
The FP8 Revolution: How Unsloth Just Democratized Reinforcement Learning
Reinforcement learning has long been the exclusive domain of GPU-rich clouds and research labs, until now. The Unsloth and PyTorch TorchAO collaboration has shattered the memory barrier, bringing FP8 reinforcement learning to consumer hardware like RTX 40-series cards with as little as 5GB VRAM.
This isn’t just incremental improvement, it’s a fundamental shift in what’s possible on local hardware. The implications are profound: suddenly, researchers, hobbyists, and startups can experiment with sophisticated RL techniques without committing to thousand-dollar cloud bills. The democratization wave that hit fine-tuning is now crashing over reinforcement learning.
Why FP8 Changes Everything for Reinforcement Learning
FP8, the 8-bit floating point format, represents more than just another quantization scheme. It’s the first precision format specifically designed for AI workloads that can handle both training and inference without significant accuracy degradation. NVIDIA’s research established that FP8 training can match BF16 accuracy while achieving 1.6x higher throughput on H100 systems.
But the real game-changer isn’t the performance on server-class hardware, it’s bringing this capability to everyday machines. The Unsloth team, collaborating with PyTorch’s TorchAO, achieved what many considered impossible: making FP8 RL work on consumer GPUs with minimal VRAM requirements.
Consider the numbers: Qwen3-4B FP8 GRPO now runs on just 6GB VRAM, while Qwen3-1.7B fits in 5GB. This represents a staggering 60% reduction in memory usage compared to traditional approaches, enabling workloads that previously required enterprise hardware to run on laptops and desktop gaming cards.
The Memory Gap: From Data Centers to Desktops
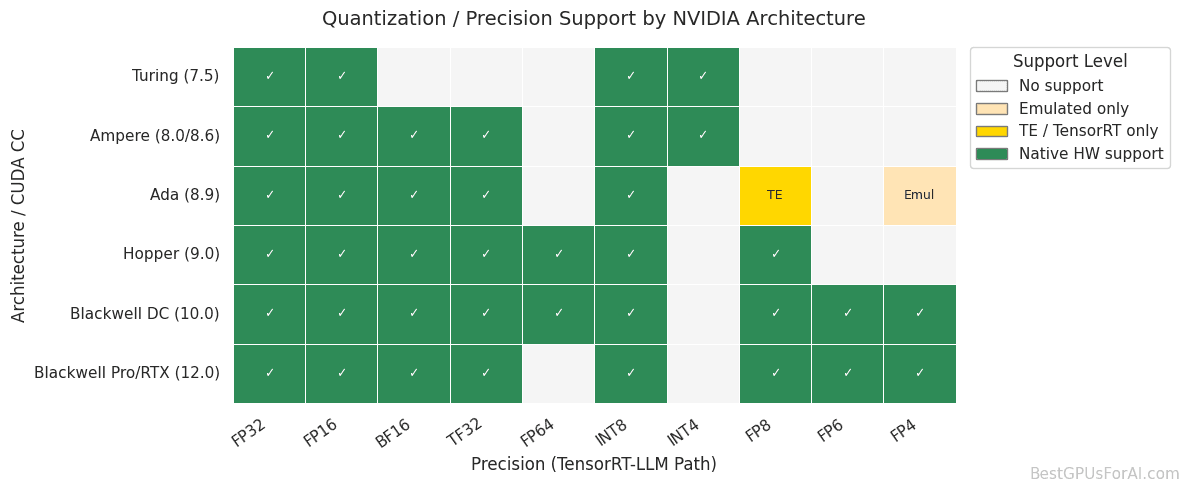
The breakthrough becomes even more significant when you understand the hardware landscape. Consumer GPUs traditionally lacked the specialized capabilities for advanced training workloads. While datasets showed that older architectures like Turing only support FP16, INT8, and INT4, the Ada Lovelace generation introduced FP8 support that enabled this breakthrough.
What makes this particularly interesting is that Unsloth’s implementation works across the RTX 40-series through RTX 50-series, as well as data center cards like H100 and B200. This bridges the gap between consumer and professional hardware in ways we haven’t seen before.
The implications are practical and immediate: you no longer need expensive cloud instances to experiment with reinforcement learning. Your RTX 4060 with 8GB VRAM, previously considered insufficient for serious RL work, can now handle meaningful training runs.
How Unsloth Cracked the FP8 Code
The technical approach behind this breakthrough reveals why previous attempts fell short. Unsloth’s implementation cleverly addresses the core bottleneck in RL training: inference overhead.
In traditional reinforcement learning workflows, 96% of the training time is spent on inference, generating candidate solutions that get scored and rewarded. Unsloth’s architecture makes training take just <4% of the RL run, with the vast majority being pure vLLM inference.
The technical pipeline looks like this:
– Frozen LoRA weights stored in FP8
– Dynamic FP8 quantization applied to input activations
– Trainable LoRA adapters kept in BF16 for gradient accuracy
– Shared memory buffers between vLLM and training weights
– Backward pass dequantization to preserve numerical stability
This isn’t just theoretical. The team tested multiple models including Qwen3-4B, 8B, 14B, Llama 3.2 1B, 3B, and Qwen3-VL variants. Across all tests, the loss curves during SFT for BF16 and FP8 closely tracked each other, with no meaningful accuracy degradation.
Performance That Speaks Volumes
The benchmarks tell a compelling story. Unsloth reports 1.4x faster RL training and 2× longer context versus BF16/FP16 implementations. Even more impressively, their approach uses 60% less VRAM and enables 10× longer context than other FP8 RL implementations.
Memory savings scale with model size:
– ~30 GB saved for Qwen3-32B
– ~14 GB saved for Qwen2.5-14B
– ~8 GB saved for Qwen3-8B
These aren’t marginal improvements, they’re transformative. A Qwen3-32B model that previously hit memory limits at higher batch sizes now trains without OOM errors on the same hardware configuration.
The throughput improvements are equally dramatic. Testing different FP8 quantization approaches revealed:
| Type | Throughput | MMLU Pro | GQPA Diamond |
|---|---|---|---|
| Bfloat16 Baseline | 11,367 | 62.04% | 28.79% |
| Block-wise | 12,041 | 62.37% | 29.29% |
| Per-Channel | 12,963 | 61.89% | 31.82% |
| Per-Tensor | 13,681 | 61.83% | 27.78% |
The takeaway? Block-wise and per-channel FP8 quantization deliver the best balance of performance and accuracy, with per-tensor approaches sacrificing too much quality for speed.
Getting Started: From Impossible to One Line
The implementation simplicity is perhaps the most surprising aspect. Enabling FP8 reinforcement learning requires adding just one parameter:
import os
os.environ['UNSLOTH_VLLM_STANDBY'] = "1" # Saves 30% VRAM
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Qwen3-8B",
max_seq_length = 2048,
load_in_4bit = False,
fast_inference = True,
max_lora_rank = 32,
load_in_fp8 = True, # Float8 RL / GRPO!
)The framework handles the complexity automatically. If a pre-quantized FP8 model isn’t available, Unsloth performs on-the-fly conversion using TorchAO’s dynamic quantization. The team has uploaded FP8 versions of most popular models to Hugging Face, including Llama 3.1, Qwen3, Gemma 3, and Mistral variants.
The Hardware Reality Check

There’s one important caveat: not all consumer hardware supports FP8 equally. The NVIDIA architectures that properly support FP8 start with Ada Lovelace (RTX 40-series) and continue through Blackwell. Older RTX 30-series cards using Ampere architecture, while powerful, don’t have native FP8 Tensor Core support.
This creates an interesting hardware stratification. Budget options under $1000 like the RTX 4060 Ti suddenly become viable RL training platforms, while older but more powerful cards like the RTX 3090 miss out on the efficiency benefits.
The memory efficiency gains also solve a critical problem for free tiers like Google Colab. Since Tesla T4 GPUs don’t support FP8, Unsloth’s notebooks use 24GB L4 GPUs instead, which can handle even Qwen3-14B models, something previously impossible on free-tier hardware.
Beyond Reinforcement Learning: The Broader Implications
What makes this development particularly exciting is how it fits into the broader efficiency revolution happening across AI. NVIDIA’s recent FLUX.2 optimization demonstrates similar FP8 benefits for image generation, reducing VRAM requirements by 40% while maintaining quality.
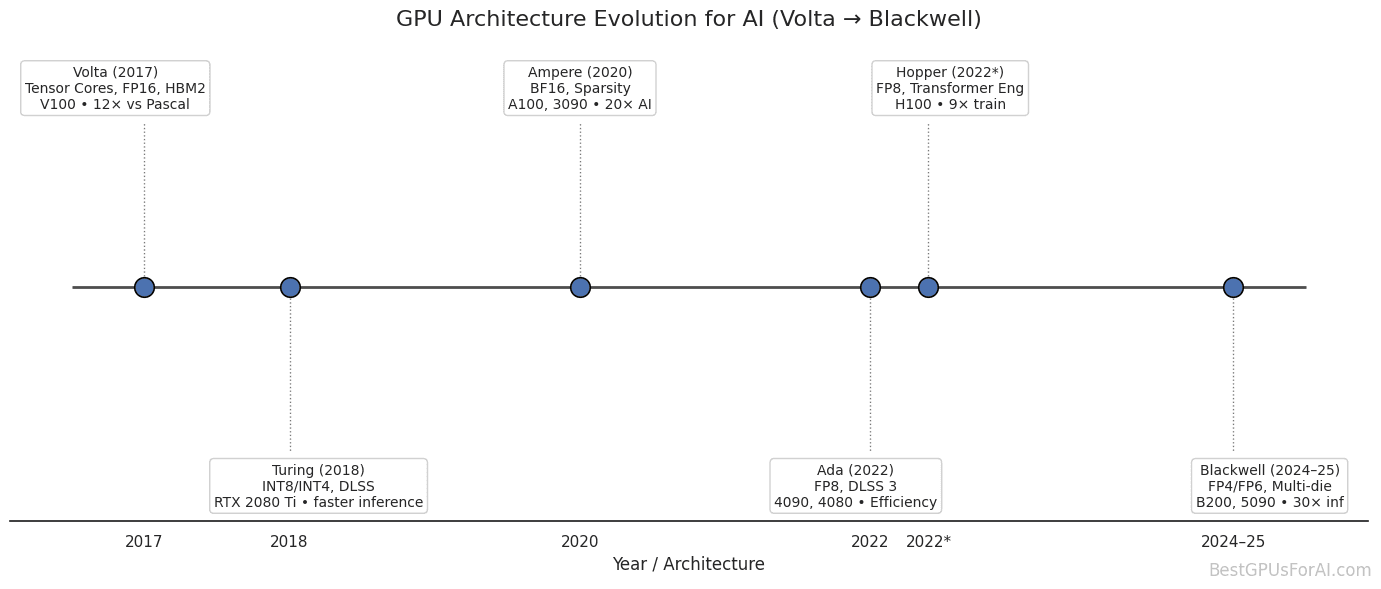
The trend is clear: 8-bit precision is becoming the new standard for efficient AI training and inference. As the GPU architecture evolution shows, each generation brings better support for lower precision formats, with Blackwell even introducing FP4 for even more extreme compression.
The Competitive Landscape Shift
This breakthrough fundamentally changes who can participate in advanced AI development. Previously, reinforcement learning required either expensive cloud credits or significant hardware investment. Now, developers can experiment with:
- Training reasoning agents on local hardware
- Fine-tuning models for specific reasoning tasks
- Creating specialized assistants with reinforcement learning from human feedback
- Building custom RL environments without budget approval
The performance delta between consumer and professional hardware narrows significantly. While data center GPUs still offer advantages for large-scale production, the barrier to entry for research and prototyping has collapsed.
Getting Started Today
The practical implementation is remarkably accessible. Unsloth provides comprehensive Colab notebooks for both Qwen3-8B FP8 GRPO and Llama-3.2-1B FP8 RL. Installation is straightforward:
pip install --upgrade --force-reinstall --no-cache-dir --no-deps unsloth unsloth_zooFor developers with RTX 40-series or newer hardware, the experiment-to-production pipeline just got dramatically shorter. You can prototype on local machines, then scale to cloud instances for larger runs, all using the same codebase and techniques.
The Future is Lower Precision
The FP8 revolution in reinforcement learning represents more than just a technical optimization, it’s a fundamental shift in accessibility. When developers report that “an RL-finetuned 4B Qwen could actually be useful for real tasks” and that doing this on “lowly laptop GPU would be amazing”, you know something significant has changed.
As lower precision formats continue to mature, with FP6 and even FP4 on the horizon, the democratization of advanced AI training will only accelerate. The era where only well-funded organizations could experiment with reinforcement learning is ending, and the implications for innovation are staggering.
The tools are here, the performance is proven, and the barrier to entry has never been lower. The question isn’t whether you should try FP8 reinforcement learning, it’s what you’ll build now that it’s finally within reach.



