
Norway is building a large language model (LLM) that actually understands Norwegian, its two written forms, its dialects, its cultural history. The Ministry of Culture didn’t task a startup or a hyperscaler with this. It gave the job to the National Library (Nasjonalbiblioteket), an institution that has been quietly digitizing every book, newspaper, and broadcast in the country since 2005.
The technical challenge? Moving 20 petabytes of unique cultural data through an AI pipeline fast enough to feed a national supercomputer. The controversial twist? They chose 2 petabytes of Huawei OceanStor Dorado all-flash arrays to do it.
This isn’t just a storage procurement story. It’s a window into how sovereign AI is being built outside the US-China binary, what happens when archive-grade data meets training-grade I/O requirements, and why a library’s legal deposit mandate might be the most underrated AI training advantage on the planet.
The Dataset No Private Company Has
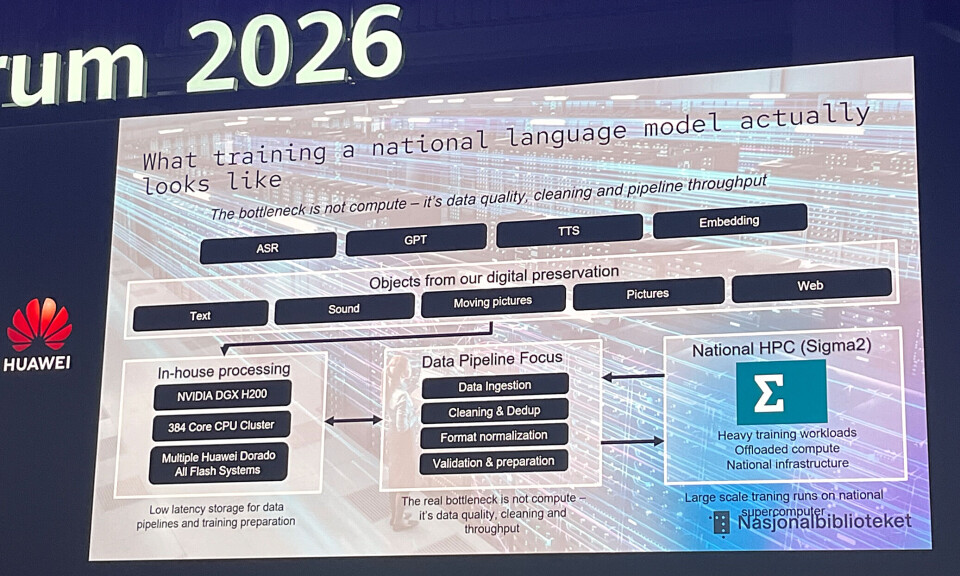
Marius Husnes, the Head of IT Platform at the National Library, outlined the project at Huawei’s ID Forum 2026 in Paris. The library’s digitization efforts have produced 20 PB of unique data, Norwegian books, newspapers, web pages, sound recordings, moving pictures, still images. Because the library operates under a legal deposit mandate, it receives copies of every published work and broadcast. An agreement with Norwegian newspapers permitted LLM training on copyrighted content. As Husnes put it: “No private company has this.”
That 20 PB is stored in a 3-2-1 configuration (3 copies, 2 media types, 1 off-site), totaling roughly 60 PB of preservation-grade storage. This is a digital disk-plus-tape archive optimized for durability and cost. Read latency is high. It was never designed for AI workloads.

The bottleneck wasn’t compute. Husnes explicitly stated that data quality, cleaning, and pipeline throughput were the constraints. This is a lesson that scales: raw archival capacity is cheap. Fast, parallel, low-latency access to that data at petabyte scale is a completely different problem.
The Two-Tier Storage Architecture
Tier 1: The Preservation Archive (60 PB)
- Disk + tape backend, optimized for infrequent access and long-term durability
- High read latency by design
- Serves as the single source of truth for all digitized cultural content
Tier 2: The AI Pipeline Storage (2 PB)
- Multiple Huawei OceanStor Dorado all-flash arrays
- Connected to an Nvidia DGX H200 system and a 384-core CPU cluster
- Designed for high-throughput, low-latency, parallel data I/O
The pipeline stages between them include data ingestion, cleaning, deduplication, format normalization, validation, and preparation. Once data passes through, it’s sent to Norway’s national supercomputer, the Sigma2 Olivia system, for actual training runs. Olivia is an HPE Cray Supercomputing EX system with 448 GPUs and 64,512 CPU cores, backed by a 5.3 PB Cray ClusterStor E1000 storage system.
Husnes admitted that nobody was talking about the problems involved in moving PB-scale datasets from an archive to, and through, an AI data pipeline. His team had to figure it out themselves. That’s a gap in the industry’s collective knowledge that every non-English-speaking nation building a sovereign LLM will eventually face.
Why Huawei, and Why That Matters Now
The National Library’s choice of Huawei OceanStor Dorado arrays wasn’t made in a vacuum. The timing coincides with Huawei’s aggressive push into high-density, high-performance storage for AI workloads. Just days before this announcement, Huawei showcased 61.44 TB and 122.88 TB SSDs using Die-on-Board (DoB) packaging technology at the same ID Forum 2026 event.
The significance of DoB is that it’s an engineering response to a geopolitical restriction. Being on the U.S. Entity List since 2019 limits Huawei’s access to the most advanced 3D NAND from international suppliers. DoB allows them to pack more domestic NAND dies (likely from YMTC) directly onto the PCB, achieving a 33% capacity density improvement without requiring bleeding-edge NAND layers.
| Product/Data | Capacity | Technology |
|---|---|---|
| Huawei DoB SSD (current) | 61.44 TB | NAND with Die-on-Board |
| Huawei DoB SSD (current) | 122.88 TB | NAND with Die-on-Board |
| Future SSD (roadmap) | 245 TB | Planned |
| OceanDisk 1800 | 1.47 PB in 2U | DoB stacking |
| OceanDisk 1610 | 2.2 PB in 2U (36 x 61.44 TB) | DoB stacking |
| OceanStor Pacific 9926 | 4.42 PB gross in 2U (36 x 122.88 TB) | NVMe PCIe 5 |
For context, Kioxia has demonstrated 245.76 TB SSDs in E3.L format, and Micron has shown 245 TB units for data centers. Huawei hasn’t matched that top-end capacity yet, but the gap is narrowing through packaging innovation rather than NAND layer advancement.
This matters for Norway’s architecture because it’s not a trivial procurement decision to bet a national AI infrastructure project on a vendor under active sanctions. The state-sponsored AI and geopolitical cybersecurity risks are real. Yet Norway chose Huawei. The question is whether that decision reflects technical merit, lack of alternatives in the European market, or a calculated geopolitical hedge.
The Three Ongoing Problems Norway Is Solving in Real-Time
1. Evaluation
There are no standard evaluation tools for a Norwegian LLM. The language has two written forms (Bokmål and Nynorsk), multiple dialects, and historical changes that LLM benchmarks don’t capture. The team is building their own evaluation framework from scratch.
2. Governance
Who controls access to a sovereign LLM? Who decides what it can be used for? The National Library isn’t a commercial entity, and these questions become institutional and political. The Norwegian government will have to decide whether this model is open, restricted to public institutions, or made available to private companies.
3. Orchestration
Three systems, the preservation archive, the on-prem AI environment (Huawei + DGX), and the national Sigma2 supercomputer, need to work together smoothly. That’s a distributed data flow problem that most organizations struggle with at orders of magnitude smaller scale.
These aren’t technical edge cases. They’re the core challenges of building AI that reflects a non-English language, culture, and history. Husnes framed it directly: Norway is a small country solving a problem every non-English-speaking nation will face. AI needs custodians, not just builders.
What This Means for Sovereign AI Infrastructure
The broader pattern here is that countries are starting to treat LLMs as national infrastructure, not just commercial products. South Korea’s Upstage recently dropped the Solar-Open-100B model, trained on government GPUs. China’s DeepSeek is driving cost optimization and pricing pressures in AI infrastructure that force every builder to think about efficiency.
Norway’s approach is unique because it leverages a pre-existing national asset, the library’s digitization mandate, as the foundation for AI training data. No private company in Norway has a dataset that matches the library’s breadth, depth, or legal clearance for copyrighted material.

But the architecture itself is instructive. The separation of preservation storage (slow, cheap, durable) from pipeline storage (fast, expensive, low-latency) is the right pattern for any organization that wants to train models on historical data without rebuilding their archive. The bottleneck isn’t whether you have enough data. It’s whether you can get that data through a pipeline fast enough to keep your GPU cluster fed.
The geopolitical dimension adds another layer. Huawei’s DoB packaging is a fascinating example of how sanctions drive innovation in unexpected places. By forcing a redesign of SSD packaging, U.S. restrictions may have inadvertently accelerated China’s development of alternative integration strategies. Whether those strategies produce reliable, cost-competitive products for AI data centers remains to be seen. But Norway is betting real infrastructure dollars on that bet.
The Bottom Line
The National Library’s project is a case study in how to build sovereign AI when you’re not a superpower. Start with a unique dataset that no one else has. Separate your archive from your pipeline. Be prepared to build evaluation tools from scratch. And don’t expect vendors to solve your orchestration problems for you.
The controversy over using Huawei storage in a government AI project will continue, especially as state-sponsored AI infrastructure and geopolitical competition in AI development intensifies. But the technical challenges Husnes described, moving PB-scale data through a pipeline, managing three disparate systems, evaluating a model for a language with no benchmarks, are universal.
Every country with a distinct language, a cultural archive, and the ambition to build AI that reflects its own identity will face these same questions. Norway is writing the playbook in real-time. The rest of the world should be reading it.
