack in 2025, it shattered. While US policymakers were busy tightening semiconductor export controls, Chinese labs were quietly engineering a revolution that would flip the open-source AI landscape on its head. The numbers don’t lie: Chinese models now account for 44.2% of downloads on Hugging Face, dwarfing the US share of 27.9%. Alibaba’s Qwen family alone has surpassed Meta’s Llama as the most downloaded LLM family. The irony? The very sanctions designed to slow China down became the crucible that forged their dominance.
The Efficiency Arms Race Nobody Saw Coming
When the US cut off access to Nvidia’s most advanced GPUs, the conventional wisdom was that Chinese AI development would stall. Instead, it triggered a discipline of optimization that Western labs, flush with compute, never had to develop. Chinese engineers perfected mixture-of-experts (MoE) architectures that do more with less, collapsing training costs from $100 million in the West to roughly $5.6 million for comparable performance.
This isn’t theoretical. In a recent AMA on r/LocalLLaMA, the Z.AI team behind GLM-4.7 revealed their most significant challenge wasn’t training, it was the “release recipe.” Different teams had their own SFT/RL approaches for different domains, and merging these capabilities without destroying others required surgical precision. Their solution? A LoRA-like approach in reinforcement learning that protects existing capabilities while targeting specific skill improvements. This kind of efficiency-driven innovation simply doesn’t emerge in compute-rich environments.

Qwen-Image-Edit-2511: The Multimodal Gauntlet
While US labs debate whether to release model weights, Qwen is shipping features that make Western offerings look stagnant. The jump from Qwen-Image-Edit-2509 to 2511 demonstrates the velocity of Chinese development:
- Multi-person consistency for group photos (a notoriously hard problem)
- Built-in community LoRAs eliminating the need for separate tuning
- Enhanced geometric reasoning for construction lines and technical drawings
- Industrial design applications that actually work in production pipelines
The model runs on consumer hardware with quantized versions down to 7.22GB, making it accessible to developers worldwide. Contrast this with OpenAI’s DALL-E 3, which remains API-only and costs $0.04-$0.12 per image. The economic implications are stark: Chinese labs are giving away what US companies charge premium rates for.
The Download Data Tells a Brutal Story
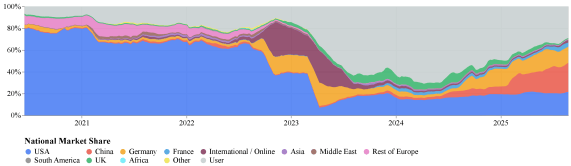
The “Economies of Open Intelligence” report reveals a stark reversal. In 2022, Google, Meta, and OpenAI controlled 60% of Hugging Face downloads. By 2025, that dominance evaporated:

China: 2.7 billion downloads (44.2%)
USA: 1.7 billion downloads (27.9%)
International/Online: 439 million (7.2%)
The stacked area chart shows the US losing ground since 2023 while China accelerated. This isn’t just hobbyists tinkering, 80% of open-source AI startups in VC portfolios now build on Chinese foundations. The Global South isn’t choosing Chinese models out of ideology, they’re choosing them because they can run them locally without API dependencies or export restrictions.
The Propaganda Problem Nobody Wants to Address
Here’s where the controversy gets spicy. A NewsGuard study found Chinese LLMs repeat or fail to correct pro-Chinese false claims 60% of the time. When you download Qwen or GLM, you’re not just getting weights, you’re inheriting training data that reflects a specific worldview. The Stanford HAI report notes this explicitly: “Since these models generate content based on their training data, they inevitably spread whatever narratives and values are baked in.”
The r/LocalLLaMA community has already seen developers building chatbots for customer service and content generation, unaware that their “neutral” AI assistant might be subtly promoting specific narratives. Unlike traditional propaganda that requires deliberate placement, these models are like sand that gets into everything, once integrated into a workflow, the embedded values seep into every output.
This isn’t hypothetical. Uganda’s Sunflower model and Malaysia’s Sharia-aligned NurAI demonstrate how nations are using Chinese foundations to build “Sovereign AI.” But the base models still carry their origin story.
Security Through Obscurity (Or Lack Thereof)
Chinese models aren’t just philosophically questionable, they’re technically vulnerable. CAISI, the US government’s AI testing center, found DeepSeek models are 12 times more susceptible to jailbreaking than comparable US models. The GLM-4.7 team admits they use permissive licenses (Apache 2.0) that allow broad modification, but this also means minimal safety guardrails.
The r/LocalLLaMA community discovered this firsthand when Grok’s “think mode” leaked its system prompt, showing how easily these models can be manipulated. Chinese developers are increasing permissiveness precisely because it accelerates adoption, but at what cost? When a financial institution in South Africa runs Qwen on domestic servers for “digital sovereignty”, they’re also inheriting these vulnerabilities.
The US Response: Panic and Backpedaling
Meta’s shift back toward closed-source models (while ironically still calling them “open-weight”) reveals the depth of the panic. Mark Zuckerberg’s presentation of Llama 4 was met with community disappointment, it fell short of expectations and couldn’t match the release cadence from Chinese labs. The “DeepSeek effect” forced Meta to open-source 5 repositories and scramble war rooms to catch up.
Nvidia, sensing the shift, announced a $3,000 personal AI supercomputer (Digits) to keep Western developers in the ecosystem. But the community reaction on r/LocalLLaMA was telling: users were more excited about buying modded 4090s with 48GB VRAM in Shenzhen for under $2,000. The hardware hack culture has shifted east.
What This Means for Practitioners
If you’re building AI applications in 2025, you face a stark choice:
- Use Chinese models: Get state-of-the-art performance, zero API costs, and full customization, but inherit potential propaganda vectors and security vulnerabilities
- Use US models: Get safety guardrails, brand recognition, and (theoretically) better governance, but pay premium API costs and face rate limits
- Self-train: Spend $100 million and hope you can compete with labs spending $5.6 million
The pragmatic developer is already choosing option one. The Qwen-Image-Edit-2511 pipeline code is copy-paste ready:
from diffusers import QwenImageEditPlusPipeline
import torch
from PIL import Image
pipeline = QwenImageEditPlusPipeline.from_pretrained(
"Qwen/Qwen-Image-Edit-2511",
torch_dtype=torch.bfloat16
)
pipeline.to('cuda')
# Multi-image editing with consistent characters
image1 = Image.open("person1.jpg")
image2 = Image.open("person2.jpg")
prompt = "Two colleagues discussing a blueprint in a modern office"
output = pipeline(
image=[image1, image2],
prompt=prompt,
num_inference_steps=40,
true_cfg_scale=4.0
)
This “it just works” accessibility explains why 63% of new fine-tuned models on Hugging Face are Chinese derivatives. The ecosystem effect is self-reinforcing: more models → more developers → more community LoRAs → better models.
The Uncomfortable Truth About “Openness”
Here’s the final twist: Chinese models aren’t truly open-source. Training data disclosure dropped from 80% in 2022 to 39% in 2025. What we’re getting is “open-weight” with permissive licenses (Apache 2.0, MIT), not reproducible science. The GLM-4.7 team admits their knowledge cutoff remains early 2024 while Kimi’s reaches 2025, suggesting data acquisition challenges despite technical prowess.
Yet this “good enough” openness is precisely what’s fueling global adoption. A university in Brazil doesn’t need the full training pipeline, they need downloadable weights that run on their hardware. A startup in Kenya doesn’t care about data provenance, they care about API-free deployment.
The US AI community faces an existential question: Did we optimize for the wrong metrics? While we pursued benchmark scores and safety certifications, China optimized for download counts and real-world deployment. Now they’re defining what “open-source AI” means for the next decade.
The Road Ahead
The Stanford HAI report concludes that Chinese models are “unavoidable in the global competitive AI landscape.” This isn’t a temporary shift, it’s a structural realignment. US export controls created a monster: a parallel AI ecosystem that’s more efficient, more accessible, and increasingly more capable.
The r/LocalLLaMA community’s 2025 recap said it best: “China is leading open source.” The question now isn’t whether Chinese labs will challenge US dominance, they already have. The question is whether US labs can adapt to a world where efficiency matters more than raw compute, and where “openness” is defined by who ships working code, not who publishes the most papers.
For practitioners, the takeaway is clear: test Qwen-Image-Edit-2511. Benchmark GLM-4.7. Understand the security tradeoffs. The future of AI development is being written in Beijing and Hangzhou, and the code is already on Hugging Face.



