Your event store has been running for three years. Millions of events. Then you realize your read model needs a new field. Do you replay everything from scratch, or pray your snapshots are consistent? This is the moment where architectural decisions stop being theoretical and start being expensive.
Event sourcing gives you an immutable log of truth, but that log is a double-edged sword. When it comes to bootstrapping read models, whether for the first time or during a schema evolution, you face a fundamental choice: replay every single event or rely on snapshots. Both paths lead to different flavors of pain.
The Replay Path: Brute Force Integrity
Event replay is the purist’s approach. You take every event from the beginning of time, apply your projection logic, and rebuild your read model state. It’s mathematically sound. If your projection function is deterministic, you’ll get the same result every time. No ambiguity. No “what if the snapshot was corrupted” anxiety.
But let’s talk about what this actually means in production. A mid-sized e-commerce system might generate 50 million events per year. Replaying that entire history can take hours or days. During that window, your new read model is either empty or stale. You’ve traded consistency for availability, and your product team is asking why the dashboard shows incomplete data.
The research from event-driven.io shows how this plays out in practice. When you spin up a background worker to pull all events since the beginning, you’re committing to eventual consistency in its rawest form. The article demonstrates a shopping cart projection that evolves from simple totals to a full status-and-items model. The catch? While that background worker churns through history, queries return outdated information.
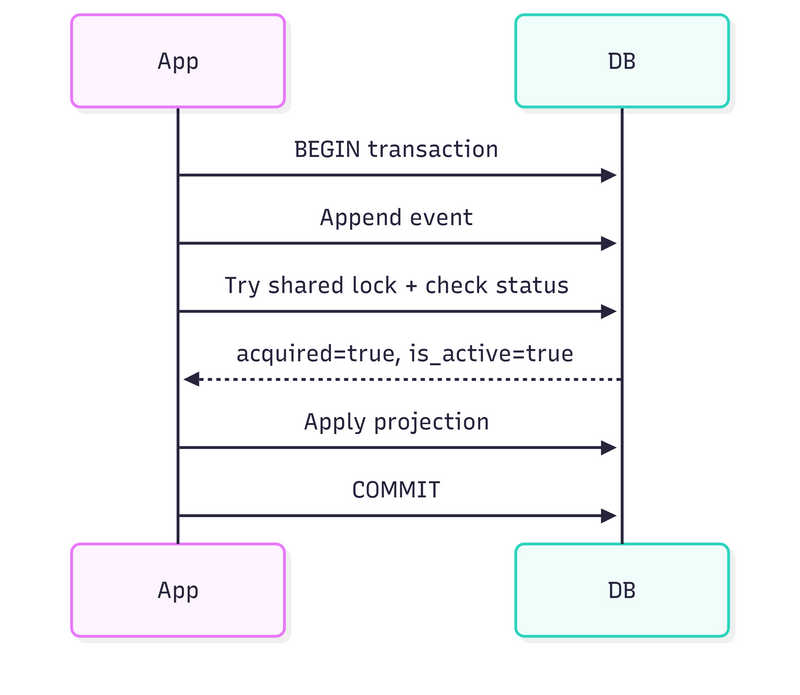
The concurrency challenges are brutal. As the article points out, if you’re rebuilding while new events arrive, you risk corruption. Their solution involves PostgreSQL advisory locks, a clever but complex coordination mechanism. Inline projections grab shared locks, while rebuilds take exclusive locks. It’s elegant, but adds microseconds to every single event append. At thousands of events per second, that overhead adds up.
The Snapshot Mirage: Performance at What Cost?
Snapshots promise to solve the performance problem. Instead of replaying everything, you persist intermediate states. Bootstrap your read model from the latest snapshot, then replay only events since that snapshot. A process that took hours now takes minutes.
But snapshots introduce a new problem: consistency guarantees. When exactly did you take that snapshot? Was it after event #4,582,291 or #4,582,292? And what happens if your snapshotting process crashes mid-write? You now have a corrupted snapshot that looks valid but isn’t.
The event-driven.io article exposes this vulnerability clearly. Advisory locks are session-scoped, if the connection dies, the lock releases automatically. Imagine this scenario: your snapshotting process crashes after processing half the events. The lock releases. Your inline projections start up again, seeing no lock. They begin processing new events while your snapshot is incomplete. Congratulations, you’ve just built a distributed race condition.
This is why the article proposes a hybrid approach: advisory locks for fast-path coordination plus a persistent status column for crash recovery. The status column survives connection failures, but now you’re maintaining two separate mechanisms for what should be a single guarantee.
The Operational Tax Nobody Talks About
Here’s where the debate gets spicy. Everyone focuses on the rebuild scenario, but that’s the easy case. The real pain is day-to-day operations.
With pure replay, your operational burden is simple but heavy. Every new read model means another full replay. Every schema change means scheduling maintenance windows. Your storage costs grow linearly with event volume. But your operational model is clean: one source of truth, one path to recovery.
Snapshots shift the burden. You need snapshot versioning. You need garbage collection for old snapshots. You need to validate snapshot integrity. You need to decide snapshot frequency, too often and you waste storage, too rarely and your replays take too long. The article’s shopping cart example shows how a simple model evolution becomes a major decision: do you add a new read model or update the existing one? With snapshots, that decision compounds.
The concurrency management alone is a full-time job. The research shows how PostgreSQL advisory locks work:
-- Shared lock for inline projections
SELECT pg_try_advisory_xact_lock_shared(
('x' || substr(md5(?), 1, 16))::bit(64)::bigint
) AS acquired;
-- Exclusive lock for rebuilds
SELECT pg_try_advisory_lock(
('x' || substr(md5(?), 1, 16))::bit(64)::bigint
) AS acquired;
But this is just the tip of the iceberg. You also need to manage the status table:
CREATE TABLE IF NOT EXISTS emt_projections(
version INT NOT NULL DEFAULT 1,
type VARCHAR(1) NOT NULL,
name TEXT NOT NULL,
partition TEXT NOT NULL DEFAULT 'emt:default',
kind TEXT NOT NULL,
status TEXT NOT NULL,
definition JSONB NOT NULL DEFAULT '{}'::jsonb,
PRIMARY KEY (name, partition, version)
) PARTITION BY LIST (partition);
Now you’re maintaining a metadata table, managing partitions, handling hash collisions, and coordinating distributed locks. Your “simple” snapshot strategy has become a distributed systems problem.
Performance: The Numbers That Matter
Let’s get concrete. The event-driven.io benchmarks show that advisory lock checks cost microseconds. That’s negligible for low-throughput systems. But if you’re processing 10,000 events per second, those microseconds add up to 10 seconds of overhead per second of processing. Your throughput drops by an order of magnitude.
Replay performance depends on event size and projection complexity. A simple counter projection might process 10,000 events per second. A complex aggregation with multiple lookups might manage 500. Now multiply by your event count. A system with 100 million events and complex projections could take days to rebuild.
Snapshot performance depends on snapshot frequency and size. A 10GB snapshot taken every hour means 240GB per day in snapshots alone. But restoring that snapshot plus replaying an hour of events might take minutes instead of days. The trade-off is clear: storage and complexity versus time.
The Hybrid Reality
After analyzing the research, the conclusion is inescapable: pure approaches fail in production. The event-driven.io article advocates for a hybrid model that combines the best of both worlds while acknowledging the complexity.
Their approach uses:
1. Advisory locks for fast-path coordination (microsecond overhead)
2. Persistent status columns for crash recovery
3. Checkpoint tracking for resumable replays
4. Blue/green deployments for zero-downtime switches
The workflow is sophisticated:
– Rebuilds acquire exclusive locks and set status to ‘rebuilding’
– Inline projections check both lock and status before processing
– If a rebuild crashes, status remains ‘rebuilding’, preventing inline processing
– Multiple async processors compete for exclusive locks, ensuring single-writer semantics
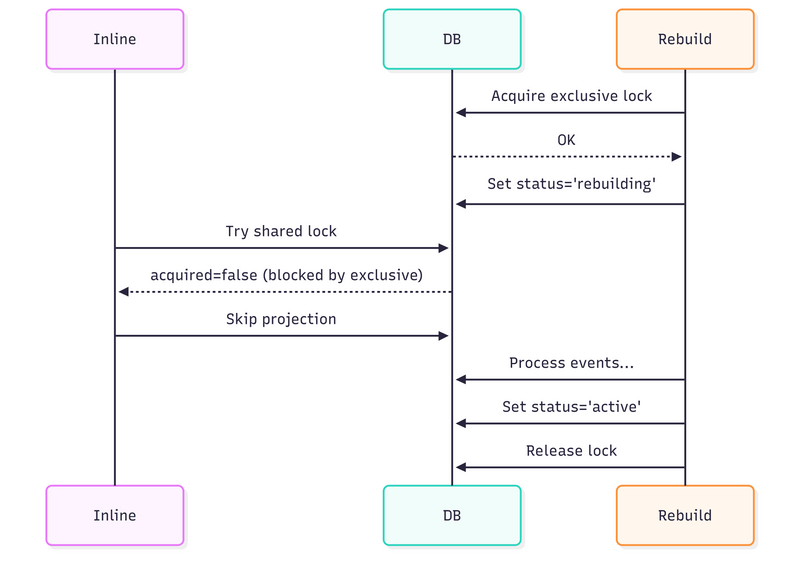
This gives you the integrity of replay with the performance benefits of incremental processing. But it requires understanding distributed locking, PostgreSQL internals, and eventual consistency semantics.
Making the Choice: A Decision Framework
Based on the technical deep dive, here’s when to choose each approach:
Choose Event Replay if:
– Your event volume is manageable (<10 million events)
– You have maintenance windows for rebuilds
– Consistency is more critical than availability
– Your team is small and prefers operational simplicity
– You’re using PostgreSQL and can implement advisory locking
Choose Snapshots if:
– Your event volume is massive (>100 million events)
– You need sub-minute recovery times
– You have the engineering capacity to manage distributed coordination
– You can tolerate snapshot versioning complexity
– You’re prepared to implement the hybrid locking approach from the research
Choose the Hybrid Approach if:
– You’re building a system that will grow significantly
– You need both performance and consistency guarantees
– You have PostgreSQL expertise on the team
– You’re prepared to maintain the operational overhead
The research makes one thing clear: there’s no free lunch. The event-driven.io article concludes that “designing robust, fault-tolerant and performant distributed systems is not that easy.” The cost on the hot path is microseconds per event, but the cost of getting it wrong is corrupted state and system downtime.
The Bottom Line
Event replay gives you correctness at the cost of time. Snapshots give you speed at the cost of complexity. The hybrid approach gives you both, but at the cost of engineering effort and operational sophistication.
The most controversial insight from the research isn’t technical, it’s organizational. The article’s author notes that “optimising for the end storage until we check that it’s too big isn’t a good driver.” In other words, premature optimization leads to unnecessary complexity. Start with replay. When it hurts, add snapshots. When that breaks, implement hybrid locking.
Your read model bootstrapping strategy isn’t just a technical decision. It’s a reflection of your team’s capabilities, your system’s scale, and your tolerance for operational pain. Choose wisely, because changing this decision after you have millions of events is like trying to change the foundation of a skyscraper while people are living in it.
The real trade-off isn’t between replay and snapshots. It’s between simple-and-slow and complex-and-fast. And only your production metrics can tell you which side of that trade-off your system actually needs.
Resources for deeper exploration:
– Rebuilding Event-Driven Read Models in a safe and resilient way
– Distributed Locking: A Practical Guide
– Emmett’s implementation of hybrid locking
– Checkpointing strategies for message processing