You’ve got a 40TB PostgreSQL instance humming along, handling 500 billion rows of IoT telemetry data. Queries are fast. The infra team is nervous. The CTO is eyeing the budget. And somewhere in the back of your mind, you know this beautiful, well-oiled machine is one hardware failure away from a very bad week.
This is the story of every architect who has fallen in love with PostgreSQL’s reliability, only to realize that time-series data is a different beast entirely.
The Setup That Works (For Now)
Let’s paint the picture. Your current on-prem PostgreSQL v14 setup is no joke:
- Logical size: 40 TB (15 TB physical thanks to Btrfs compression)
- Rows: ~500 billion
- Partitioning: By business day
- Compression: ~5x with Btrfs
- Row size: ~90 bytes per record (device ID, timestamps, value, five more columns)
- Query pattern: Point lookups by device ID + date range (4, 5 days)
- Peak throughput: 1M+ queries per hour, sub-100ms response required
Each row is a simple IoT event. Device identifier, insert timestamp, business timestamp, a value, and a few metadata columns. Append-only. Backfills happen. Updates are basically non-existent.
On paper, this should be fine. Your queries are tightly controlled through a REST API that forces partition key usage. The data is well-indexed on id and business_timestamp. The access pattern is predictable: “Give me all records for device X between dates Y and Z.”
And it is working. The database returns data in under 100ms with 25 parallel queries during peak hours. That’s genuinely impressive for a 40TB relational database.
But here’s the problem: the infrastructure team wants to cut RAM from 256GB to 128GB. Data volume is growing 1.5x every couple of years. Query rates are doubling. And nobody on the team has deep PostgreSQL internals expertise.
One architect captured the anxiety perfectly: the question isn’t “can it run?”, it’s “what happens when this monster goes down?”
The “Why Fix What Isn’t Broken?” Argument
The most provocative take in the Reddit thread came from a commenter who basically said: don’t change anything.
“Your performance should remain rather constant so long as your query patterns remain similar. Size of data at rest is irrelevant when everything is architected well.”
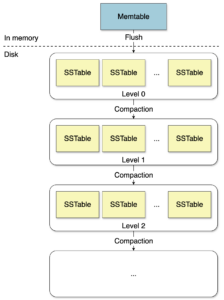
This isn’t lazy advice. It’s based on a real understanding of how PostgreSQL handles partitioned append-only workloads. Each partition is stored in 1GB chunks. The query planner prunes effectively when the partition key is used. Old partitions sit cold on disk, never consuming cache. The hot partitions, the last few days, fit comfortably in 256GB RAM.
The failure modes are specific and manageable:
- Queries without partition keys, especially dangerous when partitions exceed 1000
- Cache eviction, something pushes hot data out of shared buffers
- Analytics queries, the silent killer that changes query patterns overnight
But the advice comes with a critical caveat: “Can you take downtime for an upgrade?” Because doing a logical replication sync for a 40TB database to perform a near-zero-downtime upgrade would take approximately three weeks for initial sync.
That’s not a hypothetical. That’s a hard operational constraint that defines your ceiling.
The Real Problem: Operational Anxiety Masquerading as Performance
Here’s the uncomfortable truth the performance metrics won’t show you: the real problem isn’t query latency. It’s operational risk.
PostgreSQL admin guidelines consistently recommend thinking about sharding once you cross the 2TB to 8TB range. Why? Because backups, maintenance, and disaster recovery become unwieldy. The database runs fine today, but the blast radius of a failure grows with every terabyte.
Consider the specific risks:
- RTO (Recovery Time Objective): Restoring 40TB from backup isn’t measured in minutes. It’s measured in hours at best, days at worst.
- Upgrade cycles: In-place major version upgrades require downtime. Logical replication for zero-downtime upgrades takes weeks for initial sync.
- Hardware failure: If a disk controller dies, you’re not recovering a 40TB instance quickly.
- Expertise dependency: You need someone who understands PostgreSQL internals deeply. That person is expensive and may not always be available.
This is why the “it works fine” argument feels hollow to anyone who has been woken up at 3 AM by a production database.
Sharding PostgreSQL: Trading One Complexity for Another
The original post’s preferred option was a custom sharding solution: partition by hash of the device ID. Spread data across multiple PostgreSQL instances. Each shard handles a subset of devices.
The pros are obvious:
– Linear scalability for both reads and writes
– Better RPO/RTO since each shard is smaller
– You stay on known technology
– Rolling upgrades become possible
But the cons are brutal:
– You’re building a distributed database management system from scratch
– Cross-shard queries become painful (though your query pattern avoids this)
– Schema changes require coordinated multi-shard migrations
– Query routing, connection management, and rebalancing all need custom code
One commenter hit the nail on the head: “hash by device identifier is essentially treating each device as a separate tenant in a multi-tenant implementation.” If you squint, this looks like microservices for your database. And we all know how that story goes.
What About Citus?
Citus (now part of Citus Data, recently acquired by Microsoft) is the obvious middle ground. It gives you distributed PostgreSQL without building your own sharding layer. But the community opinions are mixed. Some teams love it, others find the operational complexity and query limitations frustrating.
The key question is whether Citus handles your specific workload better than raw PostgreSQL plus application-level sharding. For append-heavy time-series data with well-defined partition keys, the overhead of Citus’s distributed query planning might not justify the benefits.
TimescaleDB: The Logical Step That Doesn’t Go Far Enough
TimescaleDB is designed explicitly for time-series workloads on PostgreSQL. It gives you automatic partitioning (hypertables), compression, and data retention policies. The original poster tested TimescaleDB compression and achieved 6x, solid, but not game-changing.
The problem is fundamental: TimescaleDB doesn’t solve the sharding problem. It still runs on a single PostgreSQL instance. Compression helps with storage, but backups and recovery remain at the instance level. If your concern is operational blast radius, TimescaleDB doesn’t shrink it.
This is the awkward middle ground. TimescaleDB makes sense for time-series workloads up to a certain scale. But 40TB with 1M+ queries per hour pushes past that threshold for most teams.
ClickHouse: The OLAP Elephant in the Room
This is where things get spicy. ClickHouse is a columnar OLAP database designed for analytical queries at extreme scale. The original poster achieved 16x compression with ClickHouse, dramatically better than PostgreSQL’s 5x or TimescaleDB’s 6x.
The compression advantage means that 40TB logical data becomes approximately 2.5TB physical in ClickHouse. That changes the operational calculus completely. Backups are faster. Recovery is faster. You might even fit hot data entirely in memory.
But there’s a catch: ClickHouse is optimized for analytical queries (aggregations, group-by, large scans), not point lookups. The original poster’s workload is essentially key-value lookups: “get all rows for this device ID over 4-5 days.” That’s not a typical ClickHouse strength.
Or is it? ClickHouse supports primary key-based lookups with its MergeTree engine. With proper ordering (by device ID, then timestamp), point queries can be extremely fast. The database uses sparse indexes to skip entire data blocks that don’t match the query predicate. If you order by (device_id, business_timestamp), a lookup for a specific device scans only the relevant blocks.
The 100ms Challenge
The original poster requires “less than 100ms response time with 25 parallel queries.” That’s the kind of SLA that gives architects nightmares. Can ClickHouse deliver?
The answer depends entirely on your ordering key and data distribution. If each device writes a few thousand rows per day, and you’re querying 4-5 days, that’s maybe 20,000 rows per query. ClickHouse can scan and return that many rows in under 100ms easily, even from disk. The concern would be if queries start scanning large portions of the table because of poor ordering or missing partition pruning.
A Reddit commenter who works with ClickHouse directly pushed back on the concern:
“ClickHouse was built for low latency. Your rigid query pattern lends itself well to ordering, which is what keeps ClickHouse fast.”
They also mentioned pg_clickhouse, a PostgreSQL extension that pushes queries down to ClickHouse. That’s an interesting compromise: keep PostgreSQL for operational queries and use ClickHouse as a specialized time-series engine behind the scenes.
The Migration Math
Let’s look at the raw numbers:
| Metric | PostgreSQL (current) | ClickHouse (estimated) |
|---|---|---|
| Physical storage | 15 TB (with Btrfs) | ~2.5 TB |
| Query pattern suitability | Excellent (point lookups) | Good (with proper ordering) |
| Operational complexity | Moderate (large instance) | High (new system) |
| Native sharding | No (needs extension/custom) | Yes (distributed tables) |
| Compression ratio | ~5x | ~16x |
| Point query latency | <100ms | <100ms (with correct schema) |
| Analytics queries | Painful | Trivially fast |
The math gets interesting when you consider the infrastructure footprint. A ClickHouse cluster with 2.5TB physical storage is dramatically cheaper to operate than a 15TB PostgreSQL instance, even before considering the cost of redundancy.
The Hybrid Architecture Play
The most pragmatic approach isn’t “migrate everything to ClickHouse” or “stay with PostgreSQL forever.” It’s a hybrid architecture that uses each database for what it does best.
The pattern is straightforward:
- PostgreSQL handles the operational layer, authentication, metadata, configuration, and any workloads that need ACID transactions
- ClickHouse handles the hot time-series data, last 30 days, with native sharding for scale
- Cold data goes to object storage, S3-compatible storage with Parquet files, partitioned by device ID and date
This approach gives you three operational advantages:
Reduced blast radius. PostgreSQL drops from 40TB to something manageable. ClickHouse shards are small. Cold data is just files.
Faster recovery. If ClickHouse goes down, you can rebuild a shard from the last 30 days of raw data. If PostgreSQL goes down, you recover a much smaller database.
Cost optimization. Hot data lives on fast SSDs. Cold data lives in cheap object storage. You pay for performance where it matters.
One commenter suggested a simpler version: keep hot data in PostgreSQL for the last 30 days, move old data to S3 buckets keyed by deviceId/yyyymmdd. When a query comes in for historical data, fetch 4-5 files, decompress, merge, and return. But another commenter rightly pointed out that this breaks the 100ms SLA, the TCP handshake alone eats a significant chunk of your budget.
The Decision Framework
After parsing through the debate, here’s what the decision really comes down to:
Stay with PostgreSQL if:
– Your query patterns remain stable and partition-key-bound
– You can maintain 256GB+ RAM (don’t let infra push you to 128GB)
– Your RTO requirements are generous enough for 40TB recovery
– You have or can hire PostgreSQL expertise
– You’re willing to accept downtime for major upgrades
Shard PostgreSQL if:
– You need to reduce blast radius but can’t justify a new database platform
– Your team knows PostgreSQL and doesn’t want to learn something new
– You’re okay with building custom sharding infrastructure
– Your query pattern cleanly partitions by device ID
Migrate to ClickHouse if:
– Storage costs are a primary concern (16x compression is real)
– You want native sharding and distributed query execution
– Your current query pattern can be mapped to ClickHouse ordering keys
– You’re willing to invest in learning a new database system
– Future analytics queries are on the roadmap
Go hybrid if:
– You need the best of both worlds
– Your team can manage operational complexity
– You have clear boundaries between operational and analytical workloads
– The cost of running two systems is justified by performance gains
The 18-Month Planning Horizon
Here’s the advice nobody wants to hear: start planning now, even if everything is fine.
Time-series data grows. Query patterns evolve. Teams change. The PostgreSQL instance that works today will choke eventually, not because PostgreSQL is bad, but because you’re pushing it into territory where specialized systems live.
The most dangerous assumption is that current query patterns will remain stable. The biggest threat to your 40TB PostgreSQL instance isn’t a SQL injection or a disk failure. It’s the day someone runs an analytical query across all 500 billion rows, or the day the business decides they want real-time dashboards on top of IoT data.
That’s the moment your perfectly tuned PostgreSQL instance becomes a bottleneck. And by then, you’re migrating under pressure.
The Bottom Line
The Reddit consensus surprised me: the most upvoted comments argued for doing nothing. And they made good points. PostgreSQL can handle this workload for a long time if you manage the risks.
But “can handle” and “should handle” are different questions. The anxiety in the original post isn’t about performance, it’s about survivability. The database runs fine today. The question is whether your team can survive a failure of that database tomorrow.
If you have strong PostgreSQL expertise, good monitoring, and clear recovery procedures, stay the course. If you’re running on hope and the kindness of your DBA who’s eyeing a new job, start evaluating alternatives now.
The 40TB PostgreSQL instance isn’t a problem. It’s a signal. And the signal is telling you that your architecture is due for an evolution.
For a broader perspective on where PostgreSQL fits in the current database landscape, check out Database 2025: PostgreSQL’s Hegemony and the Great Data Architecture Reshuffle. And if you’re evaluating real-time aggregation strategies, the scalability trap of dashboard queries is essential reading.
The best time to plan your breakup with PostgreSQL was six months ago. The second-best time is right now, while your instance is still running smoothly and you have the luxury of choice.