
The AI community has a word for models that release only their weights while keeping training data, code, and recipes locked away: “open-weight.” The rest of us just call them “open” because marketing teams prefer shorter adjectives. That imprecision works fine until someone actually opens everything, and you’re forced to admit your previous definition was a polite fiction.
AI2’s Olmo 3 is that uncomfortable reality check.
When “Open” Actually Means Open
Let’s cut through the euphemisms. Most “open” models in the wild are black boxes with a peephole. You get weights, maybe a sanitized technical report, and a model card that lists benchmarks like a restaurant menu. What you don’t get is the training data that shapes model behavior, the code that determined how it learned, or the checkpoints showing how capabilities emerged. For researchers trying to understand AI systems, or companies needing to verify what their models actually learned, that’s like getting a cake recipe that lists “flour, sugar, eggs” and tells you to figure out the rest.
Olmo 3 ships with the entire model flow: 6 trillion tokens of pretraining data, Dolma 3 Mix, post-training recipes (SFT → DPO → RLVR), and checkpoints from every major training milestone. You can trace a reasoning step back to its source data, replicate the training run, or fork the process at any stage to build your own variant. No NDA, no API agreement, no “contact us for enterprise access.”
The 32B Think model, the first fully open reasoning model at this scale, benchmarks at 96.1% on MATH and 91.4% on HumanEvalPlus, competitive with Qwen 3 32B and DeepSeek R1 Distill 32B. Here’s the kicker: it was trained on roughly 6x fewer tokens. Efficiency isn’t just a bragging right, it means researchers with limited compute can actually reproduce and extend the work.
The Benchmark Trap (And Why It Matters)
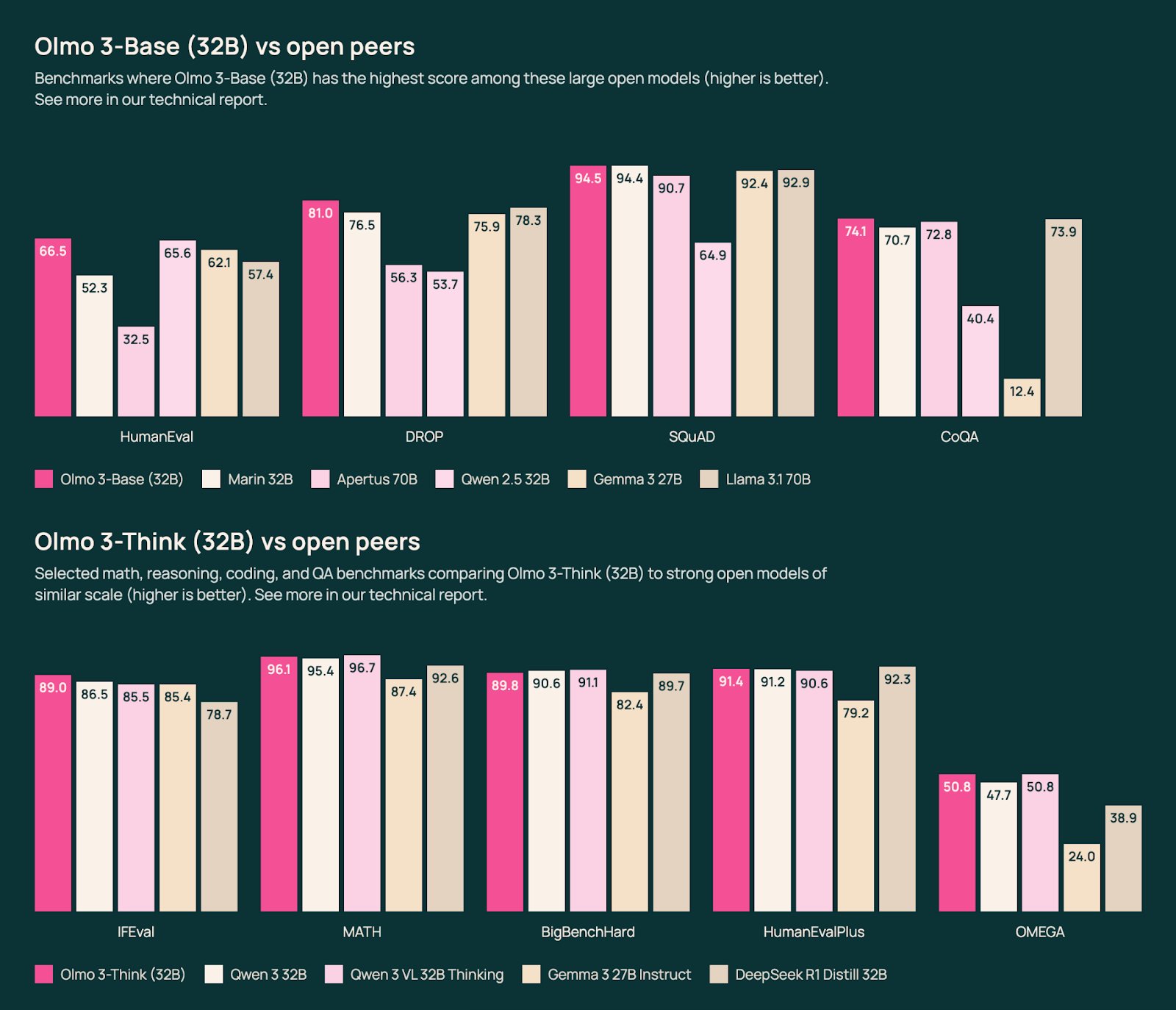
A Reddit comment in the launch thread captured the tension perfectly: “This Olmo model, by their own benchmarks in model card, loses to Qwen3 32B VL all across the board by significant amount. Why would I… want to choose it?” The top response reframed the question: “Because it’s different. Different models have different strengths… none of them are all-encompassing Generalist models like proprietary ones are.”
This exchange highlights a deeper issue with how we evaluate “progress.” We’ve become so benchmark-obsessed that we treat a 2-point difference on MMLU as meaningful while ignoring what transparency enables. A model you can audit, decontaminate for your use case, and fine-tune on a single GPU is fundamentally more valuable than a slightly higher-scoring black box, unless you’re just shipping a chatbot.
The Olmo 3 Instruct 7B variant illustrates this tradeoff. It scores 85.6% on IFEval, beating comparably-sized open-weight models, but its real value is the post-training pipeline you can replicate. For developers building specialized agents or researchers studying RLVR, access to the Dolci dataset suite and the full RL Zero path matters more than a leaderboard position.
The US-China AI Chess Game
Here’s where the story gets geopolitical, and genuinely controversial. The Decrypt article on the release framed it bluntly: “Two American AI Labs Released Open-Source Models This Week… Each Taking Dramatically Different Approaches.” While Deep Cognito released a 671B parameter model forked from DeepSeek V3 (a Chinese base model), AI2 built Olmo 3 from scratch with full US-based infrastructure.
The implications are stark. If American AI becomes dependent on Chinese base models, quietly, as many startups already do, it creates a supply chain vulnerability that makes the semiconductor conversation look simple. You can’t just spin up a new fab, you need the entire data pipeline, optimization techniques, and hardware coordination.
NSF and Nvidia clearly got the memo. Their $152 million investment in AI2 wasn’t for incremental improvements. It was a strategic bet that “open” means more than “downloadable from Hugging Face.” When Nvidia’s VP Kari Briski says these models “turn intelligence into America’s most renewable resource” she’s not talking about electricity.
Why Your Definition of “Usable” Is Wrong
Critics on Reddit argued open data is a liability because “you can’t put anything that people might actually want from the models in practice.” The author response was telling: “[we track things like] ability of model to follow instructions, respect constrain in prompts, and how it covers topics that people ask to chatbot by using WildChat logs.”
Translation: Real-world utility isn’t captured in benchmarks. A model that refuses harmful requests, follows complex multi-step instructions, and integrates with tools is more “usable” than one that scores 2 points higher on a sanitized test set. Olmo 3’s 65K context window (16x larger than its predecessor) means it can process entire codebases, legal contracts, or research papers, capabilities that matter for actual work.
The post-training pipeline reveals this philosophy. The RL Zero path, a pure reinforcement learning approach starting from the base model, produces four model variants trained on math, code, instruction-following, and general chat. This isn’t about chasing a single “best” model, it’s about giving researchers controlled experiments to understand how different training signals shape behavior.
The Community Laboratory Effect
Perhaps Olmo 3’s most radical aspect is how it transforms the AI community itself into a distributed research lab. When AI2 says “we invite the community to validate, critique, and extend our findings” they’re not just being polite. The entire model flow is designed for surgical intervention.
Want to test if removing certain web domains from Dolma 3 affects bias metrics? You can. Need to see how mid-training data mixing influences code generation? The checkpoints are there. Building a specialized legal reasoning model? Fork the Think variant at the SFT stage and inject your corpus.
This is the polar opposite of the API-as-a-service model. It’s AI development as open-source software, not AI consumption as SaaS. And for engineers and researchers who’ve watched the field consolidate behind a handful of corporate APIs, it feels like a return to first principles.
The Uncomfortable Truth About Transparency
Here’s what will actually determine Olmo 3’s impact: whether the market rewards transparency or punishes it. History suggests convenience usually wins. GitHub Copilot didn’t succeed because it was open, it succeeded because it was integrated. ChatGPT didn’t dominate because users could inspect its reasoning, it dominated because it was easy.
But the calculus changes when AI systems start making consequential decisions, medical diagnoses, loan approvals, legal analysis. In those domains, “trust me, it works” becomes a liability. The EU AI Act and similar regulations are already mandating documentation and auditability. When auditors show up, “we downloaded weights from Hugging Face and fine-tuned them” won’t cut it. You’ll need the data lineage, training procedures, and evaluation criteria Olmo 3 provides.
Final Frame: The Bluff Is Called
Olmo 3’s existence forces a reckoning. It proves that state-of-the-art performance doesn’t require proprietary opacity. It demonstrates that the US can build competitive AI without quietly forking Chinese models. And it shows that “open” can be more than a marketing prefix.
The question isn’t whether Olmo 3 will top every leaderboard. It’s whether we’ll finally admit that benchmarks were always a proxy for what we actually needed: systems we can understand, trust, and build upon. The models are available now on Hugging Face and in the AI2 Playground. The bluff has been called. The rest is up to us.
Try Olmo 3: Hugging Face Collection | AI2 Playground | Technical Report
What do you think? Does full transparency matter more than benchmark scores? Join the discussion.



