The Announcement That Broke r/LocalLLaMA
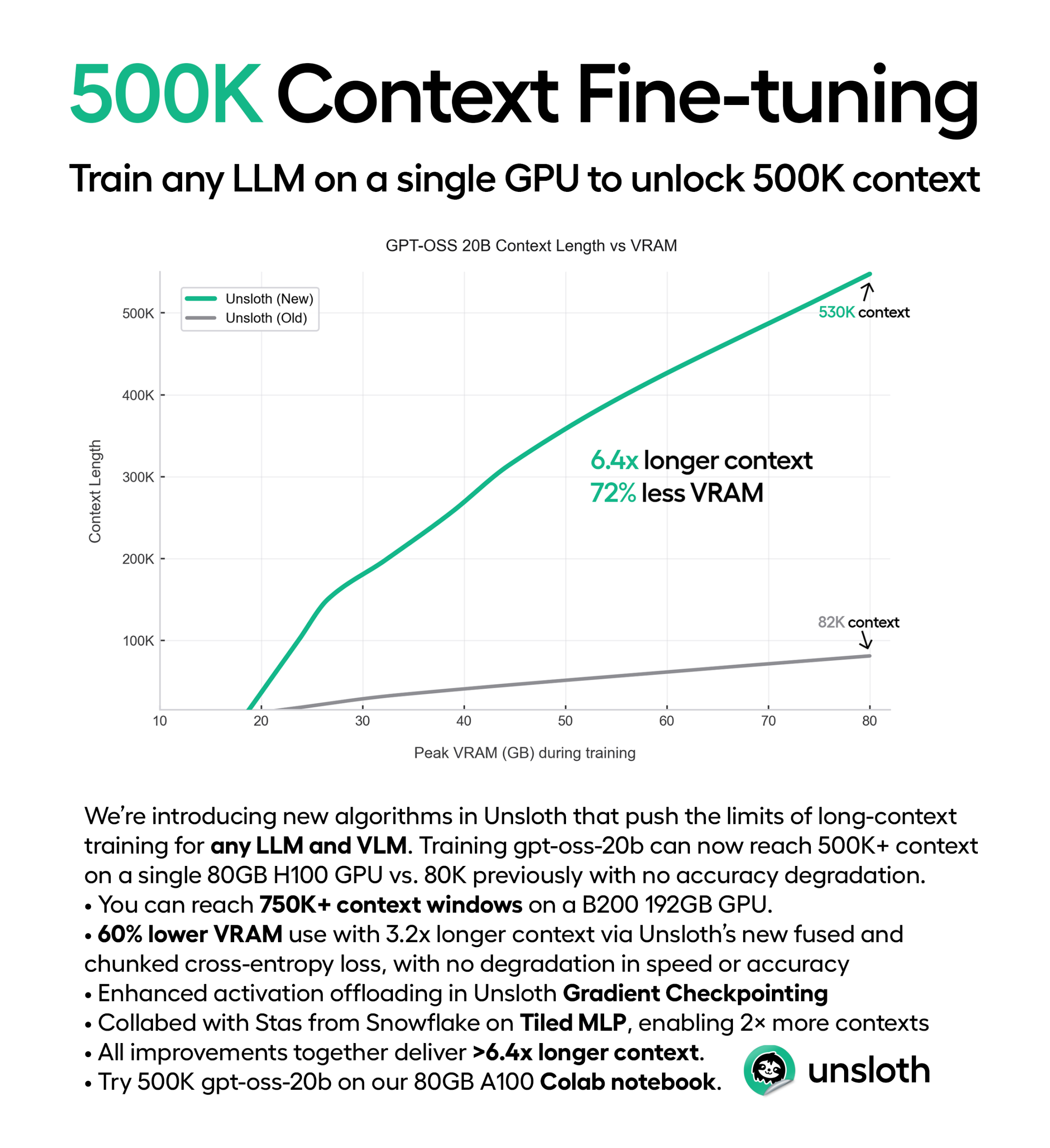
When Daniel Han Chen dropped his reddit post last week, the numbers seemed absurd: 530K context length on a single 80GB H100. Push it to 192GB VRAM and you’re looking at 750K+ tokens. For context, that’s roughly 1,500 pages of dense text, enough to fit the entire Lord of the Rings trilogy with room to spare.
The community’s reaction was immediate and divided. One top comment put it bluntly: “Without your work, small-budget training would be 2 years behind.” Another was more skeptical: “The gotcha is, it’s not actual usable context.”
Both are right. And that’s what makes this development genuinely interesting, not the headline numbers, but the messy reality they represent.
How Unsloth Pulled Off the Impossible
The technical architecture behind this leap isn’t one breakthrough but three complementary optimizations working in concert:
1. Fused and Chunked Cross-Entropy Loss
Instead of computing logits and cross-entropy over the entire sequence at once (the standard approach that blows up VRAM), Unsloth processes the sequence in dynamically-sized chunks. The chunk size is chosen automatically at runtime based on available VRAM, more memory means larger chunks for speed, less memory means more chunks to avoid OOM errors.
The result? 72% lower VRAM usage with 3.2x longer context on an 80GB H100, with no degradation in speed or accuracy. For GPT-OSS-20B QLoRA (4-bit), that means jumping from 82K to 290K context length before even touching the other optimizations.
# The key innovation happens under the hood, but you enable it by:
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/gpt-oss-20b",
max_seq_length = 530000, # Previously impossible on 80GB
load_in_4bit = True,
)
2. Enhanced Gradient Checkpointing with CUDA Streams
Unsloth’s gradient checkpointing, first introduced in April 2024 and now industry-standard, offloads activations to CPU RAM. The new enhancement uses CUDA Streams to add at most 0.1% training overhead (down from 1-3%), with zero accuracy impact.
Here’s what that looks like in practice:
# Original Unsloth implementation from April 2024
class Unsloth_Offloaded_Gradient_Checkpointer(torch.autograd.Function):
@staticmethod
def forward(ctx, forward_function, hidden_states, *args):
ctx.device = hidden_states.device
# Offload to CPU immediately
saved_hidden_states = hidden_states.to("cpu", non_blocking=True)
with torch.no_grad():
output = forward_function(hidden_states, *args)
ctx.save_for_backward(saved_hidden_states)
ctx.forward_function, ctx.args = forward_function, args
return output
By offloading activations as soon as they’re produced, peak activation footprint drops dramatically. In long-context training, a single decoder layer’s activations can exceed 2GB, this optimization makes that manageable.
3. Tiled MLP: The Snowflake Collaboration
Working with Stas Bekman from Snowflake, Unsloth integrated Tiled MLP from the Arctic Long Sequence Training paper. This tiles hidden states along the sequence dimension before heavy MLP projections, reducing activation memory at the cost of extra forward passes.
The trade-off: Tiled MLP performs ~3 forward passes and 1 backward pass per step (vs. 2 forward + 1 backward for standard checkpointing), but saves nearly all intermediate MLP activations from VRAM. The result is ~40% lower VRAM usage, though with a ~1.3x increase in step time.
# Enable Tiled MLP with one parameter:
model, tokenizer = FastLanguageModel.from_pretrained(
...,
unsloth_tiled_mlp = True, # Unlocks 500K+ context
)
Combined, these three optimizations deliver >6.4x longer context lengths on the same hardware.
The Elephant in the Room: Does It Actually Work?
Here’s where the controversy gets spicy. The top skeptical comment on Reddit wasn’t about VRAM usage, it was about quality at extended context:
“Go try any open source model claiming over 32k, try using the full context, your task gonna fail.” – mantafloppy
The community’s concern is legitimate. Long-context evaluation benchmarks like NoLiMa show that many models claiming 100K+ context windows start failing basic tasks beyond 32K tokens. The issue isn’t technical capacity, it’s training data distribution and architectural limitations.
Daniel’s response was refreshingly honest: “One will have to first train up the model to support longer context lengths.” In other words, the 750K context window is a capability, not a guarantee. You still need to fine-tune on long-context data to make the model actually use that capacity effectively.
What This Means Practically
The real breakthrough isn’t for end users, it’s for model builders. As one developer noted: “For larger models like gpt-oss-120b it can handle much longer context lengths than before when now it can be 4k or longer.” Before, you might hit OOM at 8K context during fine-tuning. Now you can push to 32K, 64K, or beyond on the same hardware.
The Qwen 2.5 3B RBI fine-tuning project demonstrates this perfectly. The author achieved 8.2x performance improvement (7% → 57.6% accuracy) using Unsloth’s memory optimizations to train on 47K QA pairs with just 8GB VRAM in 2 hours. That’s not using 500K context, but it’s enabled by the same efficiency breakthroughs.
The Democratization vs. Centralization Paradox
Perhaps the most controversial aspect is who this actually benefits. On the surface, enabling 500K context on consumer hardware seems like a massive win for democratization. And in some ways, it is:
- RTX 5090 can reach 200K context (per Unsloth’s claims)
- Single GPU fine-tuning eliminates the need for multi-GPU clusters
- Consumer hardware can now do what required data centers months ago
But there’s a catch. The models that benefit most from extreme context are the massive ones, think GPT-OSS-120B or Qwen-235B. These models still require significant VRAM just to load, even in 4-bit quantization. So while a hobbyist could theoretically fine-tune with 500K context, in practice you’re still looking at:
- H100 80GB for 20B+ parameter models
- B200 192GB to reach the full 750K context
- Enterprise-grade hardware for the models where extreme context actually matters
As one commenter noted: “Unsloth is really life-saver for people who don’t have a million B300s.” True, but you’re still going to need at least one very expensive GPU.
The VRAM vs. Utility Equation
Let’s get brutally practical. Here’s what the memory savings actually look like:
| Configuration | Original VRAM | With Unsloth | Context Length | Real-World Use |
|---|---|---|---|---|
| GPT-OSS-20B QLoRA | 80GB OOM | 24GB | 82K | Document QA |
| GPT-OSS-20B QLoRA | 80GB OOM | 80GB | 290K | Long RAG |
| GPT-OSS-20B QLoRA | 80GB OOM | 80GB | 530K+ | Theoretical max |
The question isn’t can you, it’s should you. For most applications, 32K context is sufficient. Pushing to 200K+ enters a realm of diminishing returns where:
- Data quality becomes the bottleneck, you need massive, high-quality long-context datasets
- Training time increases, even with 0.1% overhead, you’re still processing 6x more tokens
- Evaluation complexity explodes, how do you reliably test 500K context models?
The Path Forward: Smarter, Not Just Longer
The most interesting implication of Unsloth’s breakthrough isn’t the raw context number, it’s the enabling of new training paradigms. With dynamic chunking and automatic VRAM management, we can now explore:
- Curriculum learning that gradually increases context length during training
- Multi-document RAG where the model sees entire corpora at once
- Agentic memory that persists across thousands of interaction turns
- Synthetic data generation with full-context awareness
But this requires a fundamental shift in how we think about long-context modeling. As Daniel himself noted: “For small models using dynamic yarn would help where there is no context degradation for short lengths.” The future isn’t just longer, it’s adaptive context that scales intelligently based on the task.
The Bottom Line
Unsloth’s 500K context breakthrough is simultaneously:
- Technically legitimate: The VRAM savings are real, the code is open-source, and the math checks out
- Practically limited: Most models can’t effectively use that context without extensive fine-tuning
- Democratic in theory: Consumer GPUs get a massive capability boost
- Elite in practice: The hardware requirements for meaningful use cases remain steep
The real story here isn’t the headline number. It’s that we’ve finally decoupled context capacity from hardware requirements. Whether you’re fine-tuning a 3B model on an RTX 3090 or pushing a 120B model to its limits on an H100, you can now choose your context length based on task requirements rather than VRAM constraints.
That’s not a revolution, it’s the foundation for the next wave of LLM capabilities. The question now isn’t “how long can we go?” but “what can we build when VRAM is no longer the bottleneck?”
Try it yourself: The 500K context Colab notebook runs on free A100 instances. See what breaks. That’s where the real innovation begins.