The timing is brutal for competitors. It comes hot on the heels of Alibaba’s Qwen 3.7 Max launch and right as the industry is still digesting Claude Fable 5’s Mythos-class capabilities. This release could be the shot across the bow that finally breaks the open-weight ceiling wide open.
The Architecture That Makes 1M Context Practical
To understand why this matters, you need to understand what makes M3 different. The secret sauce is MiniMax Sparse Attention (MSA), a new attention mechanism that fundamentally changes the economics of long-context inference.
Standard full attention has a quadratic computational cost, double the context length, quadruple the compute. At 1M tokens, that math becomes prohibitively expensive for all but the most well-funded labs. MSA solves this with a two-stage mechanism: a lightweight index branch scans incoming tokens and selects which blocks of the key-value cache are actually relevant, then full attention runs only on those selected blocks.
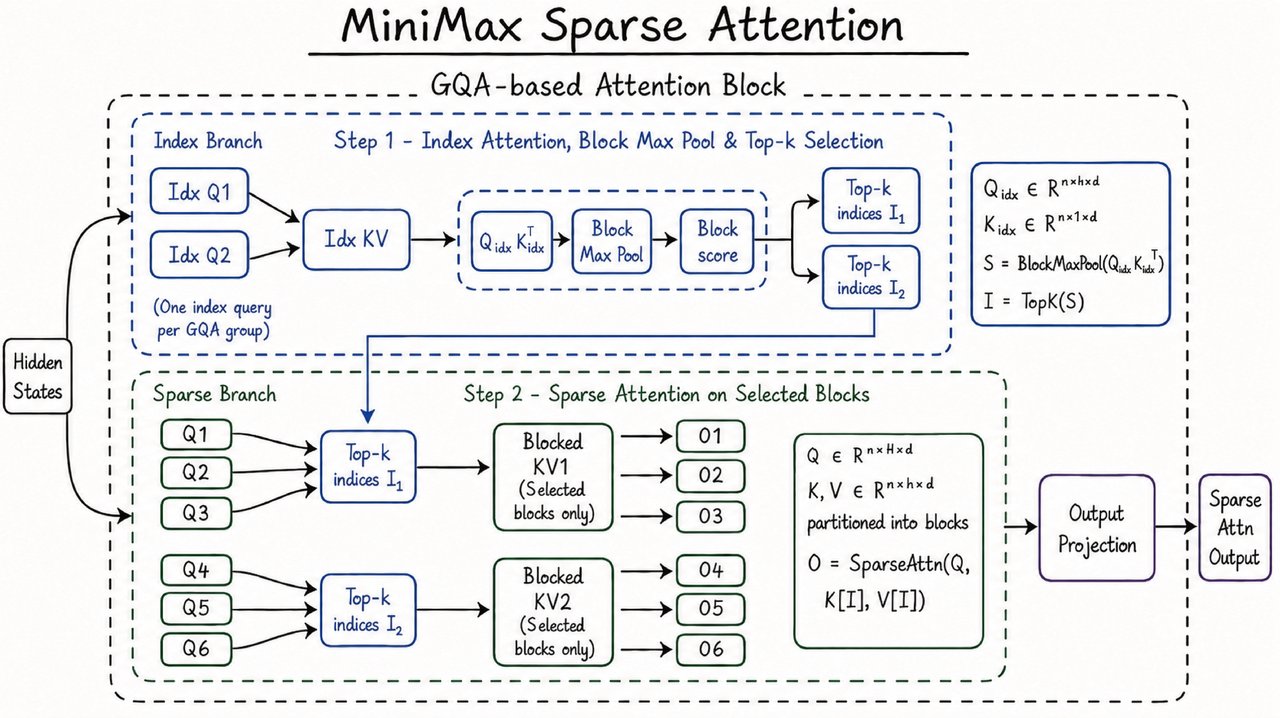
The numbers tell the story. At 1M-token context, MiniMax reports 9x faster prefill, 15x faster decoding, and roughly 1/20th the per-token compute of its predecessor M2.7. This isn’t a theoretical improvement, it’s the difference between a model that’s useful at 1M context and one that’s a marketing gimmick.
The comparison worth making is to DeepSeek’s Multi-head Latent Attention (MLA), which compresses KV pairs into a low-dimensional latent space. MSA keeps KV uncompressed and uses block-level selection. For developers, the practical impact is that MSA produces a model that maintains useful long-context performance at a price point where 1M-token requests aren’t reserved for funded AI labs.
The License Question Everyone’s Avoiding
The elephant in the room is the license. MiniMax’s prior model M2.7 launched under a “Modified-MIT” that restricted commercial use without written authorization, covering products charged to third parties, API interfaces, and post-fine-tuning deployment for profit.
The community reaction was swift and brutal. One developer captured the sentiment well: “Intent doesn’t matter, what license restricts matters, and they restricted themself from actual usage and yet it seems they learned nothing.” Another noted that the license “went way beyond” expressed intent, and that MiniMax “carefully avoided clarifying this overreach.”
Ryanlee-dev’s mention of a “community-friendly license” has people cautiously optimistic, but there’s legitimate skepticism. The fact that they’re still drafting the license on the day of release suggests either last-minute negotiations or careful calibration of what restrictions to impose.
If your plan involves self-hosting M3 for a commercial product, read the license terms before you architect around it. The weights being available for download doesn’t automatically mean they’re free to deploy commercially.
Where M3 Actually Competes
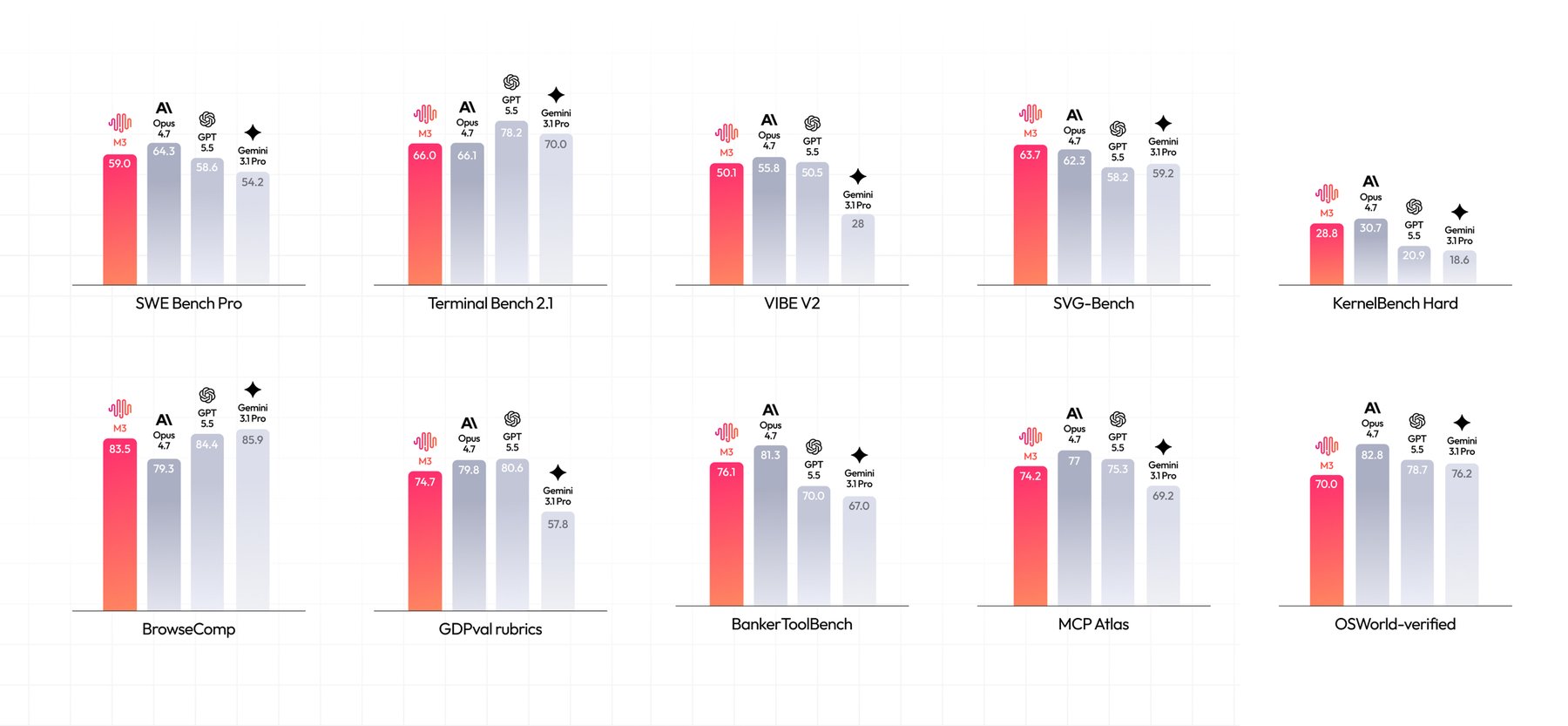
The benchmark performance and cost analysis of MiniMax M3 paints a clear picture. On SWE-Bench Pro, M3 scores 59.0%, just ahead of GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%), and behind Claude Opus 4.8 (69.2%). On Terminal-Bench 2.0, it hits 66.0% against Qwen 3.7 Max’s 69.7%.
But the real story is the cost. At standard pricing of $0.60/$2.40 per 1M tokens (and promotional pricing at $0.30/$1.20), M3 is roughly 15x cheaper than Claude Opus ($5/$25) and over 25x cheaper than GPT-5.5. When you’re running agentic coding pipelines or processing long documents at scale, that price gap becomes the deciding factor.
The emerging pattern among developers evaluating M3 is hybrid routing: use M3 for cost-sensitive, high-volume, long-context work, and route to a closed frontier model for the narrow slice where the last quality points matter.
The Model Size Mystery
One of the most intriguing aspects of this release is the complete uncertainty around model size. The community is buzzing with speculation. Some point to a reference in the research paper suggesting a 109B model with 6B active parameters (“A6B” in the paper’s shorthand). Others note that this was likely just a validation model.
One developer who’s been tracking the rumors calculated: “If we’re talking Kimi intelligence but smaller than GPT 120B people are going to freak out.” Another countered: “I’d be shocked, all indications from their team were that they were scaling up for M3. I’m expecting 300-600B total, active could still be low.”
The most intriguing data point comes from Atlas Cloud, which mentions “only 10 billion activated parameters” in their model description. If true, a ~109B total parameter MoE with 10B active parameters achieving these benchmarks would be genuinely revolutionary, implications for local deployment, inference cost, and accessibility would be massive.
| Hardware Setup | Quantization | Estimated Speed | Best For |
|---|---|---|---|
| Mac Studio M4 Ultra 192GB | Q4_K_M (GGUF) | 15-30 t/s | Development |
| 4× NVIDIA H100 80GB | BF16 | 60-100+ t/s | Production |
| 4× NVIDIA RTX 4090 | Q4_K_M | 20-40 t/s | Hobbyist cluster |
| Single NVIDIA RTX 4090 | , | N/A | Use the API instead |
The hardware reality is clear: consumer single-GPU setups aren’t going to work for local inference. But a Mac Studio with 192GB of unified memory? That’s suddenly viable for development work.
M3 vs. the Open-Weight Field
The competition is fierce. Qwen 3.7 Max (60.6% SWE-bench Pro, $7.50/1M output) leads on published coding benchmarks but is API-only. DeepSeek V4 ships under MIT license and leads open weights at 80.6% SWE-bench Verified. Then there’s the M2 model as prior generation in MiniMax open-weight lineage, which established MiniMax’s credibility in this space.
The key differentiator for M3 is native multimodality. No other open-weight model at this capability level offers native image and video input. On MMMU-Pro, M3 scores ~80%, level with GPT-5.5 and Kimi K2.6. For developers who need to process UI screenshots, architecture diagrams, or video walkthroughs alongside code, M3 is the only open-weight option.
The Autonomous Capabilities That Matter
What separates M3 from bench-maxxed competitors is its demonstrated autonomous capabilities. MiniMax ran three internal experiments that show the model can work independently over many hours:
- Paper reproduction: M3 independently reproduced an ICLR 2025 paper on LLM fine-tuning, working for nearly 12 hours without intervention, producing 18 commits and 23 figures.
- Kernel optimization: Given only a task description and a non-functional code skeleton, M3 pushed NVIDIA Hopper GPU utilization from 7.6% to 71.3% over 147 submissions. Most tested models gave up after a few dozen attempts. M3 didn’t reach its best solution until attempt 145.
- PostTrainBench: M3 trained four base models from scratch, synthesizing data, training, evaluating, and iterating without human input, landing just behind Opus 4.7 and GPT-5.5.
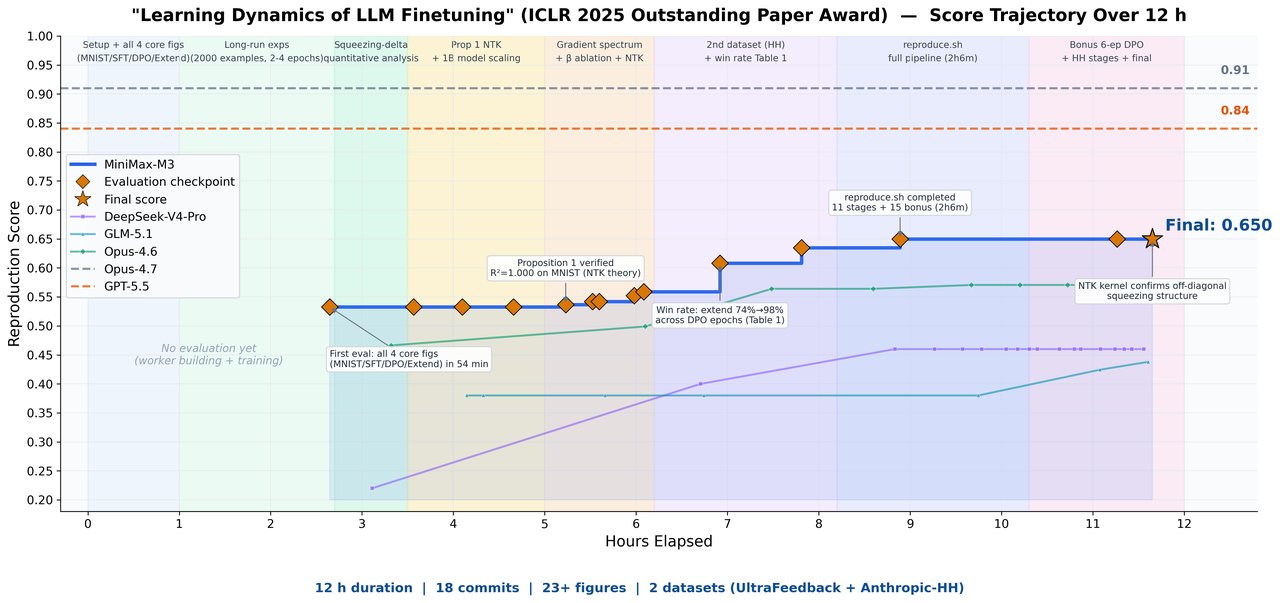
These aren’t synthetic benchmarks. They’re real demonstrations of sustained autonomous problem-solving that directly challenge the narrative that only closed-source models can handle complex agentic workflows.
The Real-World Experience
Early users have been impressed. One developer who tested M3 against GPT-5.5 on market research reported: “MiniMax did it incomparably better. Like, a class level better. I was very surprised by this, but well… this model is very good, not just benchmaxxed I guess.”
Another user tested M3 for novel writing and noted: “This is only model from me for China that know how to make dynamic plot, how to make multi scene plot. Other big model like DeepSeek/MiMo 2.5 Pro it love to on one character until the chapter end one line plot.”
Even on multilingual capabilities, traditionally a weakness for Chinese models, M3 performs adequately. One Polish-speaking developer reported: “It’s not good, but it’s good enough. Wouldn’t use it for creative writing in Polish, but should be fine for discussing or explaining stuff.”
The Distillation Question
The success of open-weight models raises uncomfortable questions about training data provenance. The trend of open-weight model success through distillation has been well-documented, and M3’s rapid capability leap, from M2.7’s 50 to M3’s 55 on the Intelligence Index, will invite scrutiny.
The broader industry shift toward open-weight models is accelerating. M3’s release, combined with DeepSeek V4’s MIT license and Qwen’s continued improvements, creates a genuine alternative to the closed-source frontier. For enterprise teams concerned about data sovereignty, vendor lock-in, or API dependency, this is the first moment where the capability-to-compliance trade-off genuinely tips toward self-hosting.
What to Watch When the Weights Drop
Friday’s release will answer several critical questions:
The license. “Community-friendly” could mean anything from Apache 2.0 to a modified version of the M2.7 license. Watch for language around commercial use, fine-tuning, and redistribution.
The actual size. The discrepancy between the 109B validation model and the production M3 needs clarification. Will we see 109B total with 6-10B active, or something larger?
Multimodal architecture support. M3’s new attention mechanism and multimodal capabilities mean it won’t work with standard inference frameworks out of the box. The vLLM and Transformers integrations will lag behind the weight release.
The technical report. The community has been waiting for the full paper since the API launch on June 1. It should contain architecture details, training data specifics, and independent benchmark scores.
M3 represents a genuine inflection point for open-weight models. It’s the first model to simultaneously deliver frontier-level coding, a practical 1M-token context window, and native multimodality under an open-weight license. The cost advantage is so large that it changes the deployment calculus for production systems.
But caveats matter. The vendor-reported benchmarks need independent validation. The license is unconfirmed. The hardware requirements are substantial. And the gap to the absolute frontier, Claude Fable 5’s 95.0% SWE-bench Verified, remains significant.
For the majority of teams building production systems, the calculus is straightforward: M3 delivers ~80% of the capability at 5-10% of the cost, with the added benefit of self-hosting and data sovereignty. That’s not a compromise, it’s the winning strategy for most use cases.
Friday can’t come soon enough.