The numbers are in, and they’re not what the AI hype machine promised.
An NBER study tracking telemetry from over 100,000 GitHub developers dropped a truth bomb that’s been rattling around engineering Slack channels ever since. Depending on the workflow, weekly lines of code changed shot up by 650% to 740%. Commits effectively doubled.
But actual production releases? Only up by about 30%.
To put it crudely: we’re buying 7x more review, QA, and maintenance work to get a 30% increase in releases. The ROI math looks terrible, and the deeper implications for how we structure engineering teams are only starting to surface.
The Weak Link Hypothesis: Why Your Pipeline Is Clogged
The study’s authors propose what they call the “weak-link hypothesis.” AI is extraordinarily effective at generating raw code, but everything after that, reviewing PRs, integrating changes, testing, and managing releases, still relies on human effort and judgment.
Alfonso Graziano, AI technical lead at Nearform, articulates this perfectly: “A system’s throughput is set by its slowest stage. If you speed up any other process, the throughput does not change. The only thing that grows is the pile of work-in-progress in front of the real constraint.”
This isn’t just theory. The researchers found that task-level productivity gains “attenuate sharply” as work moves up the organizational hierarchy. That 741% increase in code written translates to only a 65% bump in pull requests, and that 20% bump in actual releases.
The Generational Tool Analysis
The study evaluated three successive generations of AI coding tools, and the progression reveals something important about where we are and where we’re headed:
| Tool Generation | Cumulative Gain in Coding Activity |
|---|---|
| Early autocomplete (e.g., original GitHub Copilot) | +40% |
| Interactive sync agents (e.g., Claude Code) | +140% |
| Autonomous async agents | +180% |
The progression is impressive, but the attenuation remains consistent. Each generation improves the ceiling, but none has meaningfully moved the floor of downstream bottlenecks.
One Reddit user working in a government-regulated environment captured the frustration: “Our bottleneck has never been the generation of source code. It’s always the documentation and test plans that are associated. AI helps with the implementation of the test plans, but that’s a mere drop in the proverbial bucket.”
Another commenter distilled the entire problem into a single devastating sentence: “It’s like the industry suddenly forgot the SDLC. Writing code has always been a small fraction of the entire lifecycle. Maintenance always taking the lion’s share. So far, AI is poor during the maintenance phase.”
Are We Buying 7x the Review Work?
One commenter on the original Reddit thread posed the question that should keep every engineering manager up at night: “Are we basically buying 7x more review, QA, and maintenance work to get a 30% increase in releases?”
The answer, based on the data, appears to be a qualified “yes.”
The paper itself notes a critical nuance that makes this even messier: coding agents are known to write more verbose code, which can mechanically inflate lines and files without increasing substantive output. But that’s not a comforting caveat, it’s a compounding problem.
Even if a large part of that extra code is tests, mocks, fixtures, wrappers, or supporting utilities, it still becomes code that someone has to review, understand, maintain, refactor, and debug later. A bloated test suite is still part of the system.
This is where superficial review becomes dangerous. AI-generated changes can look internally consistent: implementation, tests, helper code, and fixtures may all agree with each other. The tests can pass while the whole patch is still solving the wrong problem or adding unjustified complexity.
Josh King, CTO of &above, has observed this shift firsthand. “Developers still think of themselves as writers of code,” he says, “but their actual job is now evaluators of code.” His firm has gone from three or four open PRs at one time on a project to 20-plus. Review is now about half of a developer’s job.
The Production Context Stack: Where AI Fails in the Real World
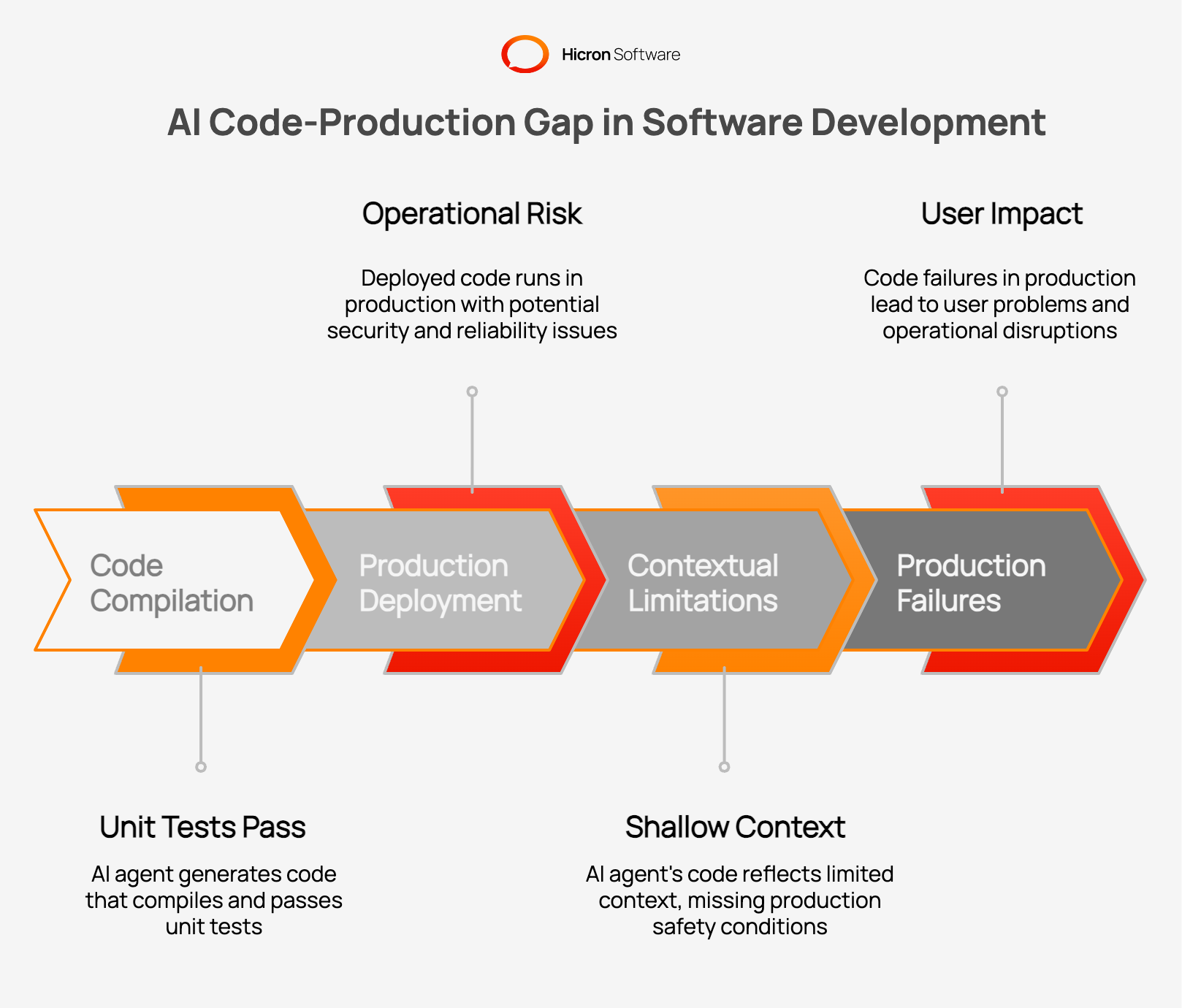
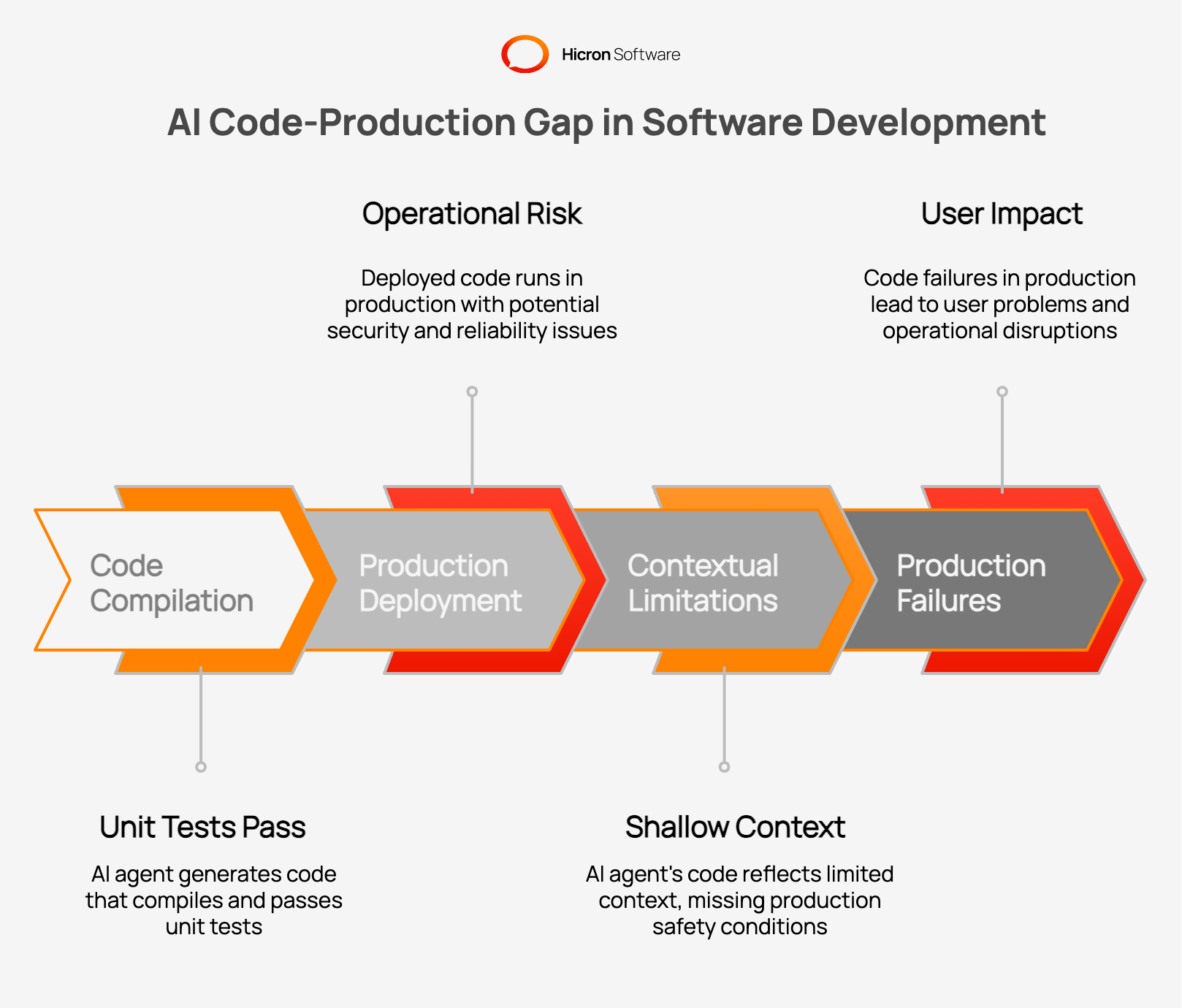
The problem isn’t just volume, it’s context. The AI code-production gap is the distance between code that compiles and code that runs safely in production.
AI agents operate on limited context. They see files, prompts, and examples, but they miss the implicit knowledge that senior engineers carry: team habits, past incidents, architecture decisions made years ago, security policies, customer contracts. When those constraints stay implicit, the model treats them as absent.
| Context Category | What AI Typically Misses | Real-World Impact |
|---|---|---|
| Operational | SLOs, recovery targets, runbooks, capacity limits | Features that can’t be debugged or recovered |
| Security | Resource-level authorization, input validation standards | Data leaks, injection vulnerabilities |
| Data | Retention policies, migration strategy, constraint rules | Compliance violations, corrupted state |
| Architecture | Ownership boundaries, integration contracts, coupling rules | Architectural drift, merge conflicts |
| Business | Who absorbs failure cost, contractual promises | Wrong priorities, feature-flag debt |
This is not a model failure. It’s a context failure. A human engineer remembers the painful outage that followed a naive retry loop. An AI agent treats that knowledge as absent unless explicitly documented.
The ROI Reality Check
The cost implications are staggering. One developer reported their monthly GitHub Copilot bill going from $29 to $750. Another went from $50 to $3,000. A company with 80 developers calculated their monthly spend would now equal the annual salary of a full-time engineer.
These are not edge cases. These are the leading indicators of a structural problem.
The hidden cognitive debt of AI productivity gains is real, and it’s expensive. Dr. Margaret-Anne Storey, co-author of the SPACE and DevEx frameworks, describes this as “cognitive debt”, the erosion of the collective mental model of what a system does, how it was designed, and how it can be safely changed. Unlike technical debt, cognitive debt lives in people and manifests as loss of confidence, heavier review burden, slower onboarding, and increased stress.
Downstream Signal: The Marketplace Reality Check
The most damning finding in the study goes beyond GitHub activity. The researchers also examined marketplace outcomes: whether more software was being published and whether users were actually consuming more of it.
The pattern is sobering: much more code, a smaller increase in releases, and no comparable increase in measured marketplace usage.
This kills the optimistic counterargument that “releases just became larger and more valuable.” If that were true, we’d expect to see some downstream demand signal. The paper found more app releases across platforms like the Apple App Store and Google Play Store since mid-2025, but total app usage remained entirely flat.
More software is getting published, but users are not pulling it through at the same rate. A growing share of these new applications is failing to attract any meaningful audience. Flooding the market with AI-assisted software does not automatically translate into value or discovery for users.
This aligns with broader patterns of AI investments failing to deliver promised results. The gap between upstream production and downstream value is not being bridged.
What to Do: Practical Guidance for Engineering Teams
If you’re an engineering manager or team lead staring at this data and wondering what to do, here’s the actionable framework:
1. Measure the Right Things
Stop tracking lines of code written or commits pushed. Track PR throughput, change failure rate, and mean time to recovery. The displacement vs. intensity paradox of AI means that raw output metrics will mislead you.
2. Treat Code as Liability, Not Asset
Every additional line of code is surface area to review, test, secure, debug, operate, refactor, and maintain. Those are real engineering costs, regardless of whether the code was written by a human or generated by an AI.
3. Invest in Downstream Infrastructure
If code generation is 7x faster but review is still human-paced, you need to invest in automated review tools, better test generation, and workflow automation that helps humans keep up. The burnout crisis driven by AI productivity tools is real, and it’s accelerating.
4. Build the Production Context Stack
Make production knowledge explicit before asking for code. Document intent, constraints, verification requirements, operational needs, and accountability decisions. The more explicit your context, the less the model has to guess.
5. Audit Your Delivery Model
Find the layer of your production context stack that stays implicit rather than documented. Make it explicit. Build that structure first, then add more AI autonomy.
The Real Question
The key question for engineering teams is no longer whether AI can write code. The better question is whether your organization can make enough production knowledge explicit for AI to work safely within it.
Teams that win will not be the fastest at generating output. They will be the ones that turn engineering judgment into reusable context, clear gates, and accountable release decisions.
The AI doesn’t need to get better at writing code. It needs to get better at understanding why code matters, and that’s a problem that no model can solve for you.
[This analysis draws on the NBER Working Paper “Writing Code vs. Shipping Code: Productivity Effects Across Generations of AI Coding Tools” (Demirer, Musolff, Yang, May 2026) and subsequent coverage by LeadDev, Hicron Software, and DX research.]