
Z.ai just dropped a text-to-speech model that clones voices from a 3-second audio clip and manipulates emotion through reinforcement learning. On paper, GLM-TTS beats commercial systems on character error rate while staying completely open-source. In practice, it refuses to say “I’m” and sometimes gets stuck in an infinite loop of “so much love you all.” Welcome to the bleeding edge of voice AI, where groundbreaking performance ships with debug logs still warm.
What Makes GLM-TTS Different
Most voice synthesis models treat emotion like a preset filter, apply “happy” or “sad” and hope for the best. GLM-TTS takes a different approach: it uses a Group Relative Policy Optimization (GRPO) framework to chase multiple reward signals simultaneously. The model doesn’t just generate speech, it learns to optimize for similarity, character accuracy, emotional expressiveness, and even the naturalness of laughter.
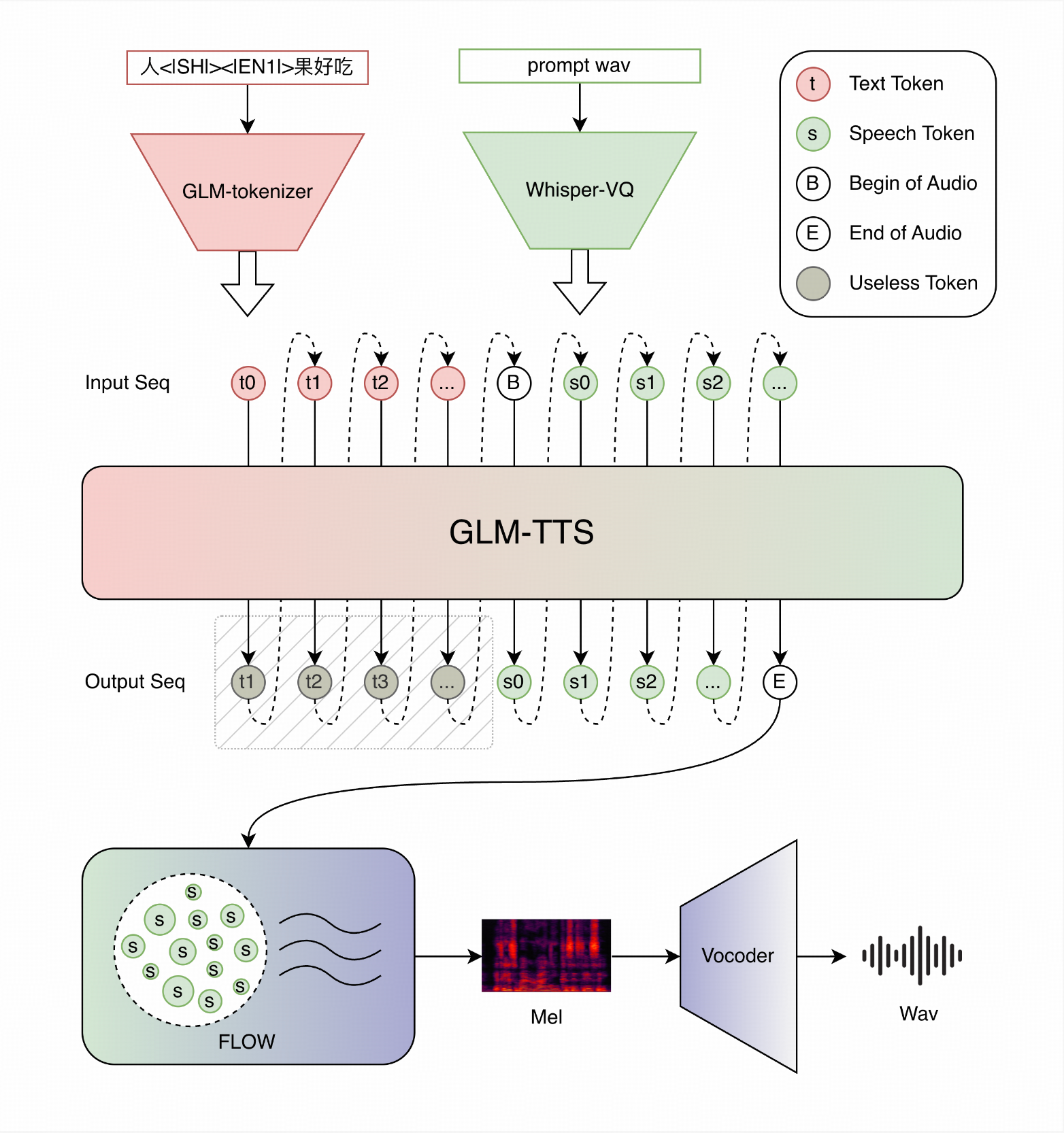
The architecture reflects this ambition. Stage one deploys a Llama-based language model that converts input text into discrete speech token sequences, essentially treating speech generation as a language task. Stage two uses a Flow Matching model to transform those tokens into mel-spectrograms, then through a vocoder to raw waveforms. This two-stage design enables the streaming capability: tokens flow out one by one, and audio follows milliseconds behind.
The Numbers That Matter
The evaluation metrics tell a compelling story. When tested on the seed-tts-eval benchmark, GLM-TTS_RL achieved a 0.89% Character Error Rate (CER), the lowest among open-source models and competitive with closed systems like Seed-TTS (1.12% CER). Speaker similarity (SIM) hit 76.4%, slightly behind Seed-TTS’s 79.6% but ahead of other open alternatives like CosyVoice2 and F5-TTS.
Here’s the comparison that should make commercial vendors nervous:
| Model | CER ↓ | SIM ↑ | Open-source |
|---|---|---|---|
| Seed-TTS | 1.12 | 79.6 | 🔒 No |
| CosyVoice2 | 1.38 | 75.7 | 👐 Yes |
| F5-TTS | 1.53 | 76.0 | 👐 Yes |
| GLM-TTS (Base) | 1.03 | 76.1 | 👐 Yes |
| GLM-TTS_RL (Ours) | 0.89 | 76.4 | 👐 Yes |
The RL-tuned version cuts errors by 14% compared to the base model, proving the multi-reward approach isn’t just academic flexing, it delivers measurable gains.
The Good: Zero-Shot Cloning That Actually Works
The “3-10 seconds” claim isn’t marketing. The model generates speaker embeddings from short audio clips and applies them to novel text without fine-tuning. For developers building voice agents or localization tools, this eliminates the data collection nightmare that traditionally made custom voices a six-figure project.
Bilingual support means seamless code-switching between Chinese and English within the same utterance. The phoneme-level control allows feeding raw phonetic transcripts to fix polyphone ambiguities, think “read” (present) vs. “read” (past), giving precise control where other models guess.
Streaming inference makes this viable for real-time applications. Interactive voice agents, live dubbing, or even gaming NPCs can generate speech on-the-fly without batch processing delays. The LLM-based token generation naturally supports this: it streams tokens as they’re sampled, and the Flow Matching decoder keeps pace.
The Bad: Shipping While the Paint’s Still Wet
A YouTube installation video reveals the gap between research release and production readiness. The narrator documents how the model loads with “a lot of warnings and errors”, attempts GPU offloading, fails, and falls back to CPU. It works, consuming under 10GB VRAM, but throws enough debug noise to spook engineers used to polished APIs.
More concerning: the contraction bug. As one Reddit user discovered, “every time I used a contraction, the generated audio made it not a contraction.” “I’m” becomes “I am”, “don’t” becomes “do not.” The model’s tokenizer appears to split contractions at inference, creating a Mr. Data effect that breaks naturalism. For casual dialogue applications, this isn’t a minor quirk, it’s a dealbreaker.
Voice cloning length also hits a wall. The video shows a 5-second reference clip generating only 2 seconds of output, looping the phrase “so much love you all” regardless of input text. The narrator suspects “some issue with their code”, but the pattern suggests either a latent space collapse or overfitting in the speaker embedding module.
The Ugly: Emotion Control as a Double-Edged Sword
The multi-reward RL framework optimizes for emotional expressiveness, but the paper avoids discussing thresholds. If a model learns to generate convincing distress, anger, or sorrow from a neutral text prompt, who bears responsibility for misuse? The 3-second cloning requirement lowers the barrier for creating synthetic voices of public figures, potential fraud victims, or non-consenting individuals.
This isn’t theoretical. The same architecture that makes voice agents sound more empathetic can fabricate emotional manipulation at scale. The reward functions don’t include an “ethical use” score, the RL agent chases whatever metrics it’s given, and current metrics care about perceived authenticity, not moral boundaries.
Running It Yourself
Despite the rough edges, GLM-TTS is accessible. Installation follows standard open-source patterns:
git clone https://github.com/zai-org/GLM-TTS.git
cd GLM-TTS
pip install -r requirements.txt
For basic inference, you can use their Python script with example data:
python glmtts_inference.py \
--data=example_zh \
--exp_name=_test \
--use_cache
Add --phoneme for phoneme-level control. The model expects checkpoint files in a ckpt/ directory, download them via Hugging Face’s CLI:
huggingface-cli download zai-org/GLM-TTS --local-dir ./ckpt
VRAM requirements stay modest, under 10GB even for the full pipeline, making it runnable on consumer GPUs like the RTX 3060 or 4060.
The Bigger Picture
GLM-TTS represents a shift in voice AI architecture: treat speech as language, apply LLM scaling laws, then refine with RL. This mirrors how ChatGPT learned writing styles from human feedback. The difference is that voice synthesis operates in continuous acoustic spaces, making reward engineering harder but the payoff potentially larger.
The contraction bug and cloning length issues will likely get patched in 4.6 or 5.0 releases, as developers on Reddit anticipate. But the core contribution, GRPO-based emotion control, establishes a new baseline. Future models will need to match not just CER and SIM, but also the naturalness of laughter and prosodic variation.
For developers, this means evaluating trade-offs: GLM-TTS delivers superior accuracy and emotional range but requires tolerance for early-release instability. Commercial systems like Seed-TTS offer polish and slightly better voice similarity, but at the cost of vendor lock-in and pricing that scales with usage.
Final Takeaway
GLM-TTS proves that open-source voice synthesis has caught up to, and in some ways surpassed, proprietary alternatives. The 3-second cloning and RL emotion control are genuine innovations, not incremental tweaks. But the model ships with enough sharp edges to cut users who expect plug-and-play reliability.
If you’re building voice features where accuracy and expressiveness trump polish, GLM-TTS is worth the setup friction. If you need bulletproof contractions or guaranteed cloning stability, wait for 4.6. And if you’re thinking about the ethical implications? Start that conversation now, before the technology gets smoother and the barrier to misuse drops even lower.



