The 2M-Page Elephant in the Room: What EpsteinFiles-RAG Reveals About AI’s Infrastructure Crisis
A developer’s open-source RAG pipeline processing 2M+ pages of the Epstein Files exposes the brutal reality of scaling retrieval systems: the demo is easy, but production is a nightmare of hidden costs, ethical landmines, and infrastructure complexity.
When a developer decided to build a RAG pipeline on 2 million pages of Epstein Files, they weren’t just creating another demo. They were stress-testing the entire open-source AI infrastructure stack in public, and the cracks are impossible to ignore. The project, EpsteinFiles-RAG, quickly gained 122 stars and sparked heated debates about everything from chunking strategies to whether certain datasets should even be indexed.
But here’s what makes this case study brutally relevant: it exposes the massive gap between “it works in Jupyter” and “it survives at scale.” The developer’s choice of a controversial dataset wasn’t just for shock value, it created the perfect playground for testing retrieval optimization under real-world conditions where every millisecond and every token matters.
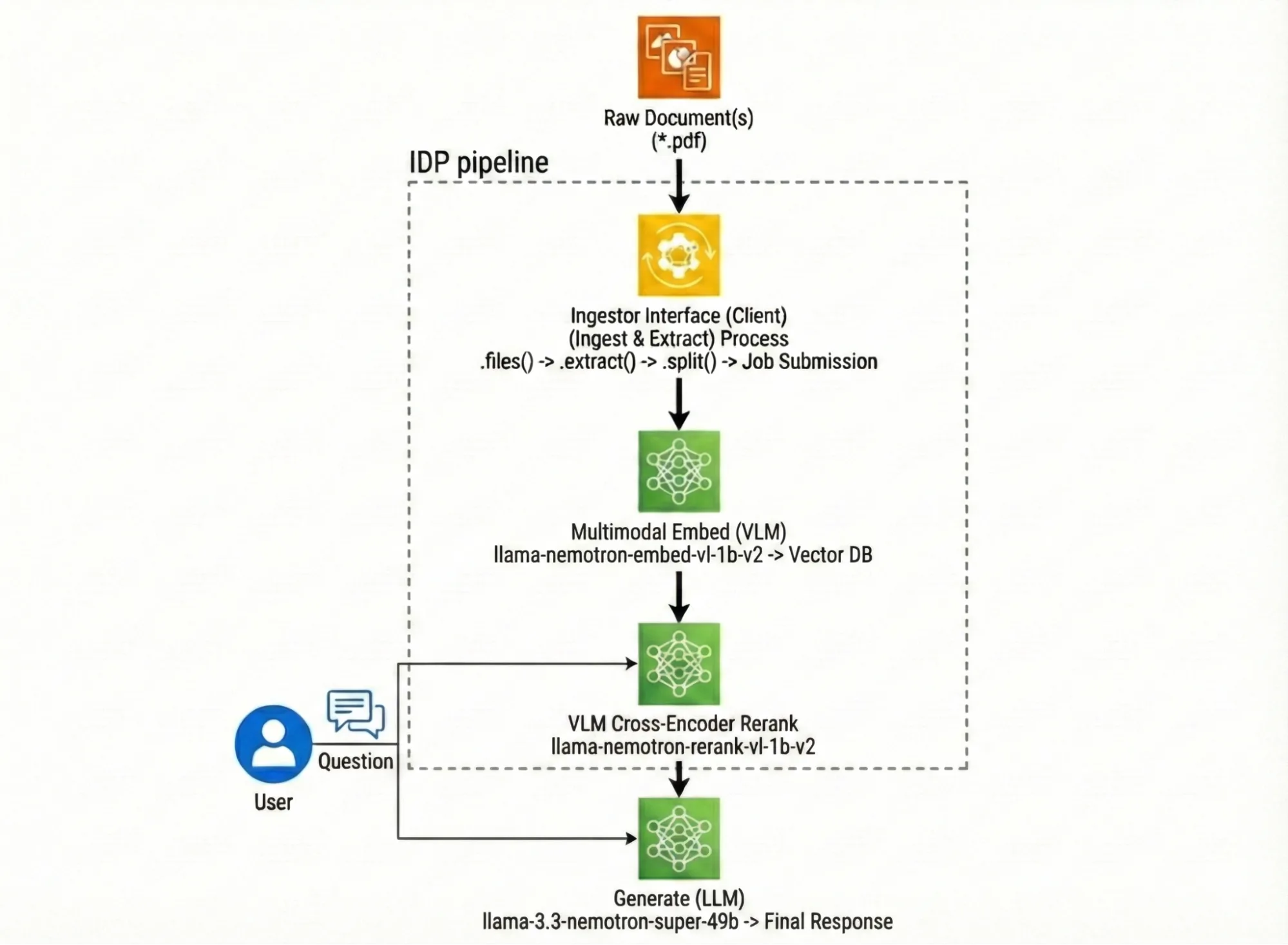
The Pipeline That Actually Survives 2M Documents
The architecture is deceptively simple on paper. Raw dataset → cleaning → semantic chunking → vector embeddings → ChromaDB → retrieval → LLM generation. But the devil lives in the implementation details that most tutorials conveniently skip.
The pipeline uses Sentence Transformers for embedding, LangChain for orchestration, and Groq’s LLaMA 3.3 (70B) for generation. But here’s the first reality check: the LLM is the bottleneck, not the vector search. As one developer who built a similar system found, vector search takes ~45ms while LLM generation consumes 2.3 seconds on average. The entire end-to-end latency hits 2.4 seconds at p50 and 4.3 seconds at p95.
The EpsteinFiles-RAG implementation deliberately restricts the LLM to retrieved context only, no hallucinations allowed. If the answer isn’t in the documents, it explicitly says so. This design choice, while seemingly conservative, actually amplifies the pressure on retrieval quality. When your generation model can’t freestyle, your retrieval has to be surgical.
The Hidden Infrastructure Iceberg
What the Reddit thread and Hacker News discussion reveal is that the real complexity lives below the waterline. The developer mentions “optimizing every layer to squeeze out better performance”, but the community immediately started asking about the 380GB of newer files that weren’t included. This highlights the first hidden cost: data versioning and ingestion at scale is a full-time job.
One commenter noted that most Epstein-related RAG projects are “utter garbage, just opportunists looking to get eyeballs.” The EpsteinFiles-RAG author defended their work, but the skepticism points to a deeper problem: RAG systems fail silently. Unlike traditional software where errors crash, RAG degradation looks like “the AI gave me a wrong answer” while all your infrastructure metrics look fine.

The Hybrid Search Reality Check
A similar Epstein search implementation discussed on Hacker News reveals the next level of complexity: pure vector search isn’t enough. That system uses PostgreSQL with pgvector and an HNSW index, but cranks ef_search to 400 (default is 40) because the default “misses too much.”
More importantly, it implements hybrid search: over-fetching 5x candidates from vector search while running parallel keyword search via GIN-indexed tsvector, with trigram ILIKE fallback. Results merge using slot reservation, 60% from vector, 40% reserved for keyword-only matches. This isn’t in the basic tutorials because it’s hard.
The cost? That system charges $0.50 per query via micropayments, explicitly stating “it’s not cheap to run these queries.” When you’re processing 2M+ pages, every optimization directly impacts your burn rate.
The Ethical Infrastructure Problem
Let’s address the elephant: using Epstein Files as a “playground” sparked immediate backlash. One commenter called it an “unfortunate choice of words”, and the developer jokingly blamed their AI. But this exposes a real infrastructure gap: we have no established patterns for ethical data sourcing in RAG.
The dataset was taken down from Hugging Face, forcing developers to hunt for mirrors. This creates a bizarre situation where the technical infrastructure for document processing is robust, but the governance infrastructure is non-existent. When the ICC defected from Microsoft to open-source infrastructure, it was about geopolitical pressure. Here, it’s about the morality of data itself.

What Production RAG Actually Costs
Based on performance data from similar-scale implementations, here’s the real monthly cost for processing ~10k queries on 50k documents:
OpenAI API (GPT-4 Turbo): $156
- Embedding (ada-002): $12
- Completion calls: $144
Pinecone: $70
Total Infrastructure: $226/month
Cost per query: ~$0.02The Open-Source Advantage (and Trap)
The project uses entirely open-source tooling: Python, LangChain, ChromaDB, Sentence Transformers, FastAPI. This aligns with the broader trend where open-source coding models are beating proprietary giants at their own game. The performance gap has vanished, and the cost advantage is substantial.
But the EpsteinFiles-RAG case reveals the trap: open-source tools give you freedom, but not freedom from complexity. The developer admits spending days on optimization. Community members point out that newer, larger datasets exist but lack model cards, making quality assessment impossible. You’re trading vendor lock-in for documentation holes and breaking changes between minor versions, as one developer discovered with LangChain’s abstraction hell.
Lessons for Building RAG at Scale
- Chunking strategy > model choice: The 512-token chunk with 50-token overlap isn’t arbitrary, it’s battle-tested. But different content needs different strategies. Technical docs need smaller chunks (200-300 tokens), while narrative content needs larger ones (800-1000). One size fits none.
- Reranking is non-negotiable: Vector search alone fails. The cross-encoder adds latency but prevents the “looks similar but wrong” problem. For 2M pages, you need this precision layer.
- Monitor retrieval quality, not just infrastructure: Set alerts for zero-result queries >5%, similarity score drops >20%, and cache hit rate drops >30%. Your logs will look fine while your system returns garbage.
- Hybrid search is mandatory at scale: Pure semantic search misses exact keyword matches. The slot reservation system (60% vector, 40% keyword) balances precision and recall.
- Cache intelligently or go bankrupt: Query embedding caching saves 50-200ms and real money. Result caching with document-level invalidation prevents reindexing nightmares.
- Ethical infrastructure needs standards: We need patterns for dataset provenance, usage auditing, and consent management. The current “download and embed” approach is unsustainable.
The Bottom Line
EpsteinFiles-RAG isn’t just a technical demo, it’s a mirror showing how unprepared our tooling is for real-world scale and complexity. The open-source stack works, but it demands expertise in chunking, reranking, caching, and monitoring that most teams don’t have. The controversy around the dataset is a feature, not a bug: it forces us to confront the ethical vacuum in our current AI development practices.
As Mistral’s recent releases show, open-weight models are reshaping the landscape. But models are just one piece. The EpsteinFiles-RAG case proves that the real moat isn’t the model, it’s the infrastructure to make retrieval work at scale.
The developer built this for optimization challenges, but accidentally created the perfect stress test. Every layer that breaks under 2M pages is a layer that would have failed silently in production. For AI enthusiasts and practitioners, the message is clear: stop obsessing over model parameters and start building retrieval infrastructure that doesn’t collapse when reality hits.
The question isn’t whether you can build a RAG pipeline. It’s whether you can keep it running when the data gets real, the queries get adversarial, and the ethical implications become impossible to ignore. That’s the infrastructure crisis EpsteinFiles-RAG just made impossible to avoid.