Every few months, a model drops that makes you question why you’re still paying per-page API fees for something that runs on a laptop.
NuExtract3 is that model. Numind just released a 4B parameter vision-language model under Apache-2.0 that takes aim at the two biggest pain points in document processing: converting complex layouts into clean Markdown, and extracting structured JSON from messy paperwork. It runs on 4GB of VRAM, ships GGUF and MLX weights on day one, and the Hugging Face demo doesn’t even require a login.
But the real story isn’t the specs. It’s that this model treats reasoning as a dial you can turn up or down, not a fixed cost baked into every call. That changes the economics of document extraction pipelines in ways that most teams haven’t fully registered yet.
The Unified Extractor That Actually Unifies
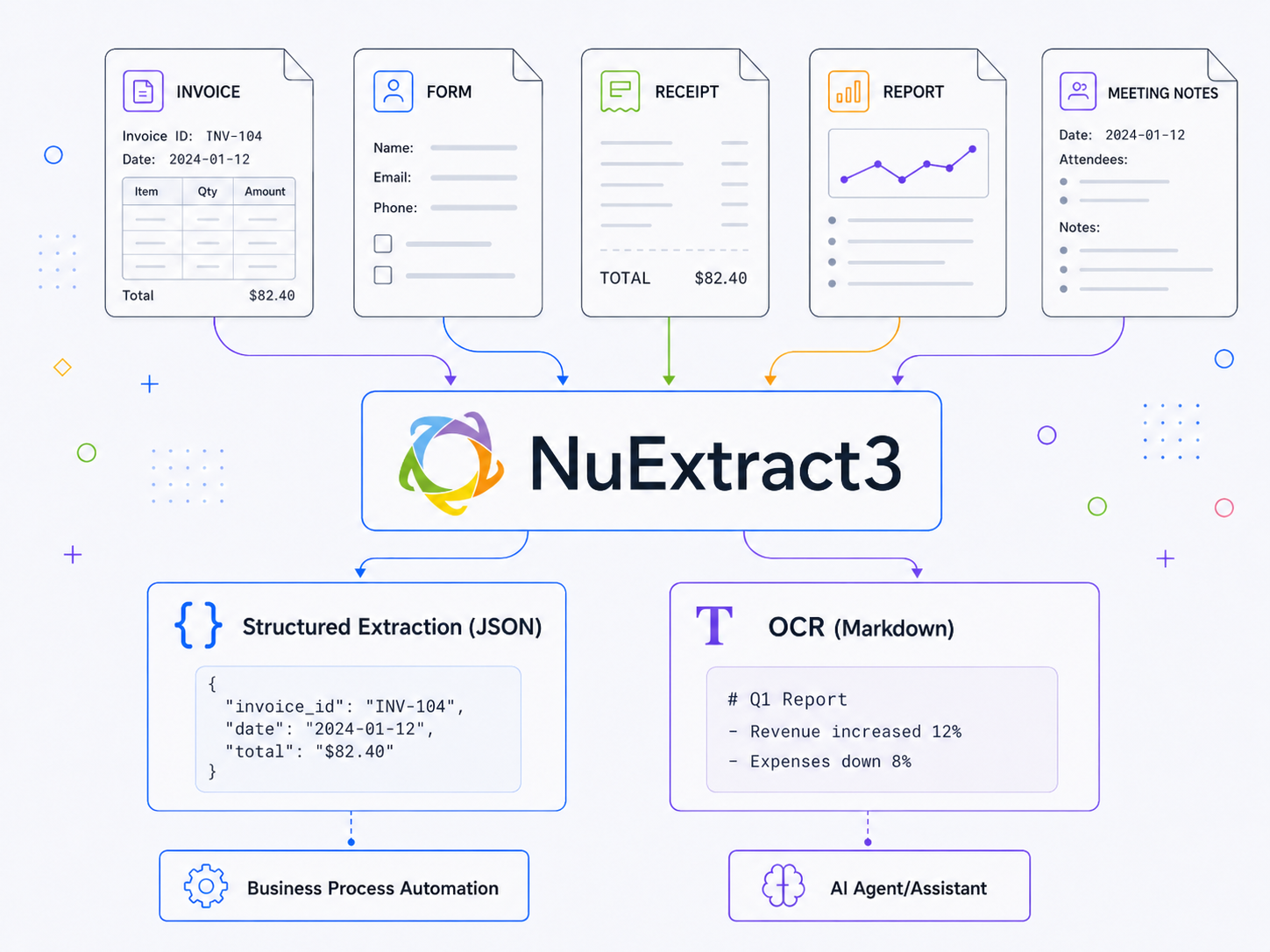
For years, document extraction has meant maintaining two separate pipelines. One for OCR, turning scans and PDFs into readable text. Another for structured extraction, pulling specific fields out of invoices, contracts, and forms into JSON. Different models, different APIs, different billing.
Numind decided this was unnecessary. The core capability driving both tasks is the same: document understanding. So they built a single model that does both, and the benchmark data suggests this wasn’t a compromise.
On their internal structured extraction benchmark, roughly 600 challenging documents including invoices, movie posters, and floor plans, NuExtract3 scored 0.651 on the EXTRA metric (leaf accuracy). That’s over 10 points higher than Gemma 4’s 0.538, and the gap widens dramatically against similarly sized generalist models. Qwen3.5-4B managed 0.417. GLM-4.6V-Flash hit 0.435.
The failures tell an even sharper story. The benchmark recorded “failed” outputs, extractions that weren’t JSON-deserializable, and the small generalist models fell apart. Qwen3.5-4B failed on 229 out of 600 documents. Ministral-3-3B failed on 344. NuExtract3 failed on 27.
This isn’t magic. It’s specialization. A 4B model trained specifically for extraction beats 8B and 9B generalists because it doesn’t waste parameters on everything else.
Reasoning: On-Demand Intelligence Without the Token Tax
Here’s where the model gets interesting. NuExtract3 supports a thinking mode, the model “thinks out loud” about document layout before generating output, much like its predecessor NuMarkdown-Thinking-8B. But the team trained it to use approximately the same number of thinking tokens as output tokens.
This matters because generalist models with reasoning often generate 10x the thinking tokens as output. For a 600-document batch, that difference isn’t academic. It’s the gap between a model that costs pennies to run and one that burns through compute budgets.
The reasoning also improves extraction quality in measurable ways. In an “OCR battle” benchmark using Gemini 3.1 Pro as judge across 150 complex documents, NuExtract3 beat every similarly sized model. The win rate against Qwen3.5-4B wasn’t even close.
But here’s the practical insight: you don’t need reasoning for every document. NuExtract3 lets you toggle it. Default to fast, non-reasoning mode for clean invoices. Engage reasoning only for the nightmare tables, multi-column layouts, and documents where content bleeds across cell boundaries.
What This Means for RAG Pipelines
The most interesting benchmark in their release isn’t about extraction accuracy at all. It’s about measuring OCR quality by how well a downstream LLM can use the output.
They extracted Markdown from 600 documents using various models, then fed those Markdowns to Qwen3.6 27B for structured extraction. NuExtract3’s Markdown outputs enabled the highest downstream performance despite using an average of only 338 thinking tokens. Compare that to Qwen3.5-4B’s average of 6,552 thinking tokens.
For anyone building RAG systems over enterprise documents, PDFs, scans, multi-page contracts, this is the key metric. You don’t care about pixel-perfect layout reproduction. You care about whether the downstream LLM can find the information it needs.
And the model handles tables in a pragmatic way that reflects actual training data distributions: it outputs HTML for tables inside the Markdown, not Markdown table syntax. The reason is straightforward, the base models are trained heavily on HTML, and HTML tables don’t break when a single pipe character gets dropped.
The 4GB VRAM Floor Changes the Deployment Calculus
The model requires as little as 4GB of VRAM with quantization, and Numind shipped multiple quantization formats on day one: GPTQ, W8A8, FP8, Q4, Q6, and MLX variants. The NuExtract3 collection on Hugging Face includes 12 models spanning these variants.
This is the opposite of the “ship the full-precision weights and let the community figure out quantization” approach. It signals that Numind wants this model used in production, not just admired on leaderboards.
The GPU memory requirements aren’t just a deployment convenience. They shape what’s architecturally possible. A model that runs on consumer hardware inside a Docker container can be integrated into pipelines that can’t touch cloud APIs, regulated industries, air-gapped environments, or teams with strict data residency requirements.
This is part of a broader trend where open-weight models are redefining what’s possible with local AI, challenging the assumption that production-grade document processing requires a cloud API key.
Where It Stumbles
The model isn’t flawless. The official team notes that web page extraction isn’t a primary use case, it wasn’t trained extensively on website layouts. For that job, tools like Trafilatura or direct HTML processing remain better options.
Handwriting support exists but isn’t the focus. Users report that complex multi-column newspaper layouts work well with DPI tuning around 150-170, but performance varies with layout density.
And while the 4B parameter count is impressive for running locally, it means the model occasionally hallucinates formatting artifacts that larger models avoid. The instruction-following for freeform instructions isn’t perfect either, the team acknowledges they’re not fully satisfied with how instructions are followed in all cases.
But these are refinements, not deal-breakers. The model already handles in-context examples, supports 20 structured extraction field types including ISO-8601 dates, IBANs, BICs, and ISO currency codes, and can generate extraction templates from natural language descriptions.
The Economic Argument
Run the numbers on any production pipeline processing thousands of documents per week. API-based OCR and structured extraction costs scale linearly with volume. The per-page fees that seem negligible in a demo become real operating expenses.
Now factor in latency. API calls mean network round trips, queuing, and rate limits. A self-hosted model on a single GPU with vLLM handles concurrent requests without the queue.
There’s a growing awareness that open-weight models with transparent licensing represent a fundamentally different value proposition than platform APIs. The gap between “this model costs $X per thousand pages” and “this model costs a fixed GPU that handles unlimited internal pages” widens with every update.
Setting It Up
The Hugging Face model card provides comprehensive documentation for deployment. For vLLM:
vllm serve numind/NuExtract3 \
--trust-remote-code \
--limit-mm-per-prompt '{"image": 99, "video": 0}' \
--chat-template-content-format openai \
--generation-config vllm \
--max-model-len 131072 \
--speculative-config '{"method": "qwen3_next_mtp", "num_speculative_tokens": 2}'
Note the multi-token prediction configuration. MTP can significantly improve decoding throughput without changing the API payload.
For structured extraction from an image:
import json
import base64
from openai import OpenAI
client = OpenAI(api_key="EMPTY", base_url="http://localhost:8000/v1")
template = {
"store": "verbatim-string",
"date": "date-time",
"total": "number",
"payment_method": "verbatim-string"
}
response = client.chat.completions.create(
model="numind/NuExtract3",
temperature=0.2,
messages=[{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{base64_image}"}}
]}],
extra_body={"chat_template_kwargs": {
"template": json.dumps(template, indent=4),
"enable_thinking": False
}}
)
For multi-page PDFs, render each page to PNG using PyMuPDF at 170 DPI, then pass the images in page order. The model supports up to 99 images per request.
The vLLM deployment with MTP and 131K context length handles most real-world document workloads without splitting. For maximum parallelism on Markdown extraction, go page by page.
The model also supports template generation from natural language, you can feed it “I want to extract the key details from a rental contract” and get back a structured extraction template.
The Bottom Line
NuExtract3 is the first model that makes it genuinely practical to self-host both OCR and structured extraction with reasoning that doesn’t cost 10x the output tokens. The benchmarks are credible. The deployment options are comprehensive. The license is Apache-2.0.
For teams processing documents at scale, the calculus is straightforward: a fixed hardware cost that handles unlimited internal volume versus per-request API costs. The break-even point keeps getting lower, and this model just moved it significantly.
The era of paying per-page for document extraction is ending. NuExtract3 is the latest and most capable argument for why.