Google’s TranslateGemma Proves That Size Doesn’t Matter: 12B Parameters Beat 27B
Google just dropped a bombshell on the machine translation world, and it’s not what you’d expect. While the AI industry obsesses over trillion-parameter models and massive data centers, TranslateGemma flips the script entirely. A 12-billion parameter model beating a 27-billion parameter counterpart? That’s not supposed to happen in a world where scaling laws reign supreme.

The numbers don’t lie: TranslateGemma’s 12B variant scores 3.60 on MetricX (lower is better) compared to the Gemma 3 27B baseline’s 4.04. That’s not a rounding error, it’s a fundamental challenge to the assumption that bigger models automatically deliver better results. For developers watching their cloud bills spiral, this is the kind of heresy worth celebrating.
The Efficiency Revolution in Translation
TranslateGemma isn’t just another open model release. It’s a family of three models, 4B, 12B, and 27B parameters, built on the Gemma 3 architecture but fine-tuned specifically for translation across 55 languages. What makes this release genuinely disruptive is Google’s explicit design goal: these models run on hardware you already own.
The 4B model targets mobile devices and edge deployment. The 12B variant slides comfortably onto consumer laptops. Even the 27B heavyweight runs on a single H100 GPU or TPU, not a server farm. This democratization of high-quality translation represents a stark contrast to the increasingly closed, API-only approach of competitors like OpenAI and Anthropic.
The performance gains extend across the board, but low-resource languages see the most dramatic improvements. English-Icelandic translation error rates plummeted over 30%, while English-Swahili improved by roughly 25%. This isn’t just academic benchmarking, it’s addressing the long-tail of languages that proprietary services have historically neglected.
Distilling Gemini’s Brain Into a Smaller Skull
So how did Google achieve this apparent magic? The secret sauce is a two-stage training process that essentially distills the “intuition” from their flagship Gemini models into the more compact Gemma architecture.
Crucially, the training mix includes 30% general instruction data, which means these specialized translation models retain broader conversational abilities. You can still use them as chatbots, they haven’t been lobotomized into single-purpose tools.
Benchmarks That Actually Matter
The WMT24++ benchmark, covering 55 language pairs across seven language families, tells a compelling story. The 12B TranslateGemma not only beats the 27B Gemma 3 baseline but does so consistently across every language family tested. The bar chart reveals lower error rates across Germanic, Romance, Slavic, and other language groups.

The 4B model’s performance is equally impressive, rivaling the larger 12B baseline with a ~26% error rate reduction. For mobile developers, this means production-quality translation without burning through device battery or requiring constant cloud connectivity.
Human evaluation by professional translators largely confirmed the automated metrics, with one notable exception: Japanese-to-English translations showed a decline that Google attributes to proper name handling issues. It’s a reminder that even sophisticated benchmarks have blind spots.
Multimodal Capabilities That Shouldn’t Exist (But Do)
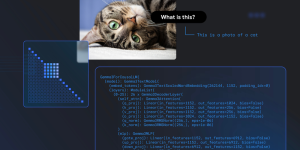
Here’s where things get weird. TranslateGemma models retain Gemma 3’s multimodal abilities despite receiving no specific multimodal fine-tuning during translation training. The models can extract and translate text from images, performing surprisingly well on the Vistra image translation benchmark.
The image processing pipeline normalizes inputs to 896×896 resolution and encodes them to 256 tokens, fitting within the 2K token context window. This means you can point your phone at a street sign in Prague and get a German translation without any specialized computer vision pipeline.
This emergent capability suggests that translation quality improvements generalize across modalities, a finding that could reshape how we think about task-specific fine-tuning. The specialization didn’t come at the cost of versatility, which defies conventional wisdom about narrow versus general AI systems.
The Developer Community’s Reality Check
The reaction from practitioners has been predictably pragmatic. On hardware-constrained environments, the excitement is palpable, finally, a state-of-the-art translation model that won’t choke an “ancient laptop.” The 4B model’s accessibility opens doors for offline translation apps, privacy-focused solutions, and deployment in regions with limited connectivity.
Comparisons to DeepL emerged immediately. One developer noted that even the standard Gemma 3 27B instruct model delivers “decent German and acceptable Czech”, leading to the logical conclusion that TranslateGemma’s specialized variants should perform even better. The question on everyone’s mind: how does this stack up against the reigning champion of machine translation?
Google’s own positioning is careful. They claim “superior performance to other, comparably-sized open model alternatives”, a statement that sidesteps direct comparison with proprietary services. But the subtext is clear: this isn’t just about beating other open models, it’s about providing a credible alternative to closed APIs.
The Open Weights Strategy vs. Closed APIs
TranslateGemma arrives at a pivotal moment in the AI landscape. While OpenAI quietly launched ChatGPT Translate and Anthropic doubles down on closed systems, Google is flooding the market with capable open weights models. The Gemma family now includes MedGemma, FunctionGemma, and now TranslateGemma, each targeting specific use cases.
The licensing reflects this strategic positioning. Under the Gemma Terms of Use, you can use these models commercially, modify them, and redistribute them. But you’re bound by Google’s Prohibited Use Policy, and you must pass along the same terms. It’s “open weights”, not open source in the traditional sense, a nuanced but important distinction that gives Google control while fostering community adoption.
This approach directly counters the rise of Chinese open models from Alibaba (Qwen), Baidu, and Deepseek, which have captured significant market share. It’s also a hedge against regulatory pressure: open models are easier to audit, safer to deploy locally, and align with data sovereignty requirements.
Implementation: Code That Actually Works
For developers ready to experiment, the API is refreshingly straightforward. The models use a strict chat template requiring source and target language codes in ISO 639-1 format. Here’s the pattern:
from transformers import pipeline
import torch
pipe = pipeline(
"image-text-to-text",
model="google/translategemma-12b-it",
device="cuda",
dtype=torch.bfloat16
)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"source_lang_code": "cs",
"target_lang_code": "de-DE",
"text": "V nejhorším případě i k prasknutí čočky.",
}
],
}
]
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"][-1]["content"])The template is opinionated, it accepts only one content entry, requires explicit language codes, and supports both text and image inputs. This rigidity prevents common prompting errors but demands careful integration.
For image translation, simply swap the type to “image” and provide a URL or local path. The model handles text extraction and translation in a single forward pass, a capability that would typically require chaining OCR and translation models.
The Elephant in the Room: Real-World Quality
Google’s benchmarks are impressive, but professional translators remain skeptical. The Japanese-to-English quality decline highlights a critical weakness: proper noun handling. For enterprise use cases, legal documents, medical records, technical manuals, these edge cases matter more than average benchmark scores.
The models also inherit Gemma 3’s limitations. They can generate incorrect factual statements, struggle with nuance and sarcasm, and reflect biases present in training data. Google’s red-teaming showed “major improvements” in safety categories compared to previous Gemma models, but translation-specific risks like hallucinated text or culturally inappropriate renderings remain.
For low-resource languages, the quality gains are undeniable. But for high-resource pairs like English-German or English-French, the improvement over existing solutions may be incremental rather than revolutionary. The real win is accessibility: you can now run these models locally, ensuring data privacy and offline capability.
Why This Changes the Game
TranslateGemma matters because it challenges two fundamental assumptions in AI development. First, that specialization requires sacrificing generality. Second, that state-of-the-art performance demands massive infrastructure.
The efficiency breakthrough suggests we’ve been approaching model design backward. Instead of training ever-larger generalists and hoping for emergent capabilities, Google is showing that targeted fine-tuning of smaller base models can yield superior results for specific tasks. It’s a more principled, less wasteful approach to AI development.
For the translation industry, this is both opportunity and threat. Agencies can deploy custom-tuned models for client-specific terminology. Individual translators can use local models for confidentiality. But the economic moat around high-quality translation services just got significantly narrower.
The broader implication is clear: the future belongs to efficient, specialized models that run where you need them, not just where the cloud providers want you to run them. Google’s bet on open weights isn’t altruism, it’s a strategic move to commoditize the translation layer while building an ecosystem around their tooling.
Whether that ecosystem thrives depends on community adoption. The models are available now on Hugging Face, Kaggle, and through Vertex AI. The technical report provides the full list of nearly 500 language pairs in the extended training set, inviting researchers to push boundaries further.
The translation wars just got a lot more interesting. And a lot more local.