
Google’s Titans: The Architecture That Makes Transformers Look Forgetful
Google just dropped a bombshell on the AI community, and it’s not another chatbot. The Titans architecture, unveiled in December 2025, represents a fundamental rethinking of how AI systems manage state, one that could make today’s most advanced language models look like they have short-term memory loss. While the attention mechanism in Transformers revolutionized AI by letting models weigh the importance of different tokens, Titans asks a more provocative question: what if we stop compressing everything into fixed-size memory and instead give AI a genuine learning system that updates itself in real-time?
The Memory Wall Nobody’s Talking About
The AI industry has been playing a shell game with context windows. GPT-4 handles 128K tokens. Claude stretches to 200K. The new Gemini models push even further. But here’s the dirty secret: longer context doesn’t mean better memory management. Transformers scale quadratically with sequence length, turning every additional token into a computational tax that eventually bankrupts your GPU cluster. The research community’s response, efficient linear RNNs and State Space Models like Mamba, offered linear scaling but hit a different wall: fixed-size state compression that can’t capture the rich information in long sequences.
The result? We’ve been stuck in a trade-off between expensive, exhaustive attention and cheap but forgetful linear models. Titans blows up this dichotomy by introducing a third path: a deep neural network that acts as a long-term memory module, learning how to learn as data streams in.
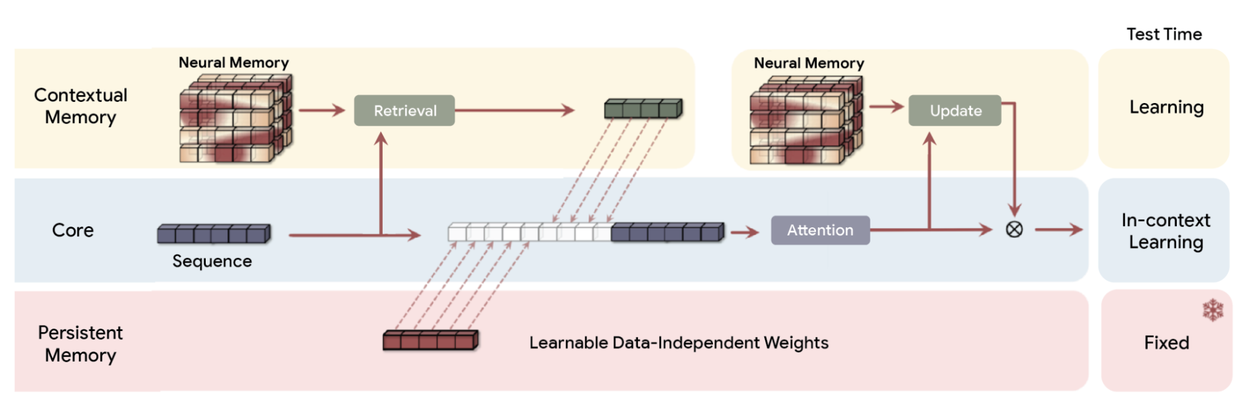
Three Memory Systems, One Coherent Architecture
Titans isn’t just another attention variant. It’s a memory architecture with three distinct modules that mirror how human cognition actually works:
- 1. Short-term memory (Attention): The familiar attention mechanism handles precise, in-context learning. This is your working memory, the stuff actively being processed.
- 2. Long-term memory (Neural Network): Here’s the radical part. Instead of a fixed-size vector or matrix like traditional RNNs, Titans uses a multi-layer perceptron as its memory module. This deep memory network provides exponentially higher expressive power, allowing the model to summarize vast amounts of information without the information bottleneck that plagues linear models.
- 3. Persistent memory (Fixed Weights): The standard pre-trained knowledge that doesn’t change during inference.
What makes this architecture genuinely different is how these components interact. The long-term memory module doesn’t just store data, it actively learns relationships and conceptual themes across the entire input history. When the model processes a 2-million-token document, it’s not just retrieving chunks of text, it’s building a compressed representation that preserves the conceptual structure of the whole.
The “Surprise Metric” That Makes AI Pay Attention
The most human-like innovation in Titans might be its surprise metric. In psychology, we remember surprising events better than routine ones, the unexpected stands out. Titans implements this mathematically through gradient-based surprise detection:
- Low surprise: If the model encounters information that aligns with its current memory state (e.g., another animal word when already summarizing about animals), the gradient signal is small, and the memory doesn’t waste capacity updating.
- High surprise: When something breaks the pattern, like a banana peel appearing in a serious financial report, the gradient spikes, forcing the memory module to prioritize this unexpected information.
This selective updating mechanism, combined with momentum (considering both current and recent surprise) and adaptive forgetting (weight decay), allows Titans to manage finite memory capacity intelligently. It’s not just compression, it’s curation.
MIRAS: The Theoretical Framework That Unifies Everything
If Titans is the tool, MIRAS is the blueprint that reveals why it works, and why everything else was secretly the same thing. The paper demonstrates that all major sequence modeling breakthroughs, from Transformers to linear RNNs, are fundamentally associative memory modules in disguise.
MIRAS defines a sequence model through four design choices:
- Memory architecture: What stores the information (vector, matrix, or deep network)
- Attentional bias: The internal learning objective that determines what to prioritize
- Retention gate: The “forgetting mechanism” reinterpreted as regularization that balances new learning against past knowledge retention
- Memory algorithm: The optimization method for updating memory
This framework reveals why previous models hit their limits. Standard approaches rely on mean squared error (MSE) or dot-product similarity for both bias and retention, making them sensitive to outliers and limiting expressive power. MIRAS transcends this by enabling non-Euclidean objectives and novel regularization strategies.
Using this framework, Google created three attention-free variants:
– YAAD: Uses Huber loss to be less sensitive to outliers (robust to typos or anomalies)
– MONETA: Employs generalized norms for more disciplined attention and forgetting rules
– MEMORA: Constrains memory to act like a strict probability map for maximum stability
The Performance: Numbers That Demand Attention
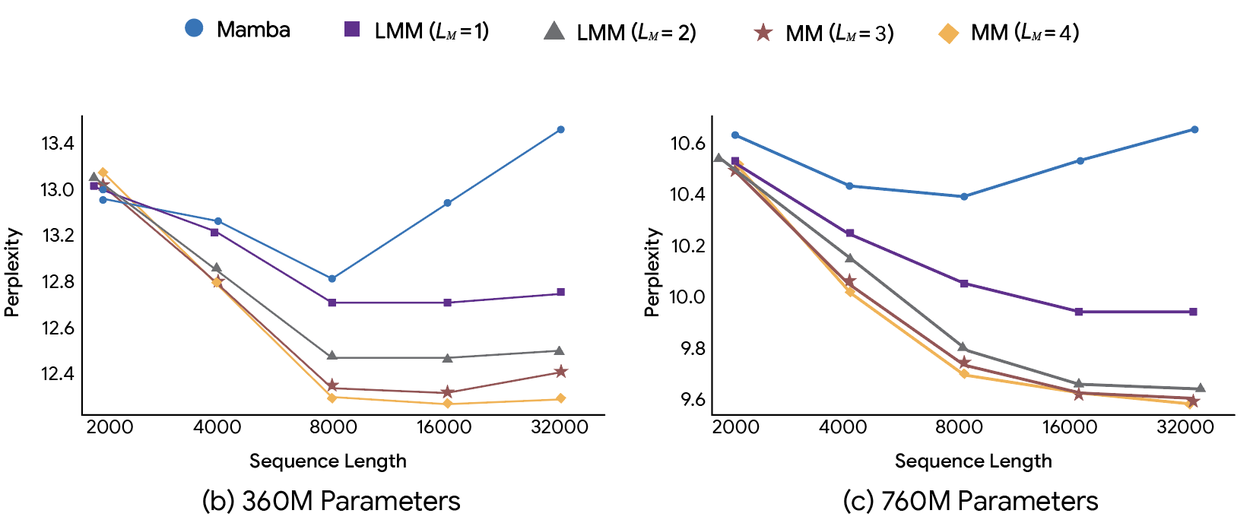
On standard language modeling tasks (C4 and WikiText), Titans maintains lower perplexity than Mamba-2 as sequence length scales, showing better efficiency and accuracy across both 360M and 760M parameter scales.
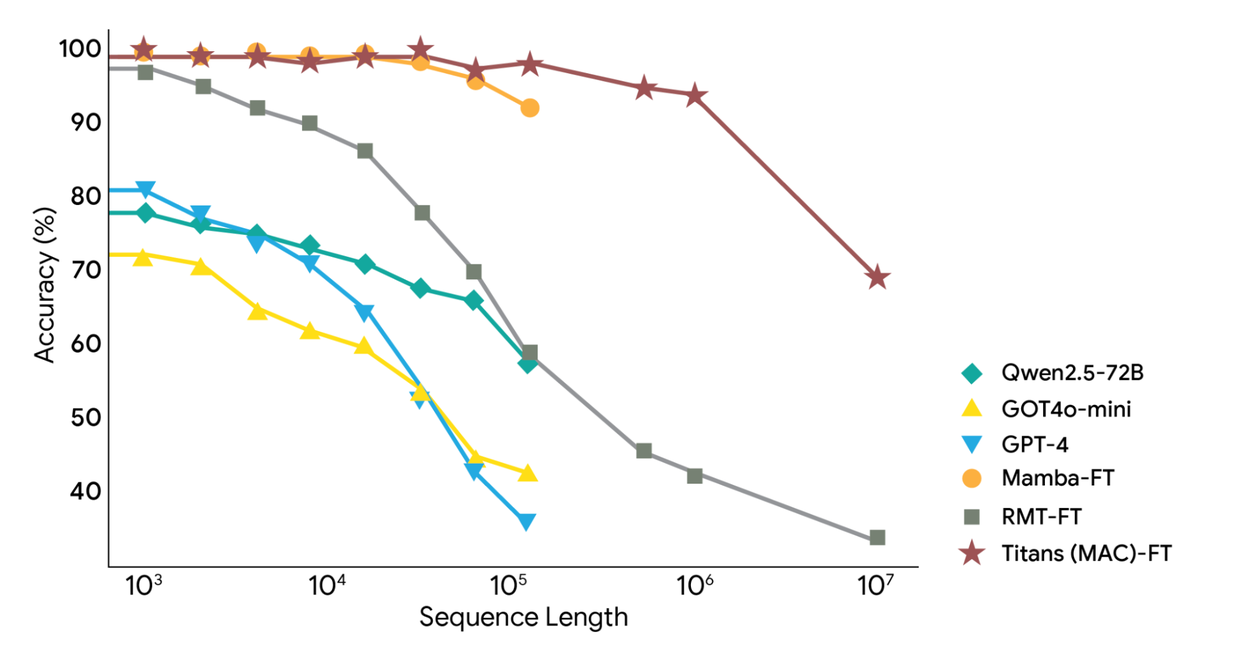
Titans outperforms GPT-4 on this task despite having significantly fewer parameters. While GPT-4’s accuracy degrades as sequences grow, Titans (MAC) maintains steady performance well beyond 2 million tokens. This isn’t incremental improvement, it’s a paradigm shift.
Why This Changes Everything for Agentic AI
The Titans announcement arrives as the AI industry grapples with a fundamental problem: state management in autonomous systems. Current AI agents suffer from catastrophic amnesia. They can’t maintain coherent memory across sessions, forcing developers to duct-tape solutions together with vector databases, session storage, and increasingly complex prompt engineering.
Amy Colyer’s analysis at AWS re:Invent 2025 highlighted exactly this pain point: “Agents need working memory to track progress toward goals, episodic memory to learn from past interactions, and planning capabilities to decompose complex objectives. This introduces state management challenges that simply don’t exist in stateless inference pipelines.”
Titans addresses this at the architectural level. Instead of bolting memory onto stateless models, it bakes memory into the core computation. This has profound implications:
- 1. Real-time adaptation: Traditional models learn during training and remain frozen during inference. Titans’ long-term memory updates continuously as new data arrives, enabling true test-time learning without retraining.
- 2. Memory as computation: In Titans, retrieving memory and computing the next token aren’t separate operations. The memory module is a differentiable neural network, so retrieval and generation happen in a unified computational graph.
- 3. Scalable personalization: Each user could have their own long-term memory module, fine-tuned on their interactions, without the prohibitive cost of full model fine-tuning. The 2B parameter size makes this feasible at scale.
The Platform Lock-In Problem Titans Doesn’t Solve, But Others Are Tackling
Here’s where the controversy starts. While Titans solves the technical problem of long-term memory, it potentially worsens another: platform lock-in. When your AI’s memory becomes deeply personalized through thousands of interactions, switching platforms becomes painful. Your agent knows your writing style, preferences, work patterns, abandoning it means starting from scratch.
This is the “memory trap” that Plurality Network identifies. As AI memory becomes more sophisticated, the switching cost increases, creating powerful moats for platform providers. The table of platform-specific memory features shows the fragmentation:
| Platform | Memory Features | Availability | Key Capabilities |
|---|---|---|---|
| ChatGPT | Dual System: “Saved Memories” + “Folders” | Free tier limited, full on Plus/Pro | References all past conversations, project-scoped memory |
| Claude | Project-scoped persistent memory | Sep 2025, Team/Enterprise plans | Isolated memory per project, import/export capability |
| Gemini | “Saved Info” with cross-chat recall | Advanced users only | Remembers preferences across conversations |
| Microsoft Copilot | Memory + Custom Instructions | Jul 2025, M365 plans | Learns working style across Microsoft apps |
Each platform locks your context inside its walled garden. Titans, as a Google technology, will likely integrate deeply with Gemini and Google Workspace, potentially making the ecosystem stickier than ever.
Yet solutions are emerging. Open-source memory layers like Memori and universal memory systems like AI Context Flow propose standardized memory storage that any agent can query. Imagine maintaining one portable memory that plugs into ChatGPT, Claude, Gemini, and Perplexity, using each for its strengths without losing continuity.
The Efficiency Revolution: From Cloud to Device
Perhaps the most disruptive aspect of Titans isn’t even the architecture itself, it’s the performance characteristics that enable on-device deployment. The companion MemLoRA research shows how small language models (1.5B-2B parameters) with specialized adapters can match or exceed 27B parameter models on memory tasks.
The efficiency gains are staggering:
– 10-20× smaller memory footprint (2.9GB vs 50GB+)
– 10-20× faster inference (0.64 seconds vs 10+ seconds per response)
– Comparable performance to models 10-60× larger on long-context benchmarks
This isn’t just academic. On-device memory systems mean:
– Privacy: Your personal memory stays on your phone, not in Google’s datacenter
– Offline operation: AI agents that remember you without internet connectivity
– Cost reduction: No API calls for memory operations, making personalized AI economically viable
The MemLoRA paper demonstrates that small vision-language models with specialized adapters can reach 81.3% accuracy on visual question answering tasks, outperforming much larger models. This suggests Titans could run efficiently on edge devices, not just in Google-scale datacenters.
Unanswered Questions and Controversial Takes
Before we crown Titans the winner, let’s acknowledge the elephants in the room:
- 1. Training dynamics: The paper shows impressive results, but the training recipes remain opaque. How stable is the joint optimization of attention and deep memory modules? What happens when memory modules get corrupted?
- 2. Interpretability: Titans’ memory is a black-box neural network. Unlike attention weights that reveal what the model focuses on, the deep memory module’s decisions are opaque. For high-stakes applications (finance, healthcare), this could be a dealbreaker.
- 3. Computational overhead at training: While inference is efficient, training a 2B parameter memory module alongside a large language model likely requires computational resources that only Google-scale organizations can afford. Open-source replication may be challenging.
- 4. The forgetting problem: Adaptive weight decay helps manage memory capacity, but what guarantees do we have that critical information won’t be silently erased? The “surprise metric” is a heuristic, not a principled retention guarantee.
- 5. Ecosystem fragmentation: Titans reinforces the trend toward vertically integrated AI stacks (hardware, model, memory, application). While open-source alternatives exist, the gap between research papers and production-ready implementations is widening.
The Verdict: A Genuine Inflection Point
Google’s Titans isn’t just another incremental improvement, it’s a fundamental reimagining of how AI systems should handle long-term dependencies. By rejecting the false choice between attention and recurrence, it opens a third path: memory as a learned, dynamic, deep system that updates itself in real-time.
The performance numbers are impossible to ignore. Outperforming GPT-4 on 2M+ token benchmarks with fewer parameters is the kind of result that makes researchers question their assumptions. The MIRAS framework provides the theoretical foundation that legitimizes this approach, showing how all sequence models are secretly associative memories with different constraints.
For developers building agentic systems, Titans offers a glimpse of a future where state management isn’t a bolt-on headache but a core architectural feature. Whether Google will open-source the full system or keep it locked in Gemini remains to be seen. But the ideas are out, and the community is already running with them.
The real controversy isn’t whether Titans works, it clearly does. It’s whether the industry will embrace this new memory paradigm or retreat into comfortable familiarity with Transformers. History suggests the better architecture wins, but incumbency has power.
As you evaluate AI platforms for your next project, ask vendors: “How are you addressing long-term memory beyond context windows?” If they can’t answer, they might be selling you yesterday’s architecture tomorrow.
The memory wall is here. Titans just gave us a wrecking ball.
What do you think? Is Titans the future of AI architecture, or will Transformers maintain their dominance through ecosystem lock-in? Join the discussion below.



