Microsoft just dropped VibeVoice-Realtime-0.5B, a streaming text-to-speech model that generates audible speech in roughly 300 milliseconds. That’s fast enough to beat most human conversational gaps, which typically hover between 100-300ms. The model’s interleaved architecture lets it start vocalizing before an LLM finishes writing the complete response, a technical flourish that could redefine voice assistant responsiveness. But as developers rushed to implement it, many discovered that the most important specification wasn’t in the model card: it only supports English and Chinese. Everything else? Good luck getting anything intelligible.
This gap between technical capability and practical limitation captures the tension in modern AI releases. We get frontier performance wrapped in open-source MIT licensing, then stumble over basic utility constraints that aren’t obvious until you’ve spent twenty minutes installing dependencies.
The Architecture: How It Beats the Latency Game
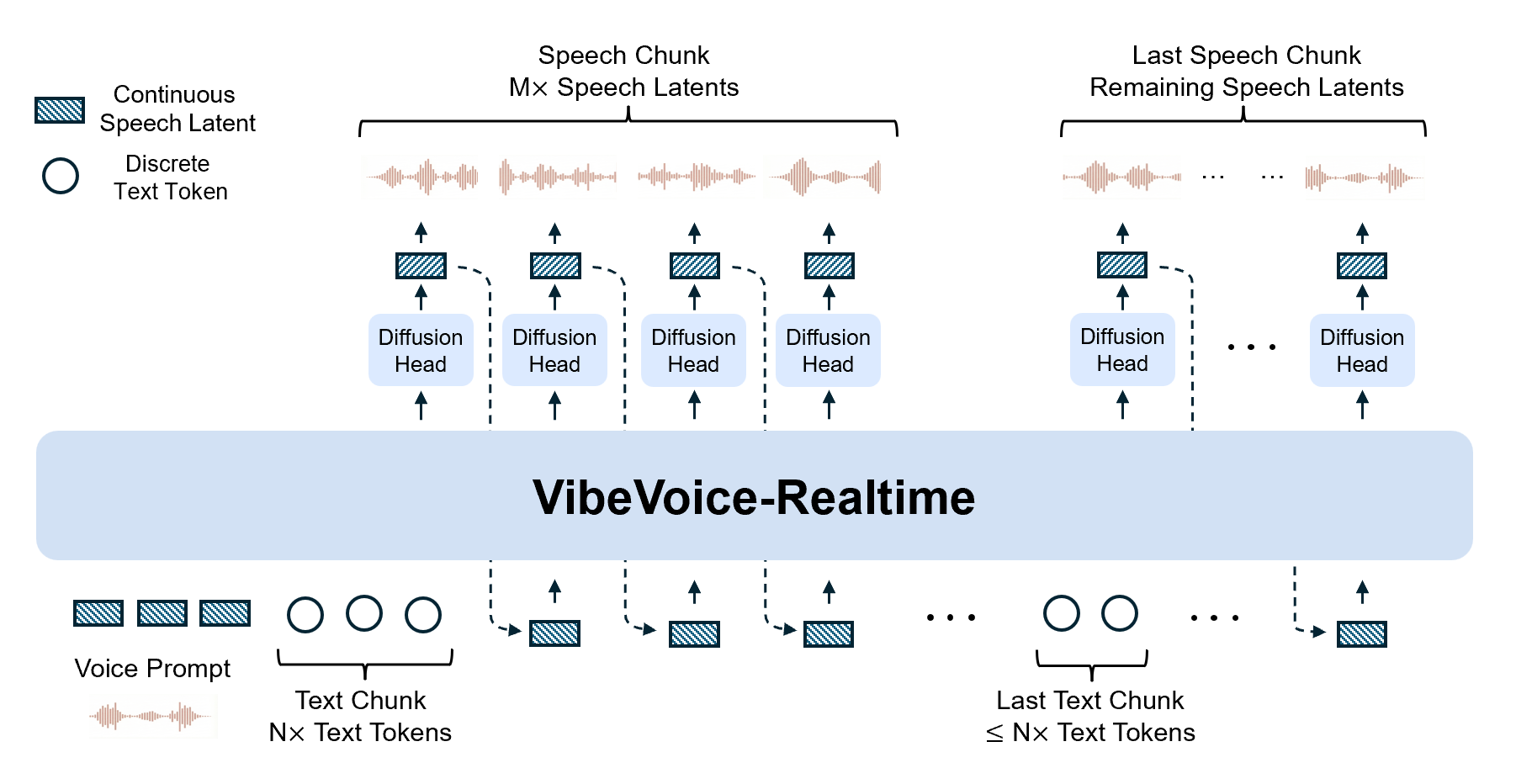
VibeVoice-Realtime pulls off its speed through a clever interleaved, windowed design. Instead of waiting for complete sentences, it incrementally encodes incoming text chunks while simultaneously running diffusion-based acoustic latent generation from prior context. The model ditches the semantic tokenizer found in larger variants and relies solely on an efficient acoustic tokenizer operating at an ultra-low 7.5 Hz frame rate.
Built on top of Qwen2.5-0.5B, the system combines three core components:
- A 0.5B parameter LLM that processes discrete text tokens
- A σ-VAE acoustic tokenizer with a mirror-symmetric encoder-decoder structure achieving 3200x downsampling from 24kHz audio
- A lightweight diffusion head (4 layers, ~40M parameters) that bridges LLM hidden states to acoustic features
The tokenizer pretrained first, then the VibeVoice training froze it and trained only the LLM and diffusion head with a curriculum that scaled input sequence length from 4K to 8K tokens. This approach keeps the deployment footprint small, around 2GB total, while maintaining robust long-form generation.
Performance That Punches Above Its Weight Class
The model’s benchmarks show it competing with systems many times its size. On LibriSpeech test-clean, VibeVoice-Realtime hits a WER of 2.2% and speaker similarity of 0.695, outperforming Voicebox (WER 1.9%, similarity 0.662) and VALL-E 2 (WER 2.4%, similarity 0.643). On the SEED test-en set, it achieves 2.05% WER with 0.633 speaker similarity.
But here’s where context matters: those numbers were achieved in controlled English-language tests. The model’s architecture supports streaming, but the training data doesn’t extend to the polyglot capabilities developers now expect from modern TTS systems.
The Language Problem Hiding in Plain Sight
Developer forums lit up when parrot42 bluntly stated: “It is for english and chinese.” The response was immediate and revealing. One developer working on German applications voiced frustration that multilingual capability was barely mentioned in the model card. Another, building a Marathi model, shared their own experience: “i made my own finetuned marathi model which is less than 500mb in size and 50ms latency. WER is 35% (i need to train more, my free credits ran out apparently).”
The sentiment crystallized around a simple complaint: “I hate the fact that this ‘small’ detail is never cited.” And it’s not just Reddit griping, Microsoft’s own documentation acknowledges the limitation but buries it. The “Out-of-scope uses” section warns that “Unsupported language, the model is trained only on English data, outputs in other languages are unsupported and may be unintelligible or inappropriate.”
This pattern repeats across AI releases. Companies lead with impressive technical specs while relegating practical constraints to footnotes. For developers building global applications, that’s not a minor detail, it’s a project-killing limitation. The multilingual expectation has become so normalized that omitting it feels like selling a car without mentioning it only drives on two specific highways.
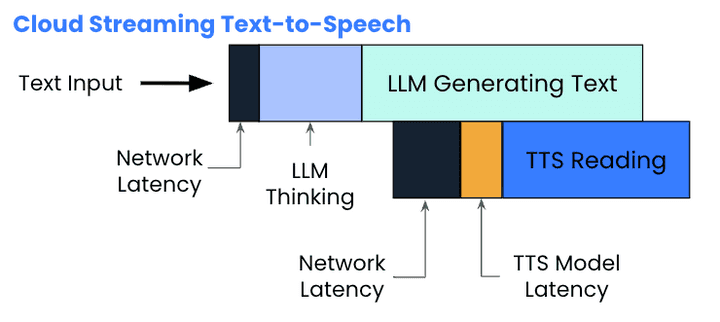
Streaming vs. Output: Why Architectural Choices Matter
The Picovoice benchmark data puts VibeVoice’s performance in perspective. While VibeVoice claims ~300ms first audible latency, fully on-device solutions like Orca TTS achieve 130ms by eliminating network overhead entirely. The comparison chart reveals how different approaches impact user experience:
| TTS Engine | First Token to Speech Latency |
|---|---|
| Amazon Polly | 1090 ms |
| Azure TTS | 1140 ms |
| ElevenLabs | 1150 ms |
| ElevenLabs Streaming | 840 ms |
| OpenAI TTS | 2110 ms |
| Picovoice Orca | 130 ms |
VibeVoice sits somewhere between traditional cloud TTS and optimized on-device engines. Its streaming architecture accepts text incrementally while the LLM generates, enabling dual-streaming scenarios where audio begins before text completion. This approach eliminates the awkward silence of output-only streaming, where systems wait for entire responses before synthesis begins, a method that can push latencies past 3000ms in real-world conditions.
Getting It Running: The 20-Minute Setup
For developers ready to test despite the language limitations, installation is straightforward. Based on community feedback, the process takes about 20 minutes from git clone to first audio:
git clone https://github.com/microsoft/VibeVoice
cd VibeVoice
pip install -e .
export MODEL_PATH=~/.cache/huggingface/hub/models--microsoft--VibeVoice-Realtime-0.5B/snapshots/<hash>
python -m uvicorn demo.web.app:app
# Navigate to localhost:8000The ComfyUI wrapper at https://github.com/wildminder/ComfyUI-VibeVoice provides an alternative interface, though some developers find it less intuitive than the stock web demo. The model runs on consumer GPUs but also works on CPU thanks to its 0.5B parameter size, remarkably efficient for neural TTS.
The Missing Model and Safety Theater
Another quiet issue emerged: Microsoft links to VibeVoice-Large in their model comparison table, but the URL leads to a 404 page. The Hugging Face collection page still lists it, but access remains broken. For developers evaluating the full VibeVoice family, a dead link undermines confidence in Microsoft’s commitment to the release.
Safety features present a mixed bag. The model includes:
– An audible disclaimer automatically embedded in generated audio
– Imperceptible watermarking for provenance tracking
– Restrictions on voice cloning and real-time voice conversion
But these safeguards feel performative when paired with vague documentation. The “Responsible Usage” section warns about “technical or procedural safeguards” without specifying what they are or how they trigger. Developers building commercial products need transparency, not liability hedging. As one developer put it: “What does it trigger off of and what does it do? How can you incorporate it into a product if you don’t understand its limitations.”
Real Talk on Use Cases
VibeVoice-Realtime delivers where it promises: English-language, real-time voice applications. It works for narrating live data streams, powering voice assistants, and enabling LLMs to speak as they think. The model handles numbers, inflections, and long-form content without the robotic monotony of older TTS systems.
But the limitations are stark:
– No code, formulas, or special symbols – The model chokes on technical content
– No overlapping speech – Can’t handle conversational turn-taking naturally
– No music or sound effects – Strictly speech synthesis
– English/Chinese only – Critical for global applications
– Voice cloning disabled – Can’t replicate specific speakers even with consent
For academic research or English-only products, these constraints may not matter. For everyone else, they’re dealbreakers.
The Bigger Picture: Open Source vs. Useful Open Source
Microsoft’s release strategy follows a pattern: deliver technically impressive models with significant caveats. The MIT license suggests freedom, but the baked-in limitations, language support, watermarking, voice cloning restrictions, narrow the practical use cases.
This creates friction in the open-source AI community. Developers want models they can adapt, fine-tune, and deploy without hidden constraints. The 0.5B parameter size makes VibeVoice accessible for research labs and startups with limited compute. But the language barrier means many will pull the repo, spend hours setting it up, then discover it can’t serve their needs.
Meanwhile, community efforts like CaroTTS-60M-DE demonstrate demand for truly multilingual, lightweight TTS. The developer behind it shared training code on GitHub that runs on consumer GPUs, a model of open-source transparency that contrasts with Microsoft’s selective openness.
Takeaways for Developers
You should use VibeVoice-Realtime if:
– You’re building English or Chinese voice applications
– Latency under 300ms is critical
– You need streaming synthesis that starts before LLM completion
– Deployment resources are constrained (edge devices, low-end GPUs)
You should look elsewhere if:
– Multilingual support is non-negotiable
– You need voice cloning or speaker customization
– You’re synthesizing technical content with code or formulas
– You require deterministic safety guarantees with clear documentation
The model represents genuine progress in efficiency and streaming architecture. Microsoft’s decision to open-source it, 404 links aside, moves the field forward. But the gap between technical achievement and practical utility remains a recurring theme in AI releases.
For now, VibeVoice-Realtime is a specialized tool masquerading as a general-purpose solution. Evaluate it on what it actually does, not what the headlines suggest. And read the fine print, twice.
VibeVoice-Realtime-0.5B is available on Hugging Face and GitHub. Technical details are published in the VibeVoice Technical Report.