
We spent over a trillion dollars building artificial intelligence that can write poetry, debug code, and pass bar exams. The secret ingredient? A decade-old comment from u/ShowerThoughts about why the McRib is actually a seasonal product.
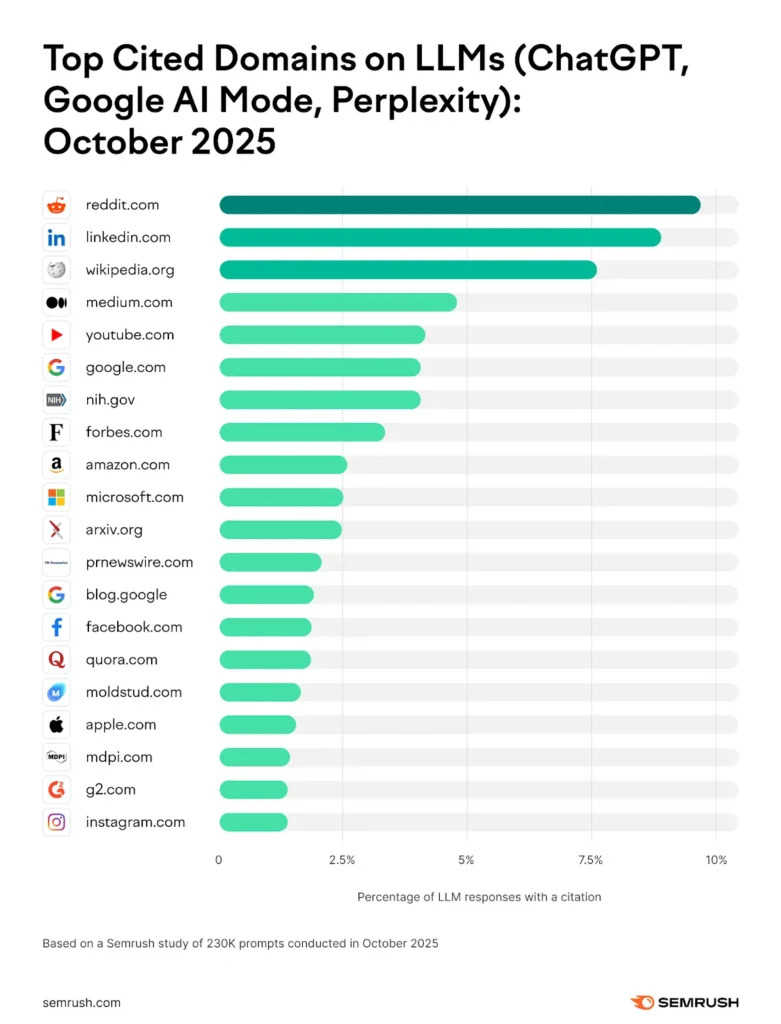
The punchline isn’t just darkly funny, it’s a structural reality of how modern AI works. Recent analyses show Reddit has become the most-cited domain in AI-generated responses across millions of prompts, with Google’s AI Overviews and ChatGPT regularly pulling from threads that range from life-changing technical solutions to heated debates about whether a hot dog is a sandwich. While OpenAI burned through compute budgets and Microsoft built planet-scale data centers, Reddit simply kept the servers running and watched its stock price quadruple.
The Numbers Behind the Absurdity
The financial metrics tell a story that venture capitalists are still trying to process. Reddit’s stock hit $257 in January 2026, up 400% since its IPO. Analysts are now projecting $320 per share, another 30% climb from current levels. The driver isn’t some breakthrough algorithm or exclusive content deal, it’s the raw, unfiltered chaos of human conversation.
Google pays Reddit $60 million annually for training data access. OpenAI has a similar arrangement. In 2025, Reddit pulled in $1.3 billion in revenue, with AI licensing agreements representing a growing slice of that pie. The platform now sees 3.4 billion monthly visits, up from 500 million in just one year, driven largely by AI models citing Reddit threads that then rank in search results.
The Quality Paradox: When “Authentic” Means “Unreliable”
Here’s where the technical debt becomes visible. Reddit’s value proposition to AI companies is precisely what makes it dangerous: unmoderated, karma-driven content where truth and popularity are often inversely correlated.
One developer noted the triangulation problem: “I usually shrugged it off but thinking the AI is gonna pick the obvious karma-farmer over information with citations is scary.” The mechanism is straightforward, presumed teenagers claiming to be evolutionary biologists can get more upvotes than actual experts posting peer-reviewed studies, because they’re telling the crowd what it wants to hear.
The Architecture of Accidental Value Extraction
From a data engineering perspective, Reddit’s transformation into AI infrastructure is fascinating because it was entirely accidental. The platform wasn’t designed as a knowledge base, it was designed as a content aggregator with threaded comments. The technical architecture that makes it valuable to AI emerged organically:
- Temporal clustering: Solutions to specific problems often appear in concentrated time windows (e.g., a bug fix gets posted within hours of a software release)
- Voting as quality signal: Despite manipulation risks, upvotes provide a crude but scalable relevance metric
- Natural language diversity: The same problem gets described hundreds of different ways, training models on linguistic variation
- Explicit attribution: Usernames and post histories create pseudo-authority trails that models can trace
This is why AI companies aren’t just scraping the content, they’re paying for API access that includes metadata about user karma, comment threads, and voting patterns. The $60 million isn’t for the text, it’s for the social graph that makes the text intelligible to machines.
The Poisoning Problem Nobody Wants to Solve
The elephant in the server room is data integrity. Reddit’s own users are increasingly aware that their content is AI training fuel, and some are actively trying to break the models.
Consider the moderation challenge: If 90% of Reddit content becomes AI-generated (as some community members claim is already happening), then AI models are training on synthetic data that was itself generated by AI. This creates a regressive data loop where each generation of models becomes slightly more detached from ground truth.
Legal and Ethical Quicksand
The compensation question is where this gets legally spicy. Reddit’s licensing deals compensate shareholders, but not the individual users whose comments form the training corpus. This creates a novel IP problem: when u/Throwaway2020 explains how to fix a Kubernetes cluster in 2018, does that comment belong to Reddit, to the user, or to the AI company that turns it into a revenue-generating answer?
Recent court cases suggest copyright law wasn’t built for this scenario. The “AI training data” defense, that scraping public comments is fair use, collides with the reality that these comments are being packaged and sold as premium products. When Google charges enterprises for Gemini access that regurgitates Reddit wisdom, the line between aggregation and exploitation gets blurry.
Some users are already testing legal theories. The “Mark Zuckerberg rat penis transplant” meme wasn’t just a joke, it was a coordinated attempt to create a false fact pattern that would demonstrate how easily AI systems can be manipulated. If models start citing that Zuckerberg had experimental rodent surgery, who bears liability: the pranksters, Reddit, or the AI company?
What This Means for Engineering Leaders
For engineering managers and architects, this isn’t just a curiosity, it’s a supply chain risk. If your team uses AI coding assistants that learned from Stack Overflow and Reddit, you’re betting your production systems on the accuracy of crowd-sourced solutions that were never audited.
The technical debt manifests in subtle ways:
– Version drift: AI suggests a Docker configuration from a 2019 thread that has known vulnerabilities
– Context blindness: Models recommend solutions that work in development but fail at enterprise scale
– Attribution failure: When AI code causes outages, tracing the original (flawed) advice becomes impossible
Smart teams are treating AI suggestions like any other third-party dependency, requiring review, testing, and provenance tracking. Some are even building internal “citation cores” that whitelist only vetted sources, effectively creating a private knowledge graph that excludes the wild west of public forums.
The Inevitable Reckoning
The current trajectory is unsustainable. We’re watching a trillion-dollar industry build its foundation on a platform that was designed for entertainment, not accuracy. Three forces will force a reckoning:
- Quality collapse: As Reddit becomes more AI-poisoned, model performance will degrade in measurable ways
- Legal pressure: User lawsuits and regulatory action will challenge the “fair use” defense for commercial AI training
- Economic reality: At some point, the cost of filtering bad data will exceed the value of the good data
The solution isn’t obvious. Building curated knowledge bases is expensive and slow. Wikipedia’s model works for facts but fails for troubleshooting. Corporate documentation is reliable but incomplete. The authentic, messy, human conversation that Reddit captures is genuinely valuable, it’s just not designed for the role it’s now playing.
Actionable Intelligence for AI Practitioners
If you’re building AI systems or using them in production, you need defensive strategies:
For model developers: Implement provenance tracking that tags training data sources by reliability tier. Treat Reddit content as “unverified” and require higher confidence thresholds before citing it.
For enterprise users: Demand transparency from AI vendors about their data sources. If a model can’t explain why it’s citing a Reddit thread, treat the suggestion as suspect.
For content creators: Understand that your Stack Overflow answers and Reddit comments are now intellectual property assets. Consider licensing them explicitly, or moving valuable content to platforms that compensate contributors.
For investors: The $60 million Reddit-Google deal is a floor, not a ceiling. As AI models compete on accuracy, the value of high-quality, verified community content will skyrocket.

The New Search Reality
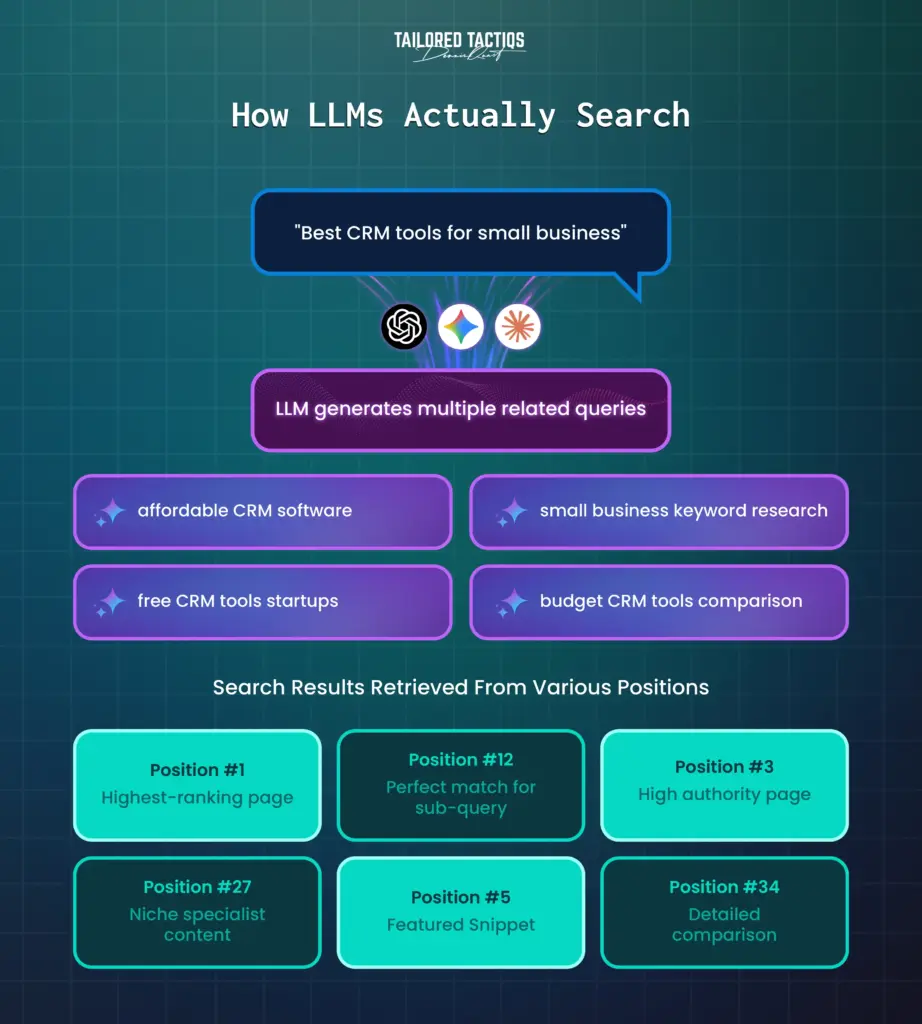
Traditional SEO metrics are becoming obsolete. A 2025 Semrush study found that nearly 90% of ChatGPT’s citations come from pages ranked beyond position 20 in Google results. The AI doesn’t care about your backlinks or domain authority, it cares about whether your content answers the specific question it’s trying to solve.
This is why a detailed guide on “disavowing toxic backlinks after a manual penalty” can outrank generic SEO content, even if it lives on page three of Google. The LLM optimization playbook is clear: answer first, structure for machine readability, and build topical authority through clusters of related content.
But here’s the spicy part: this same logic applies to Reddit threads. A niche subreddit with 500 members can produce a troubleshooting thread that becomes the definitive AI answer for a specific error code. The community’s collective expertise, captured in raw conversational format, beats polished corporate documentation every time.
Final Synthesis: What We’ve Built
The trillion-dollar irony is this: we built AI to automate human knowledge work, and its most valuable function is finding and synthesizing what humans already said. The “biggest innovation of the AI era” isn’t the transformer architecture or the trillion-parameter model, it’s the retrieval system that can surface a 2015 Reddit comment about a Kubernetes bug at the exact moment a developer needs it.
This creates a power dynamic that should make everyone uncomfortable. Reddit’s moderators, unpaid volunteers, are now curating training data for systems that will eventually compete with their day jobs. The karma farmers and trolls are poisoning the well that everyone drinks from. And the users asking honest questions are unknowingly creating the intellectual property that powers a new generation of AI.
The controversy isn’t that AI uses Reddit. It’s that we’ve built a knowledge economy where the people who create value get nothing, the platform that hosts it gets $60 million, and the AI companies that package it get billions in enterprise contracts. Until that equation changes, we’re not just training AI on Reddit, we’re training it on the worst aspects of how the internet values human expertise.
The question isn’t whether this model works. The question is how long we can afford the technical debt, legal risk, and ethical compromise it represents. And whether, when the bubble finally bursts, we’ll still remember how to have authentic conversations without an AI watching over our shoulder, taking notes for its next answer.



