One Big Table: Data Modeling Heresy or the Only Thing That Actually Works?
The data engineering team at a mid-sized SaaS company gathered for their weekly architecture review, and tension filled the room. On the projector: a 400-column table named user_events_all_time. The senior data architect, a Kimball methodology veteran, looked physically pained. The analytics engineer who built it, a recent bootcamp grad, couldn’t understand the fuss. “It’s just easier”, they explained. “Everyone gets the same data. No joins needed. Business users love it.”
This scene is playing out in data teams everywhere, and it’s exposing a philosophical rift that goes far beyond technical preferences. The rise of “One Big Table” (OBT) as a modeling approach isn’t just another architectural debate, it’s a direct challenge to decades of data warehousing orthodoxy, pitting governance against agility, rigor against speed, and tradition against modern cloud-native pragmatism.
The Star Schema Gospel (And Why It Still Preaches)
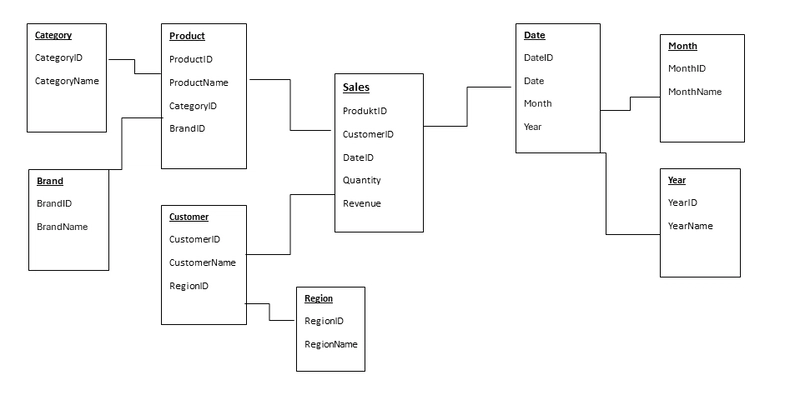
For twenty years, dimensional modeling has been the closest thing data engineering has to scripture. The Kimball methodology, with its facts and dimensions, star schemas and slowly changing dimensions, provided a vocabulary and framework that turned raw data into business meaning. As one veteran practitioner noted in a recent discussion, the process of building a star schema forces you to confront uncomfortable truths about your data, grain mismatches, relationship ambiguities, edge cases that break your assumptions. The modeling process itself is the value.
The star schema’s advantages are well-documented and battle-tested:
- Query performance: Modern data warehouses optimize aggressively for star patterns, using bitmap indexes and columnar storage to make joins between fact and dimension tables nearly free
- Business comprehension: Non-technical stakeholders can understand a star schema. You can explain “sales facts” and “customer dimensions” without a CS degree
- Tool compatibility: Power BI, Tableau, and Looker are built to consume star schemas, they struggle with monolithic tables
- Governance: Conformed dimensions create a single source of truth. Update a product category once, and it propagates correctly everywhere
But here’s where the controversy ignites: many younger practitioners, especially those who entered data after the Big Data/Spark era, see star schemas as unnecessary ceremony. Why spend weeks modeling dimensions when you can flatten everything into a single, wide table and let analysts self-serve?
The OBT Insurrection
The case for One Big Table is deceptively simple: eliminate joins, eliminate complexity, eliminate the need for deep modeling expertise. In distributed systems like BigQuery or Snowflake, where data shuffling across nodes dominates query cost, OBT can reduce computational overhead. One performance analysis from Fivetran suggests distributed query engines can use less compute on OBT for certain workloads, though this comes with caveats that matter enormously.
The real driver behind OBT’s adoption isn’t performance, it’s organizational agility. In companies where the business model pivots quarterly, where new data sources appear overnight, and where analytics engineers outnumber data architects, OBT offers a seductive promise: we can move fast without breaking things.
As one team lead in a Reddit discussion explained, maintaining a Kimball warehouse at a hypergrowth company means rebuilding your entire warehouse every few years when the CEO pivots or a merger introduces entirely new business entities. OBT’s flexibility becomes a feature, not a bug.
But this flexibility comes at a cost that traditionalists find unacceptable.
The Multivalued Dimension Trap
Here’s where OBT starts to crack: multivalued dimensions. When a single order has multiple products, or a user belongs to multiple segments, or a session spans multiple marketing campaigns, OBT forces you into ugly choices. Some teams resort to DISTINCT everywhere as a band-aid. Others duplicate rows, destroying aggregate accuracy. A few brave souls nest arrays in columns, turning their “simple” table into a complex nested data structure that defeats the original purpose.
The criticism runs deeper than technical limitations. Critics argue that OBT skips the conceptual modeling stage entirely, the critical work of defining business entities, their relationships, and what they actually mean. Without this rigor, you end up with a table that has 50 columns named some variation of user_id, each meaning something slightly different depending on which source system it came from. The semantic clarity that made data warehouses valuable evaporates.
The Performance Myth (And Why Everyone’s Partially Wrong)
Both sides are making outdated performance arguments.
Star schema advocates correctly note that a well-built star with placeholder records in dimensions enables inner joins, which are faster than outer joins. But they’re still thinking in terms of traditional RDBMS optimization, not distributed MPP engines where data locality and shuffling dominate.
OBT advocates correctly note that eliminating joins reduces query planning overhead in distributed systems. But they ignore storage amplification, denormalizing a 50-million-row fact table with 100-dimension attributes can explode your storage costs and slow down full-table scans.
The reality? Modern cloud data warehouses are so fast and so different from their ancestors that old rules of thumb are increasingly unreliable. One Power BI user found that star schemas sometimes consume more memory in the VertiPaq engine than flattened OBTs, while another noted that properly partitioned and clustered OBTs can outperform stars for narrow, well-filtered queries.
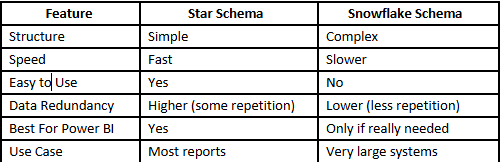
The Hybrid Approach: Having Your Cake and Eating It Too
The most sophisticated teams aren’t choosing between star schema and OBT, they’re using both, but at different layers. The pattern that’s quietly becoming best practice looks like this:
-
Foundation Layer: Build a proper Kimball star schema in your warehouse. Do the hard modeling work. Create conformed dimensions. Define grains. Document everything.
-
Consumption Layer: Create OBTs as materialized views or dbt models that sit on top of your stars. These serve specific personas: data scientists who want to pull data into pandas, business analysts who live in Excel, or ML pipelines that need feature vectors.
-
Governance Boundary: The star schema remains your system of record. The OBTs are derivative, documented, and version-controlled, they’re interfaces, not infrastructure.
This approach acknowledges a truth that purists miss: different users need different data shapes. A star schema optimized for BI tools doesn’t serve a data scientist training a churn model. An OBT that makes analysts happy doesn’t provide the governance finance needs for compliance reporting.
The Generational Divide (And Why It Matters)
The OBT debate isn’t really about technology. It’s about who gets to define “good enough.”
Veteran data architects spent careers building data warehouses that lasted a decade. They learned hard lessons about technical debt and governance failures. To them, OBT looks like repeating every mistake that led to the “data swamp” era promised to fix.
Analytics engineers who grew up with cloud-native tools and agile methodologies see those same governance processes as bureaucracy. Their stakeholders demand answers in hours, not months. To them, star schema looks like waterfall development in a SaaS world, beautiful in theory, irrelevant in practice.
This isn’t just a workplace disagreement. It reflects a fundamental shift in data’s role. When data was a support function, governance and stability mattered most. Now that data is a product, speed and accessibility win.
The Verdict: Context Is The Only Architecture Pattern
The OBT debate doesn’t have a winner because it’s asking the wrong question. The right question is: What does your organization need to optimize for?
Choose star schema as your foundation if:
– You have complex business logic that needs careful modeling
– Governance, compliance, and auditability are non-negotiable
– Your analytics stack is BI-tool heavy (Power BI, Tableau, Looker)
– You can afford slower initial development for long-term stability
Embrace OBT at the consumption layer if:
– Business requirements change faster than you can model
– Self-service analytics is a primary goal
– You’re serving technical users who can handle denormalized data
– Your warehouse costs are manageable even with storage amplification
Never build OBT as your source of truth. The flattening should happen late in your pipeline, close to the user. Your foundation should remain normalized enough to maintain semantic clarity.
The most telling insight from the community discussion isn’t about performance or storage. It’s this: experienced practitioners who hate OBT as a foundation still build OBT views for specific users. And OBT advocates who dismiss star schemas still need to understand grain and relationships to avoid creating unmaintainable monsters.
The Uncomfortable Truth
OBT isn’t a modeling methodology, it’s a delivery pattern. And that’s okay. The original sin isn’t using OBT, it’s pretending it replaces the hard work of understanding your data.
The heated arguments reveal a field struggling to define its best practices for a new era. Cloud data warehouses, self-service BI, and analytics engineering have changed the constraints so fundamentally that old certainties feel shaky. But the core principle remains: you can’t skip conceptual modeling. Whether you call them dimensions or “entity attributes”, whether you store them in separate tables or nested structs, you still need to understand what your data means.
The teams that thrive will be the ones who stop treating this as a religious war and start treating it as a layering problem. Build a solid, modeled foundation. Expose fit-for-purpose interfaces on top. And have the architectural honesty to admit which layer is which.
Your star schema doesn’t make you a dinosaur. Your OBT doesn’t make you a cowboy. But claiming either is a universal solution might make you both wrong.