The Llama 3.1 8B Monopoly: Why AI Progress Has Stalled
In the breakneck world of AI research, where new “revolutionary” models drop faster than startup valuations, one relic from 2023 stubbornly refuses to go away: Llama 3.1 8B. While researchers chase the next big thing, agentic reasoning, multimodality, and trillion-parameter behemoths, the finetuning community remains stuck on Meta’s two-year-old workhorse.
The irony is palpable. We’ve seen OpenAI’s GPT-4o, Google’s Gemini 2.0 Flash, and countless open-weight challengers, yet when developers need a reliable base for specialized tasks, they reach for the same old Llama. The research understands why, reproducibility, familiarity, and surprisingly effective architecture, but the implications for innovation are troubling.
The Lab Rat Problem: Why Llama 3.1 Won’t Die
Developers don’t stick with legacy tech because they’re nostalgic, they do it because it works. As one researcher put it, Llama 3.1 8B has become the “standard lab rat” of the AI community. When every paper compares against the same baseline, you create a self-perpetuating ecosystem where familiarity trumps performance.
The model’s unexpected durability stems from Meta’s training approach. When they trained Llama-3, they started by training the 405B parameter version on fifteen trillion tokens, then distilled the 70B and 8B models from that. This meant their training tokens to parameter ratio was only about 37:1, marginally above the Chinchilla threshold.
The result, as research has shown, was a model with extensive memorized knowledge but relatively weak generalized reasoning capabilities. Ironically, this makes it an excellent candidate for continued training, where fine-tuning can cannibalize the memorized parameters and replace them with targeted knowledge for specific use cases.
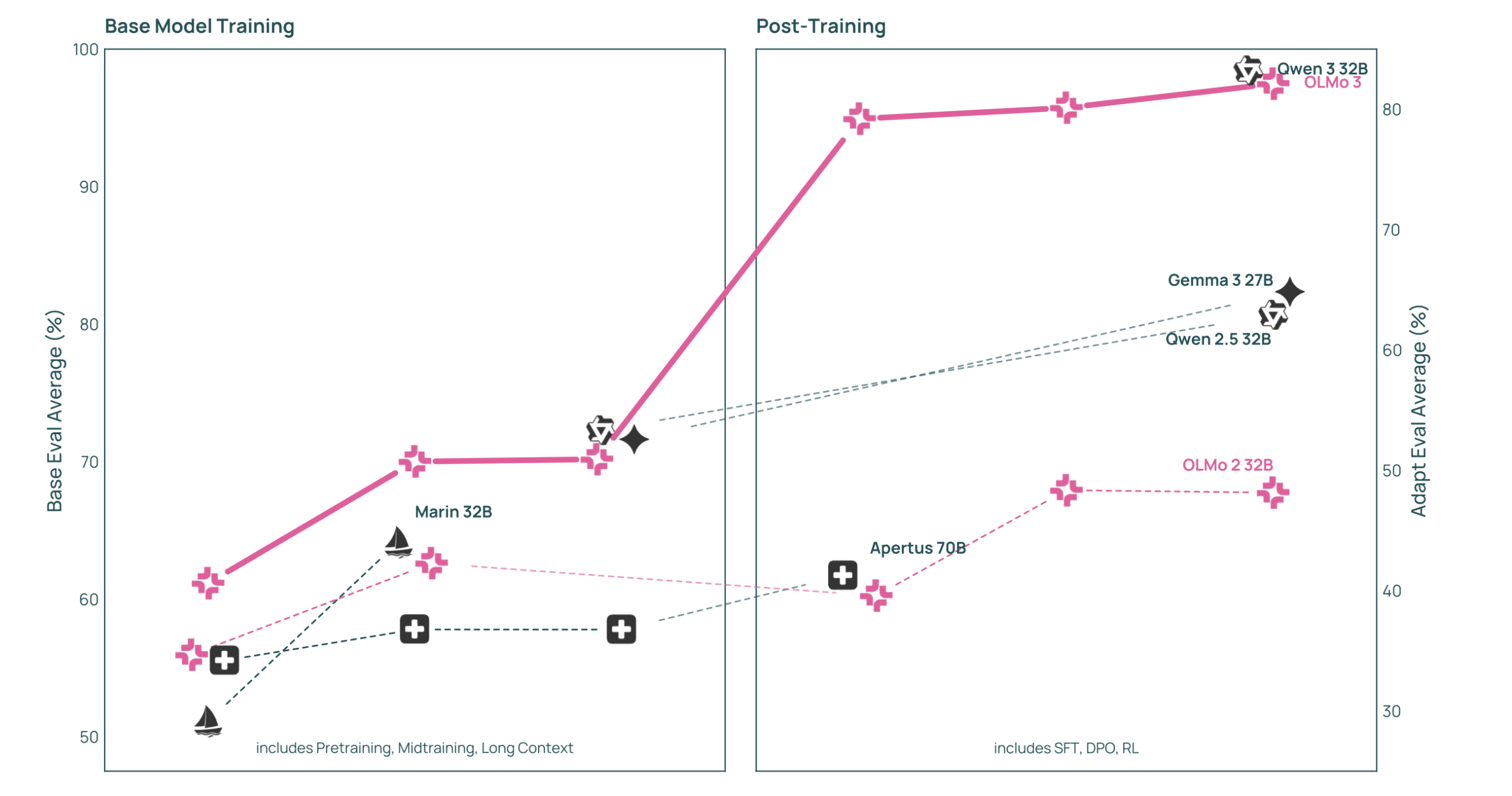
OLMo 3: The Challenger Arrives
Enter AI2’s OLMo 3, which openly declares war on the status quo. The team claims OLMo 3-Instruct “performs better than Qwen 2.5, Gemma 3 and Llama 3.1”, a direct shot across Meta’s bow. More importantly, OLMo 3-Think 32B narrows “the gap to the best open-weight models of similar scale, such as the Qwen-3-32B thinking models on our suite of reasoning benchmarks, while being trained on six times fewer tokens.”
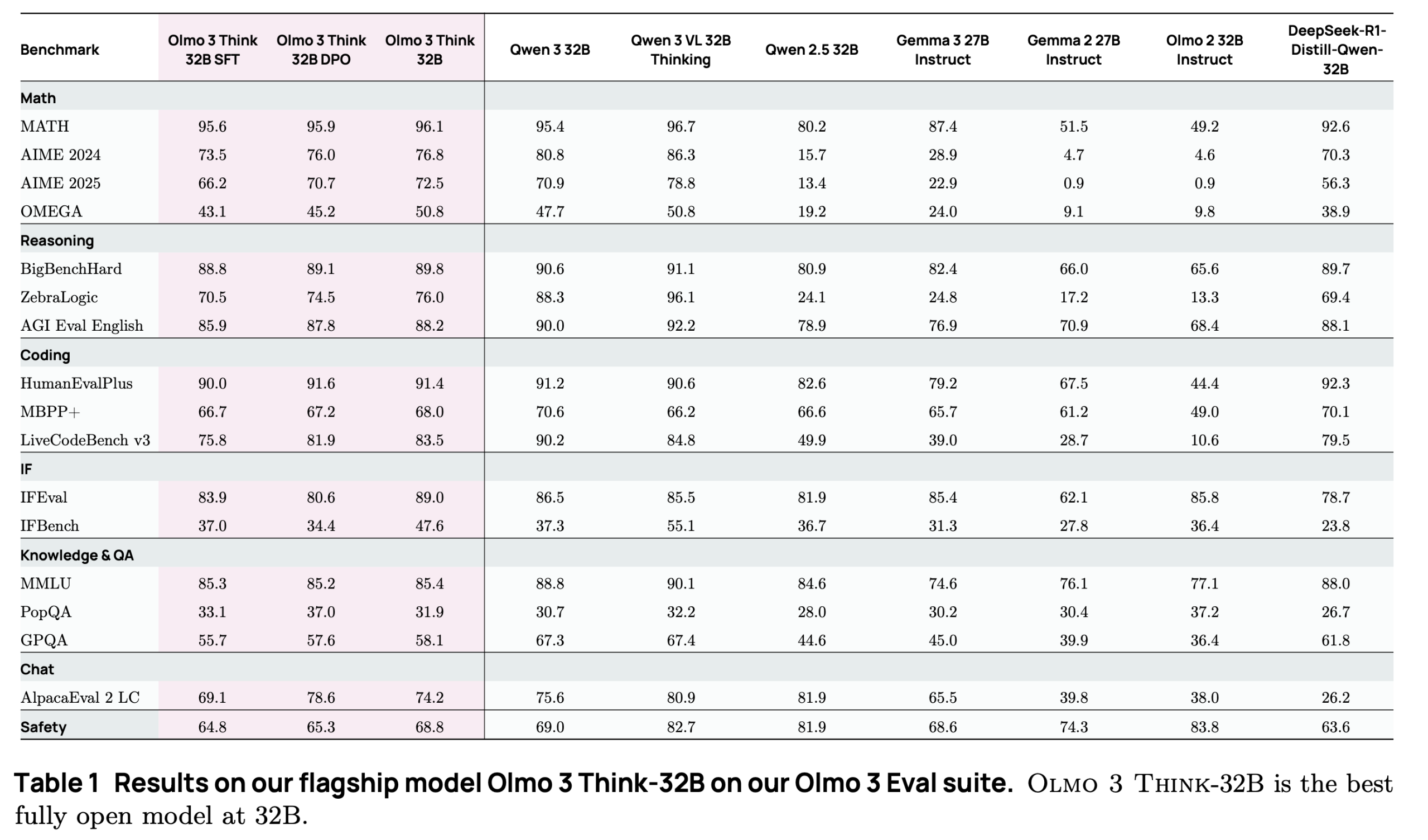
The performance numbers are compelling, but the community adoption tells a different story. While developers acknowledge OLMo’s technical superiority, many echo the sentiment that “Olmo3 7B needs more community bake time” before it can dethrone the incumbent.
The practical concerns are real. Some developers report that “Olmo 3 uses vastly more memory in comparison to Llama 3.1 so it’ll be more expensive to finetune.” Others question its multilingual capabilities compared to Llama’s more established training corpus.
The Architecture Advantage Nobody Saw Coming
What makes Llama 3.1 8B so resilient isn’t just its performance, it’s its architecture. The model’s design has become the de facto standard for the entire open-weight ecosystem. Tooling, optimization frameworks, and deployment pipelines are all built around Llama’s architectural choices. Switching to a new base model means rebuilding your entire stack.
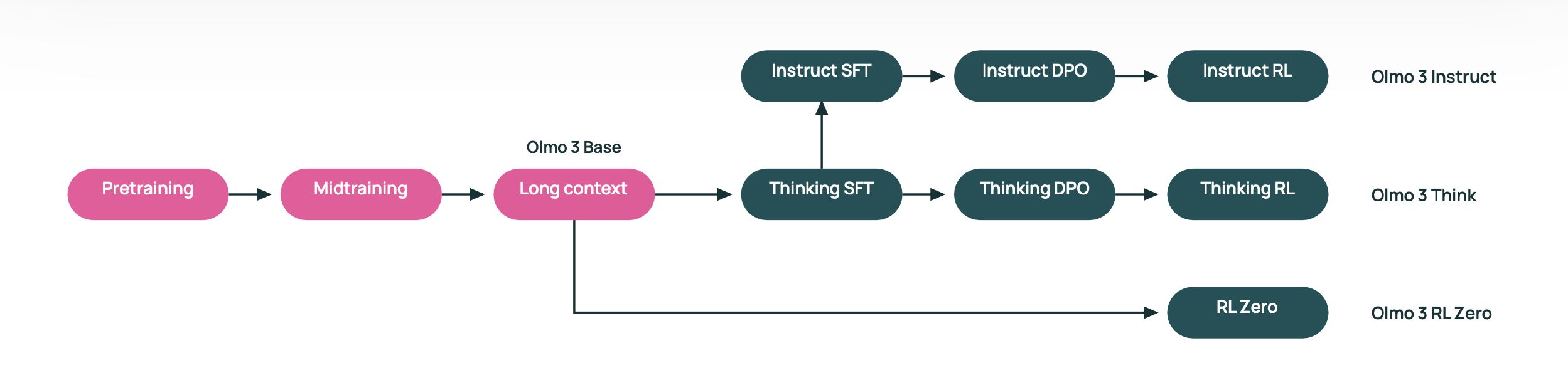
OLMo 3 attempts to counter this with superior transparency. Unlike Meta’s black-box approach, AI2 releases the complete “model flows”, every training stage, dataset, and recipe. As Hanna Hajishirzi, director of AI at AI2, explains: “This whole model development is something we are calling ‘model flows,’ and all of them are so important to be shared because they enable infinite customization for the developers to take different pieces and different stages of the model development and then build their own model.”
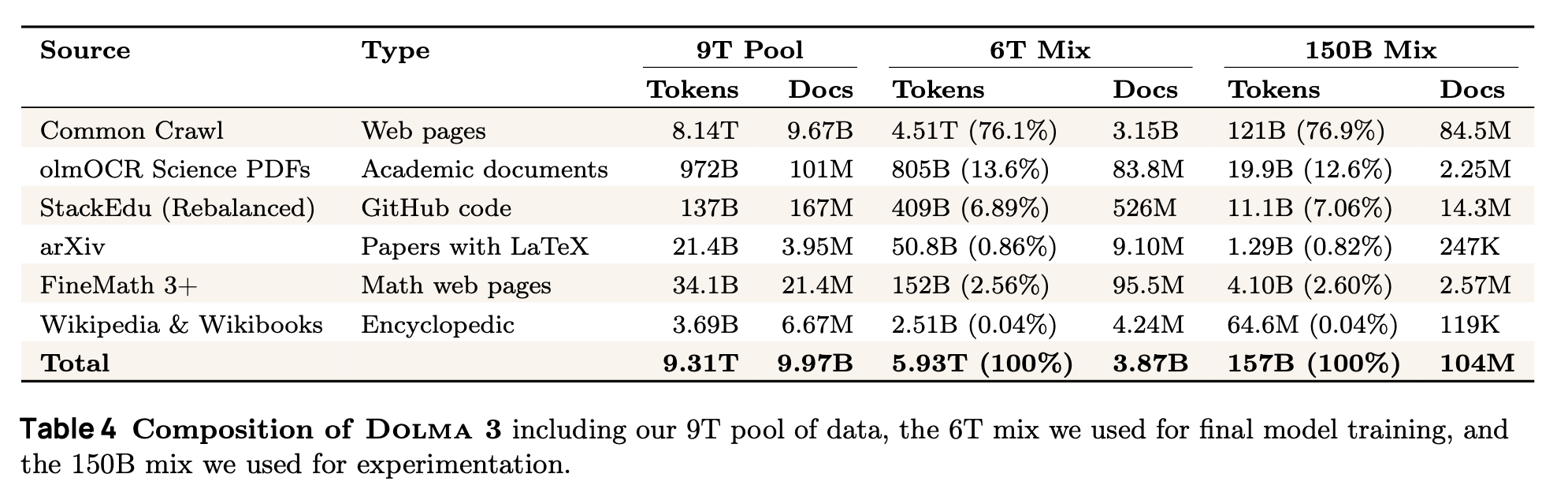
The transparency extends to data curation. OLMo 3 uses the Dolma 3 pre-training datasets from Common Crawl, GitHub code, scientific papers, Wikipedia, and math web pages, all with extensive filtering and processing tooling that helps developers understand what actually improves model performance.
The Western Choice Problem
Another factor keeping Llama dominant: the scarcity of alternatives. As one developer bluntly put it: “Good documentation, easy to finetune, comes in many base sizes, what other western open source LLM can they choose? Mistral? That’s it, maybe Gemma.”
The geopolitics of AI model development matter more than we acknowledge. While Chinese models like Qwen show impressive performance, many organizations prefer “Western-made” models for compliance and security reasons. This creates an artificial constraint that benefits incumbents like Meta.
Google’s Gemma represents the other major Western alternative, but as developers note, “Gemma 2 9B is more the lab rat of the family” than the newer Gemma 3, which has “weird enough model in certain ways” that makes it less suitable for widespread adoption.
Memory Matters More Than Metrics
Benchmark performance tells only part of the story. The real battle happens in GPU memory and inference costs. Developers report that Qwen models “have too much knowledge baked in so don’t fine tune as well” as Llama 3.1, which appears to have found a sweet spot between general knowledge and adaptability.
The memory footprint difference between models often determines real-world deployment. One user noted that after fine-tuning Qwen2.5-7B on a math dataset, “it performed worse compared to a finetuned llama3.1-8b”, suggesting that raw performance numbers don’t translate directly to fine-tuning effectiveness.
Where the Stakes Get Real
This isn’t just academic squabbling, the Llama monopoly has real consequences for AI progress. When every research paper uses the same baseline model, innovation becomes incremental rather than transformative. We optimize for compatibility rather than capability.
The ecosystem effect creates powerful lock-in. Companies building on Llama 3.1 have invested thousands of engineering hours in tooling, optimization, and deployment pipelines. Switching costs become prohibitive, even when technically superior alternatives emerge.
OLMo 3’s approach, complete transparency, multiple training checkpoints, and open data, represents a fundamental challenge to this ecosystem. As Pradeep Dasigi, senior research scientist at AI2, explains: “Because all the data recipes are open, if [developers] wanted to specialize it to a specific domain like biomedical engineering or something, they can always curate their own datasets. The reports that we released and the results associated with [them] will clearly tell them what worked and what did not.”
Beyond Benchmarks
The solution isn’t just building better models, it’s building better adoption pathways. OLMo 3 needs to become more than just a technical achievement, it needs to become the “new mouse in the lab” that researchers naturally reach for.
This requires addressing the practical concerns head-on: memory efficiency, documentation quality, and community tooling. It means creating bridges for developers to migrate their existing Llama-based workflows with minimal friction.
The real test will come in the next six months. If OLMo 3 can build the same ecosystem of fine-tuned variants, optimization tools, and deployment solutions that Llama enjoys, we might finally see the stagnation break. If not, we’ll be having this same conversation when Llama 4.0 drops, and the cycle will continue.
The open-weight AI revolution promised diversity and innovation. Two years into Llama 3.1’s reign, we’re seeing the opposite: consolidation around a single architecture. Breaking that pattern requires more than better benchmarks, it requires overcoming the inertia of an entire ecosystem built around yesterday’s technology.